本文主要是介绍HiveSQL题——数据炸裂和数据合并,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、数据炸裂
0 问题描述
1 数据准备
2 数据分析
3 小结
二、数据合并
0 问题描述
1 数据准备
2 数据分析
3 小结
一、数据炸裂
0 问题描述
如何将字符串1-5,16,11-13,9" 扩展成 "1,2,3,4,5,16,11,12,13,9" 且顺序不变。
1 数据准备
with data as (select '1-5,16,11-13,9' as a)2 数据分析
步骤一:explode(split(a, ',')) 炸裂 + row_number()排序,一行变多行,且对每行的数据排序,保证有序性。
with data as (select '1-5,16,11-13,9' as a)
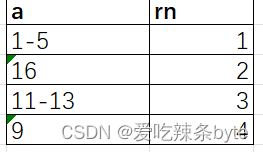
selecta,row_number() over () as rn
from (selectexplode(split(a, ',')) as afrom data)tmp1;输出结果:
步骤二: lateral view explode(split(a, '-')) 、max(b) - min(b) as diff
(1)lateral view +explode 侧写和炸裂,一行变多行,并将源表中每行的输出结果与该行连接;
(2)group by a, rn ....... select min(b) as start_index 得到每个分组的起始值
(3)max(b) - min(b) 得到每个分组的步长
with data as (select '1-5,16,11-13,9' as a)
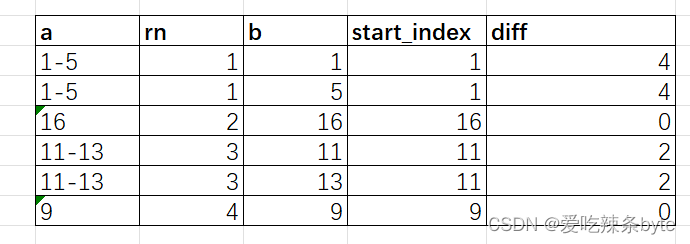
selecta,rn,min(b) as start_data,max(b) - min(b) as diff
from (selecta,rn,bfrom (selecta,row_number() over () as rnfrom (selectexplode(split(a, ',')) as afrom data) tmp1) tmp2lateral view explode(split(a, '-')) table1 as b) tmp3
group by a, rn;输出结果是:
步骤三: 根据步长生成索引值,起始值加上索引值获取展开值
(1) lateral view posexplode(split(space(cast (diff as int)), '')) table1 as pos, item;
侧写和炸裂,根据分组的步长 diff 生成对应的索引值pos
(2)(start_data + pos) as str,起始值加上索引值获取展开值
with data as (select '1-5,16,11-13,9' as a)
selecta,rn,cast ((start_data + pos) as int) as str
from (selecta,rn,start_index,diff,posfrom (selecta,rn,min(b) as start_data,max(b) - min(b) as difffrom (selecta,rn,bfrom (selecta,row_number() over () as rnfrom (selectexplode(split(a, ',')) as afrom data) tmp1) tmp2lateral view explode(split(a, '-')) table1 as b) tmp3group by a, rn) tmp4lateral view posexplode(split(space(cast(diff as int)), '')) table1 as pos, val) tmp5order by rn;输出结果是:

步骤四: 对a,rn, diff 字段分组,拼接str字符串得到最终结果值
with data as (select '1-5,16,11-13,9' as a)
selectconcat_ws(',', collect_set(cast(str as string))) as result
from (selecta,rn,cast((start_index + pos) as int) as strfrom (selecta,rn,start_index,diff,posfrom (selecta,rn,min(b) as start_index,max(b) - min(b) as difffrom (selecta,rn,bfrom (selecta,row_number() over () as rnfrom (selectexplode(split(a, ',')) as afrom data) tmp1) tmp2lateral view explode(split(a, '-')) table1 as b) tmp3group by a, rn) tmp4lateral view posexplode(split(space(cast(diff as int)), '')) table1 as pos, val) tmp5) tmp6
group by a,rn,diff;最终的输出结果:1,2,3,4,5,16,11,12,13,9
3 小结
数据炸裂的思路一般是:1.计算区间【a,b】的步长(差值)diff;2.利用split分割函数+ posexplode等 将一行变成 diff+1 行,生成对应的下角标pos(pos的取值为【0,diff】);3.【a,b】区间的起始值 (a + pos) 将数据平铺开;4.基于平铺开后的数据集进一步加工处理,例如:分组聚合等。二、数据合并
0 问题描述
面试题:基于A表的数据生成B表数据

