本文主要是介绍2.Hive表结构变更时,滥用MSCK REPAIR TABLE语句,导致变更语句执行时间过长,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.分析原因
很多人可能都知道这个语句是用来修复分区的,但具体修复了什么,就说不上来了。
2.解决办法
搞清楚这个命令的作用就不会滥用了。
3.实战演习
(1)查看官方文档
(a)从这一段说明可以看出,元数据中存储着一个关于分区的列表,如果通过hadoop 命令或者其他方式(非hive命令)在hdfs上添加了分区,元数据库并不能自动感知到分区的修改。
Recover Partitions (MSCK REPAIR TABLE)Hive stores a list of partitions for each table in its metastore. If,
however, new partitions are directly added to HDFS (say by using hadoop
fs -put command) or removed from HDFS, the metastore (and hence Hive)
will not be aware of these changes to partition information unless the
user runs ALTER TABLE table_name ADD/DROP PARTITION commands on each
of the newly added or removed partitions, respectively.恢复分区(MSCK REPAIR TABLE) Hive在它的元存储中为每个表存储一个分区列表。 如果, 然而,新的分区直接添
加到HDFS(比如使用hadoop fs -put命令)或从HDFS中删除,这些分区信息不会被元存
储感知到,除非用户在每个新添加或删除的分区上分别运行ALTER TABLE table_name
ADD/DROP PARTITION命令。 (b)从这一段可以看出,这个命令的默认选项是ADD,可以自动更新添加的分区信息到元数据库中,选择DROP选项,可以自动更新删除的分区信息到元数据库中,选择SYNC选项,相当于调用了ADD和DROP这两个选项。
However, users can run a metastore check command with the repair table
option:MSCK [REPAIR] TABLE table_name [ADD/DROP/SYNC PARTITIONS];which will update metadata about partitions to the Hive metastore for
partitions for which such metadata doesn't already exist. The default
option for MSC command is ADD PARTITIONS. With this option, it will addany partitions that exist on HDFS but not in metastore to the metastore.
The DROP PARTITIONS option will remove the partition information from
metastore, that is already removed from HDFS. The SYNC PARTITIONS option
is equivalent to calling both ADD and DROP PARTITIONS. See HIVE-874 and
HIVE-17824 for more details. When there is a large number of untracked
