本文主要是介绍第六章 数据持久化及高频面试题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、数据持久化
官网文档地址:https://redis.io/docs/management/persistence/
Redis提供了主要提供了 2 种不同形式的持久化方式:
-
RDB(Redis数据库):RDB 持久性以指定的时间间隔执行数据集的时间点快照。
-
AOF(Append Only File):AOF 持久化记录服务器接收到的每个写操作,在服务器启动时再次播放,重建原始数据集。 命令使用与 Redis 协议本身相同的格式以仅附加方式记录。 当日志变得太大时,Redis 能够在后台重写日志。
1.1 RDB
1.1.1 什么是 RDB
在指定的时间间隔内将内存中的数据集快照写入磁盘, 也就是Snapshot快照,它恢复时是将快照文件直接读到内存里。
1.1.2 如何备份
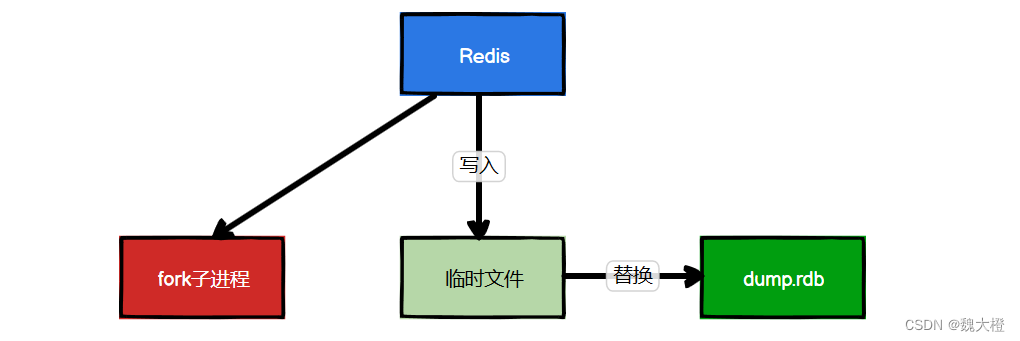
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到 一个临时文件中,待持久化过程都结束后,再用这个临时文件替换上次持久化好的文件。主进程不进行任何的IO操作,这样就保证了较高的性能。如果需要进行大规模数据的恢复,并且对于数据恢复的不完整性非常敏感,那么RDB方式会比AOF方式更加高效。注意点:最后一次持久化后的数据可能丢失。
1.1.3 Fork
Fork的作用是复制一个与当前进程一样的进程,且新进程内的所有数据(变量,环境变量,程序计数器等等)数值都和原进程一直,但它是一个全新的进程,并且作为原进程的子进程。
在 Linux 程序中,fork() 会产生一个和父进程完全相同的子进程,但子进程在此后多会 exec 系统调用,出于效率考虑,Linux 中引入了“写时复制技术”。
一般情况下,父进程和子进程会共用一段物理内存,只有进程空间的各段内容发生变化时,才会将父进程的内容复制一份给子进程。
6.1.1.4 备份和恢复
#dump.rdb存放在两个位置上
1、root\ 目录 =====>通过正常的启动和关闭所保存的地址
2、var\lib\redis\ 目录 =====>通过 systemctl restart redis 命令所生成的
我们如果要进行备份还原的实验的话,确定目标地址,并选择适配的命令去观察变化
#步骤1:清空数据库
FLUSHALL
#步骤2:
客户端退出 exit
服务器关闭 ctrl+c
#步骤3:观察root\ 内的dump.rdb文件大小 发现是 92
#步骤4:正常启动redis并登录客户端
服务器启动 redis-server
客户端登录 redis-cli
#步骤5:保存了六组信息
set k1 v1
.......
set k6 v6
#步骤7:
客户端退出 exit
服务器关闭 ctrl+c
#步骤8:观察root\ 内的dump.rdb文件大小 发现是 139
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
#步骤9 将139大小的dump.rdb复制 命名为 dump.rdb.back
cp dump.rdb dump.rdb.back
#步骤10 删除dump.rdb
rm -f dump.rdb
#步骤11:正常启动redis并登录客户端,查看数据
服务器启动 redis-server
客户端登录 redis-cli
客户端查看 keys * ======================> 数据没有了
#步骤12
客户端退出 exit
服务器关闭 ctrl+c
#步骤13:观察root\ 内的dump.rdb文件大小 发现是 92
#步骤14:将139大小的dump.rdb.back复制 命名为 dump.rdb
#步骤15:正常启动redis并登录客户端,查看数据
服务器启动 redis-server
客户端登录 redis-cli
客户端查看 keys * ======================> 数据存在1.2 AOF
1.2.1 什么是AOF
以日志的形式来记录每个写操作(增量保存),将Redis执行过的所有写指令记录下来(读操作不记录), 只追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据。简单说,Redis 重启时会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
在Redis的默认配置中AOF(Append Only File)持久化机制是没有开启的,要想使用AOF持久化需要先开启此功能。AOF持久化会将被执行的写命令写到AOF文件末尾,以此来记录数据发生的变化,因此只要Redis从头到尾执行一次AOF文件所包含的所有写命令,就可以恢复AOF文件的记录的数据集。
1.2.2 持久化流程

- 客户端的请求写命令会被append追加到AOF缓冲器内。
- AOF缓冲区根据AOF持久化策略,将sync同步到磁盘的AOF文件中
- AOF文件大小超过了重写策略或手动重写时,会对AOF文件进行重写,以压缩AOF文件容量
- Redis服务重启时,会重新load加载AOF文件中的写操作,已达到数据恢复的目的。
1.2.3 备份和恢复
#步骤1 开启AOF
修改 redis.conf 配置文件:
- 通过修改redis.conf配置中`appendonly yes`来开启AOF持久化
- 通过appendfilename指定日志文件名字(默认为appendonly.aof)
- 通过appendfsync指定日志记录频率| 选项 | 同步频率 |
|---|---|
| always | 每个redis写命令都要同步写入硬盘,严重降低redis速度 |
| everysec | 每秒执行一次同步显式的将多个写命令同步到磁盘 |
| no | 由操作系统决定何时同步 |
#步骤2 重启服务以确保配置文件被重新读过
systemctl restart redis
#步骤3 在var/lib/redis目录内找到了 appendonly.aof
#步骤4:登录客户端并保存数据
客户端登录 redis-cli
#步骤5:保存了六组信息
set k1 v1
.......