1 数据准备
create table if not exists tableA
(id string comment '用户id',name string comment '用户姓名'
) comment 'A表';insert overwrite table tableA values('1','aa'),('2','aa'),('3','aa'),('4','d'),('5','c'),('6','aa'),('7','aa'),('8','e'),('9','f'),('10','g');create table if not exists tableC
(id string comment '用户id',name string comment '用户姓名'
) comment 'C表';insert overwrite table tableC values('3','aa|aa|aa'),('4','d'),('5','c'),('7','aa|aa'),('8','e'),('9','f'),('10','g');
2 数据分析
步骤1:寻找满足条件的断点
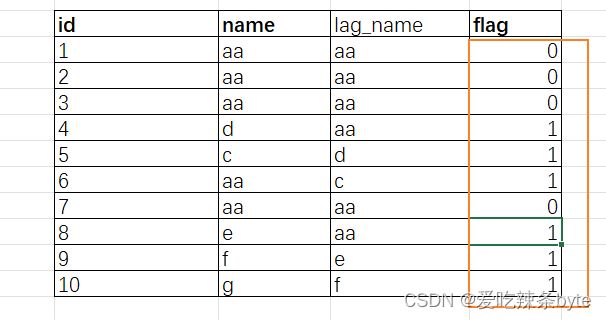
selectid,name,if(name != lag_name, 1, 0) as flag
from (selectid,name,lag(name, 1, name) over (order by cast(id as int)) as lag_namefrom tableA) tmp1;输出结果为:
步骤2:断点处标记为1,非断点处标记为0,并对断点标记值进行累加,构造分组标签
selectid,name,--并对断点标记值进行累加,构造分组标签sum(flag) over (order by cast(id as int)) grp
from (selectid,name,--断点处标记为1,非断点处标记为0if(name != lag_name, 1, 0) flagfrom (selectid,name,lag(name, 1, name) over (order by cast(id as int)) as lag_namefrom tableA) tmp1) tmp2;输出结果为:

步骤3:按照分组标签进行数据合并,并取得分组中最大值作为id
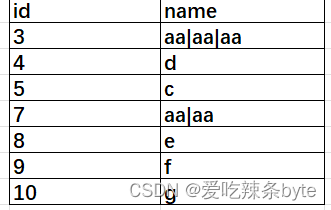
selectmax_id,
-- collect_list 数据聚合并拼接concat_wsconcat_ws('|', collect_list(name)) as name
from (selectname,grp,max(id) over (partition by grp) max_idfrom (selectid,name,sum(if(name != lag_name, 1, 0)) over (order by cast(id as int)) as grpfrom (selectid,name,lag(name, 1, name) over (order by cast(id as int)) as lag_namefrom tableA) tmp1) tmp2) tmp3
group by max_id, grp;输出结果为:

通过max_id, grp分组,对name进行 concat_ws('|', collect_list(name)) 聚合拼接,得出最终的结果
3 小结
断点分组问题的算法总结步骤1:寻找满足条件的断点步骤2:断点处标记值为1,非断点处标记为0步骤3:对断点标记值进行累加 sum(xx)over(order by xx),构造分组标签步骤4:按照分组标签进行分组求解问题
这篇关于HiveSQL题——数据炸裂和数据合并的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