partitions, there is a provision to run MSCK REPAIR TABLE batch wise to
avoid OOME (Out of Memory Error). By giving the configured batch size for
the property hive.msck.repair.batch.size it can run in the batches
internally. The default value of the property is zero, it means it will
execute all the partitions at once. MSCK command without the REPAIR option
can be used to find details about metadata mismatch metastore.但是,用户可以使用repair table选项运行metastore检查命令:MSCK [REPAIR] TABLE table_name [ADD/DROP/SYNC PARTITIONS];对于这些元数据还不存在的分区,它将更新关于分区的元数据到Hive元存储。
MSC命令的默认选项是ADD PARTITIONS。有了这个选项,它将把HDFS上存在但不在
元存储中的任何分区添加到元存储中。DROP PARTITIONS选项将从metastore中删除
已经从HDFS中删除的分区信息。SYNC PARTITIONS选项相当于同时调用这两个选项。
查看HIVE-874和HIVE-17824获取更多细节。当存在大量未跟踪的分区时,可以通过
批量运行MSCK REPAIR TABLE来避免OOME(内存不足错误)。通过为属性hive.msck
.repair.batch.size提供配置的批处理大小,它可以在内部运行批处理。该属性的
默认值为零,这意味着它将一次性执行所有分区。不带REPAIR选项的MSCK命令可以
用于查找元数据不匹配的元存储的详细信息。(2)演示效果
(a)使用默认选项(ADD),另外另个选项类似,可以自行实验
step1:建一张表,并通过hive命令添加一个分区,并查看分区情况
CREATE TABLE IF NOT EXISTS test.test
(id INT,name STRING,gender STRING
)
PARTITIONED BY (pt_d STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
;ALTER TABLE test.test ADD PARTITION(pt_d = '20211102');SHOW PARTITIONS test.test;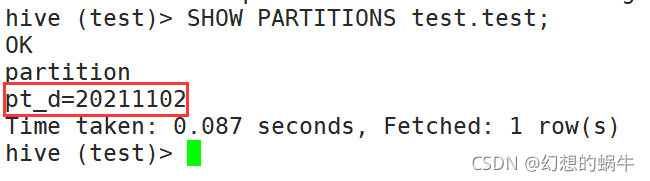
step2:通过hadoop命令和其他方式创建分区 ,可以
hadoop fs -mkdir hdfs://hadoop01:9000/user/hive/warehouse/test.db/test/pt_d=20211101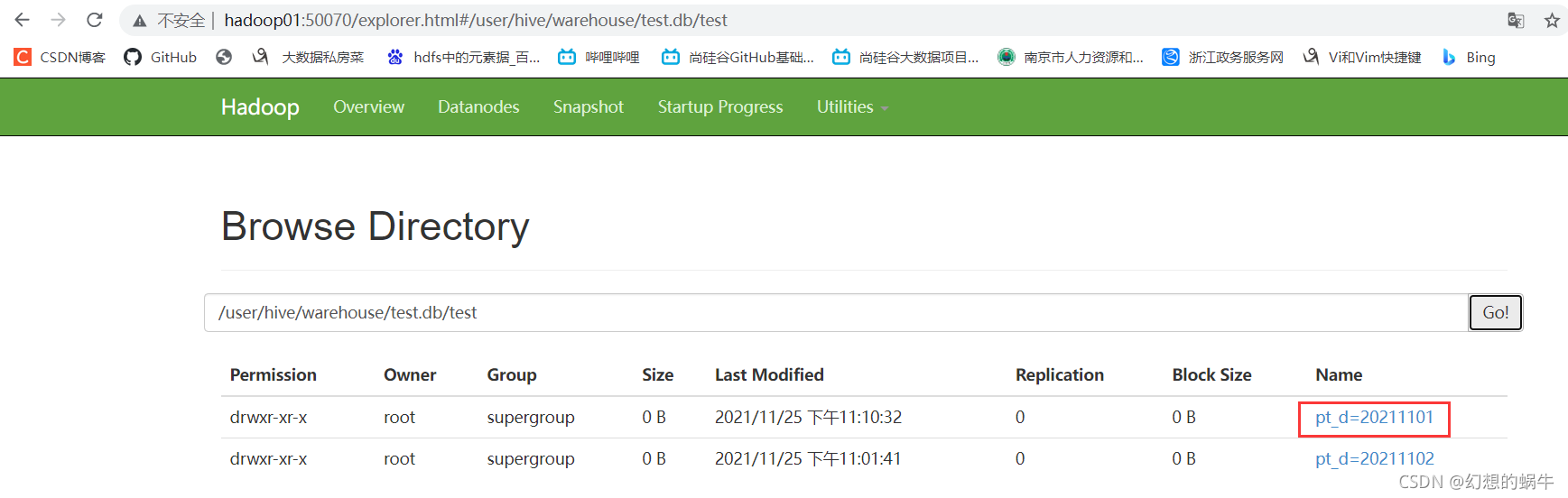
step3:查看分区的元数据信息
SHOW PARTITIONS test.test;
step4:使用msck repair命令后查看分区的元数据信息 ,可以看到,使用命令后,元数据信息已经更新。
MSCK REPAIR TABLE test.test;SHOW PARTITIONS test.test;
4.总结
MSCK命令只有一个作用,就是来检测通过非hive命令的方式添加或者删除分区的情况,添加分区的会将元数据写入到元数据库中,删除分区的会将对应的元数据信息删除。
这篇关于2.Hive表结构变更时,滥用MSCK REPAIR TABLE语句,导致变更语句执行时间过长的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