set k6 v6
#步骤6:基于客户端关闭连接和服务
SHUTDOWN
#步骤7:在var/lib/redis目录内找到了 appendonly.aof (大小由0变成了一组数值)
#步骤8:复制appendonly.aof
cp appendonly.aof appendonly.aof.back
#步骤9:重启服务连接客户端
systemctl restart redis
客户端登录 redis-cli
#步骤10:清空数据库并停止服务
FLUSHDB
SHUTDOWN
#步骤11:在var/lib/redis目录内找到了 appendonly.aof (大小由一组数值变成了另一组数值 后数值>前数值)
#步骤12:复制appendonly.aof.back
cp appendonly.aof.back appendonly.aof
#步骤13:重启服务连接客户端
systemctl restart redis
客户端登录 redis-cli
#步骤14:检查数据
keys *1.3 如何选择
那么,在开发中是选择 RDB 还是选择 AOF 来持久化呢?
官网建议如下:
Ok, so what should I use?
The general indication you should use both persistence methods is if you want a degree of data safety comparable to what PostgreSQL can provide you.
If you care a lot about your data, but still can live with a few minutes of data loss in case of disasters, you can simply use RDB alone.
There are many users using AOF alone, but we discourage it since to have an RDB snapshot from time to time is a great idea for doing database backups, for faster restarts, and in the event of bugs in the AOF engine.
The following sections will illustrate a few more details about the two persistence models.
-
RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储
-
AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.
-
Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大
-
只做缓存:如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式.
-
同时开启两种持久化方式
-
在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据, 因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整.
-
RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。那要不要只使用AOF呢?
-
建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份), 快速重启,而且不会有AOF可能潜在的bug,留着作为一个万一的手段。
