本文主要是介绍02、全文检索 ------ Solr(企业级的开源的搜索引擎) 的下载、安装、Solr的Web图形界面介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- Solr 的下载和安装
- Solr的优势:
- Lucene与Solr
- 安装 Solr
- 1、下载解压
- 2、添加环境变量
- 3、启动 Solr
- Solr 所支持的子命令:
- Solr 的 Core 和 Collection 介绍
- Solr 的Web控制台
- DashBoard(仪表盘)
- Logging(日志)
- Core Admin(Core管理)
- Java Properties(Java属性)
- Thread Dump(线程转储)
Solr 的下载和安装
Solr的优势:
Solr以独立应用的方式运行,就像一个 NoSQL 存储引擎一样,它既可用于管理 Lucene 索引库,也可用于作为同样的 NoSQL 存储库。
与Lucene相比,Solr提供了如下优势:
1、Solr是独立应用,而不是简单的框架。Lucene只是一个Java框架,如果开发者不懂Java,那它就没法调用Lucene的API来编写全文检索功能。
2、Solr提供了RESTful服务接口,开发者能以多种文档格式(XML、JSON或CSV)作为输入数据,Solr也能提供对应格式的响应。这种RESTful接口完全是编程语言无关的。
3、Solr是企业级的存储引擎,既支持独立部署,也支持作为大数据存储的分布式 NoSQL 数据库,还能以云端方式部署。
4、作为独立应用,Solr提供了用户友好的管理界面。
5、全文搜索方面:Solr提供了全文搜索所需的所有功能,例如令牌,短语,拼写检查,通配符和自动完成。
6、管理界面方面: Solr 提供了一个易于使用,用户友好,功能强大的用户界面,使用它可以执行所有可能的任务,如管理日志,添加,删除,更新和搜索文档。
Lucene与Solr
如果说Lucene是一个优秀的搜索引擎框架,那Solr就是基于Lucene的搜索引擎产品,