2、高频面试题
2.1 缓存穿透
2.1.1 描述
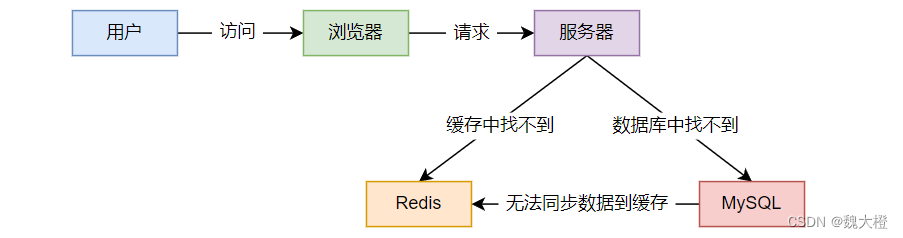
用户想要查询某个数据,在 Redis 中查询不到,即没有缓存命中,这时就会直接访问数据库进行查询。当请求量超出数据库最大承载量时,就会导致数据库崩溃。这种情况一般发生在非正常 URL 访问,目的不是为了获取数据,而是进行恶意攻击。
2.1.2 现象
- 应用服务器压力变大
- Redis缓存命中率降低
- 一直查询数据库
2.1.3 原因
一个不存在缓存及查询不到的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
2.1.4 解决
① 对空值缓存:如果一个查询数据为空(不管数据是否存在),都对该空结果进行缓存,其过期时间会设置非常短。
② 设置可以访问名单:使用bitmaps类型定义一个可以访问名单,名单id作为bitmaps的偏移量,每次访问时与bitmaps中的id进行比较,如果访问id不在bitmaps中,则进行拦截,不允许访问。
③ 采用布隆过滤器:布隆过滤器可以判断元素是否存在集合中,他的优点是空间效率和查询时间都比一般算法快,缺点是有一定的误识别率和删除困难。
④ 进行实时监控:当发现 Redis 缓存命中率急速下降时,迅速排查访问对象和访问数据,将其设置为黑名单。
2.2 缓存击穿
2.2.1 描述
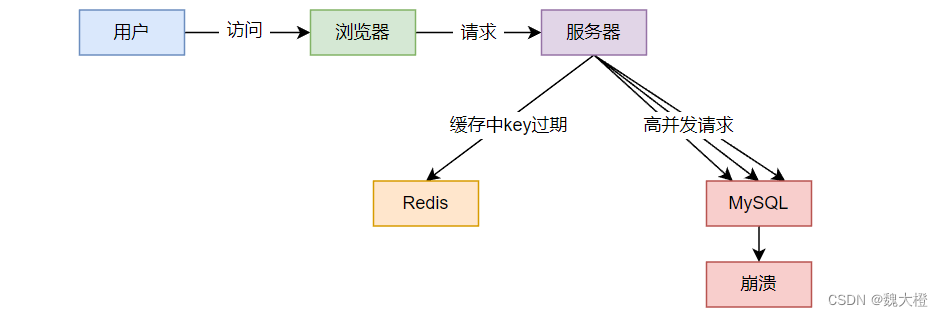
key中对应数据存在,当key中对应的数据在缓存中过期,而此时又有大量请求访问该数据,由于缓存中过期了,请求会直接访问数据库并回设到缓存中,高并发访问数据库会导致数据库崩溃。
2.2.2 现象
1、数据库访问压力瞬时增加
2、Redis中没有出现大量 Key 过期
3、Redis正常运行
4、数据库崩溃
2.2.3 原因
由于 Redis 中某个 Key 过期,而正好有大量访问使用这个 Key,此时缓存无法命中,因此就会直接访问数据层,导致数据库崩溃。
最常见的就是非常“热点”的数据访问。
2.2.4 解决
① 预先设置热门数据:在redis高峰访问时期,提前设置热门数据到缓存中,或适当延长缓存中key过期时间。
② 实时调整:实时监控哪些数据热门,实时调整key过期时间。
③ 对于热点key设置永不过期。
2.3 缓存雪崩
2.3.1 描述
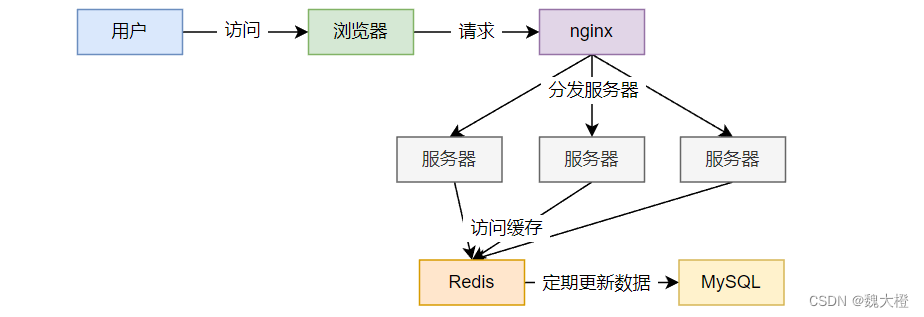
key中对应数据存在,在某一时刻,缓存中大量key过期,而此时大量高并发请求访问,会直接访问后端数据库,导致数据库崩溃。
注意:缓存击穿是指一个key对应缓存数据过期,缓存雪崩是大部分key对应缓存数据过期。
正常情况下:
缓存失效瞬间:
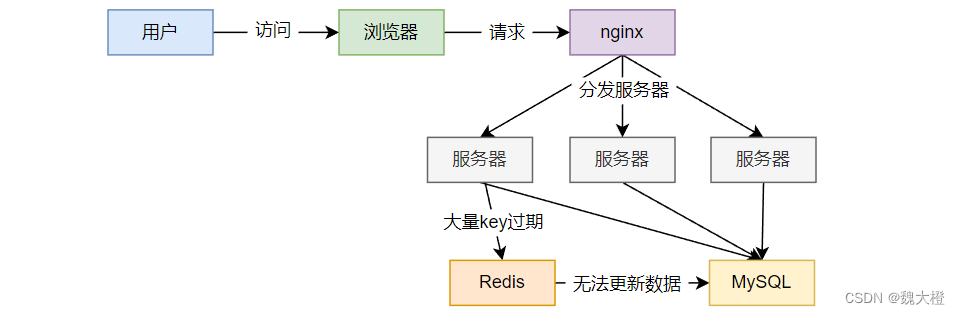
2.3.2 现象
1、数据库压力变大导致数据库和 Redis 服务崩溃
2.3.3 原因
在极短时间内,查询大量 key 的集中过期数据。
2.3.4 解决
① 构建多级缓存机制:nginx缓存 + redis缓存 + 其他缓存。
② 设置过期标志更新缓存:记录缓存数据是否过期,如果过期会触发另外一个线程去在后台更新实时key的缓存。
③ 将缓存可以时间分散:如在原有缓存时间基础上增加一个随机值,这个值可以在1-5分钟随机,这样过期时间重复率就会降低,防止大量key同时过期。
④ 使用锁或队列机制:使用锁或队列保证不会有大量线程一次性对数据库进行读写,从而避免大量并发请求访问数据库,该方法不适用于高并发情况。
这篇关于第六章 数据持久化及高频面试题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