既降低了Lucene的使用门槛: 不管是否会编程,都可使用Solr;
也扩大了Lucene的使用范围: 不管是否使用Java,都能使用Solr;
还提高了Lucene的稳定性和可扩展性: 即使对最初级的菜鸟,Solr同样提供产品级稳定性及云端、分布式支持。
安装 Solr
1、登录Solr官网下载中心下载Solr压缩包,并解压该压缩包。得到如下文件结构:
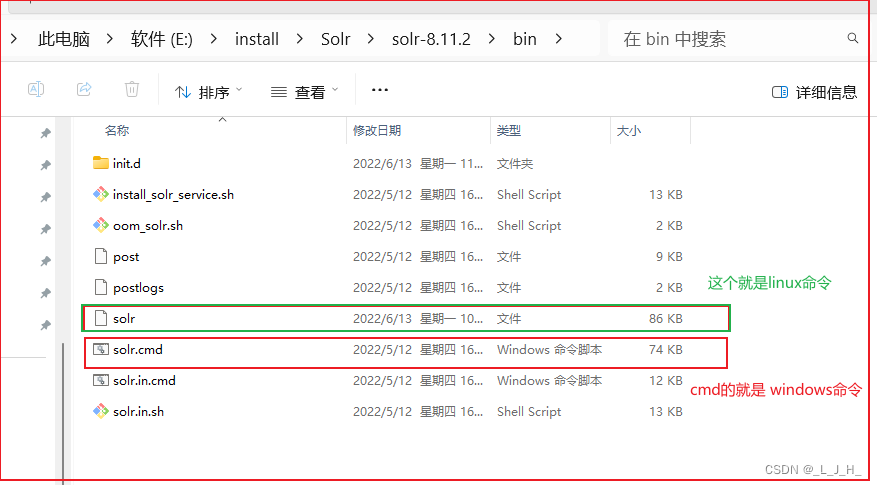
- bin:该目录下存放了Solr的工具命令。
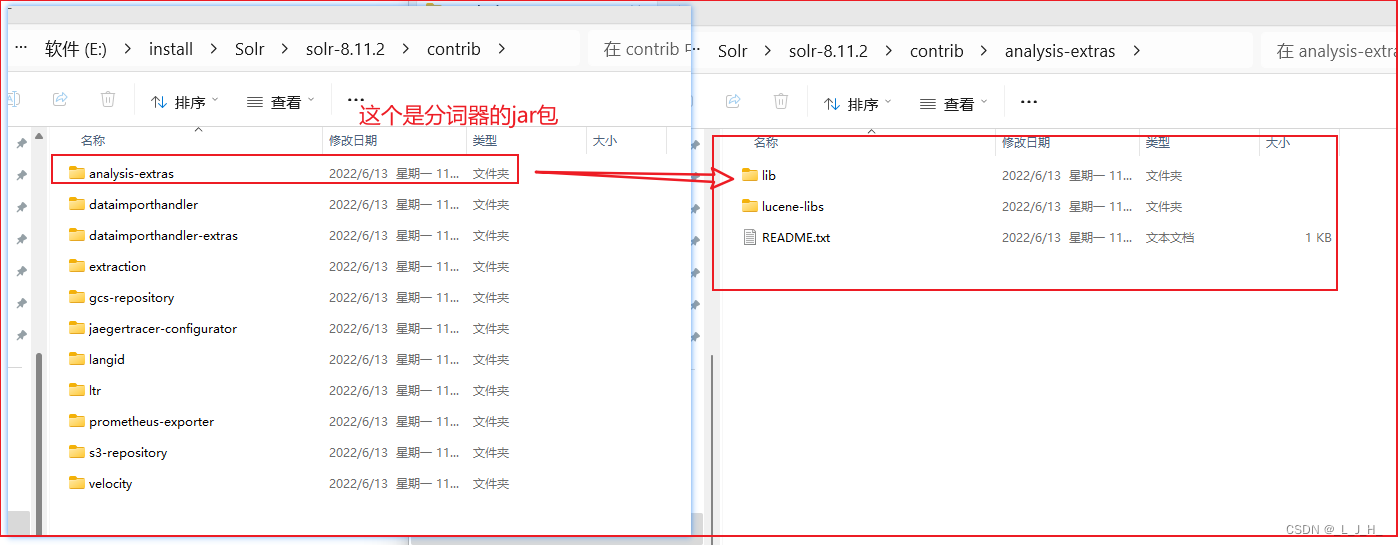
- contrib:该目录下存放了Solr所依赖的第三方JAR包
- dist:该目录下存放了Solr本身的JAR包。
- example:该目录下存放了Solr的各种示例。其中exampledocs和films子目录下存放了Solr索引库的示例文档。初学者可通过导入这些文档初始化索引库。
- server:该目录是Solr的核心,整个Solr应用程序、索引库都默认都保存在该目录下。
2、为Solr配置两个环境变量: JAVA_HOME和PATH,将Solr的bin目录所在的路径添加到PATH环境变量中,方便操作系统能找到Solr的bin目录下的命令。
3、执行如下命令即可启动Solr:
solr start -p <端口>
如果不指定端口,Solr 默认的端口是8983
演示:
1、下载解压
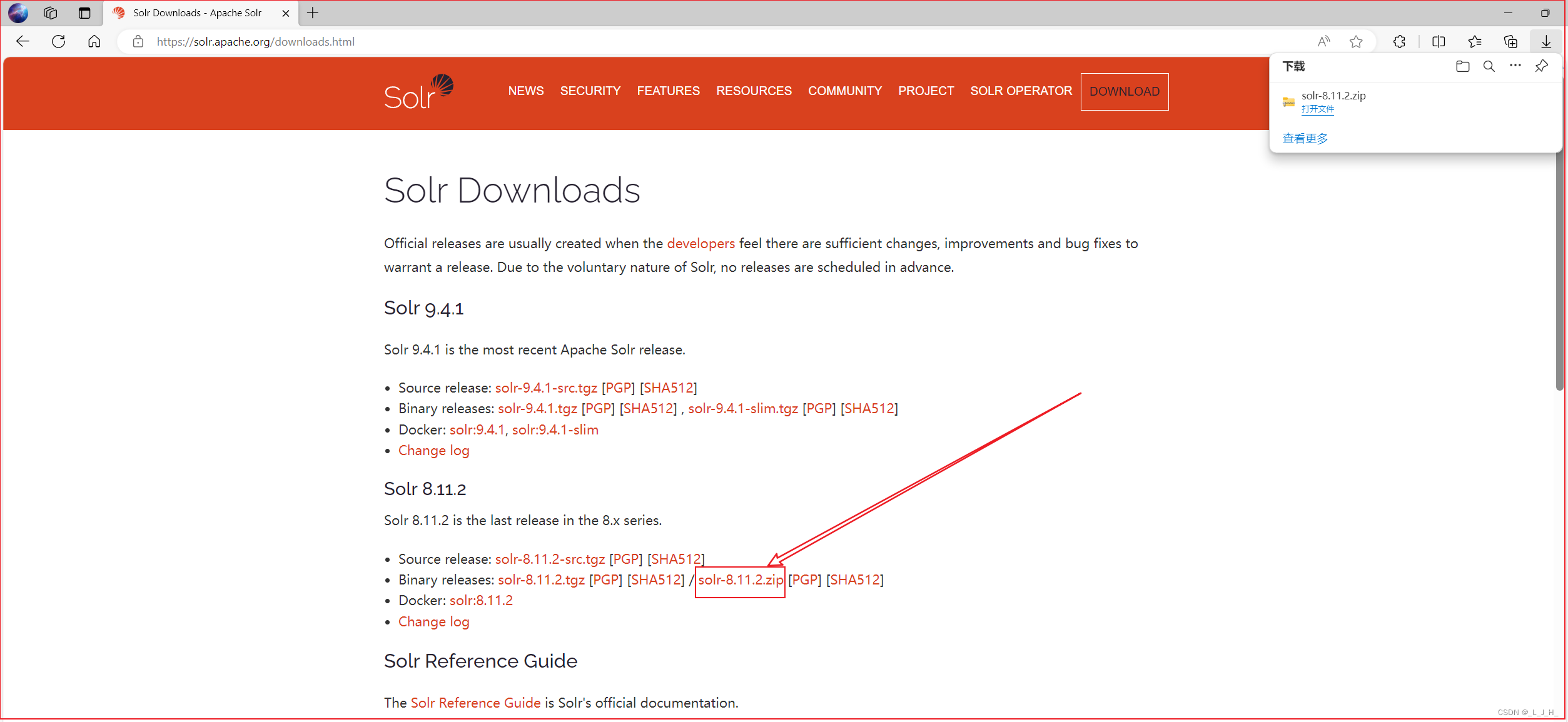
Solr 官网下载页面
我下载这个版本的 Solr ,后缀是 zip,然后解压就可以了
一些解释:
bin:该目录下存放了 Solr 的工具命令。
contrib:该目录下存放了Solr所依赖的第三方JAR包
2、添加环境变量
为Solr配置两个环境变量: JAVA_HOME 和 PATH,将 Solr 的 bin 目录所在的路径添加到 PATH 环境变量中,方便操作系统能找到 Solr 的 bin 目录下的命令
PATH:就是 Solr 的bin路径
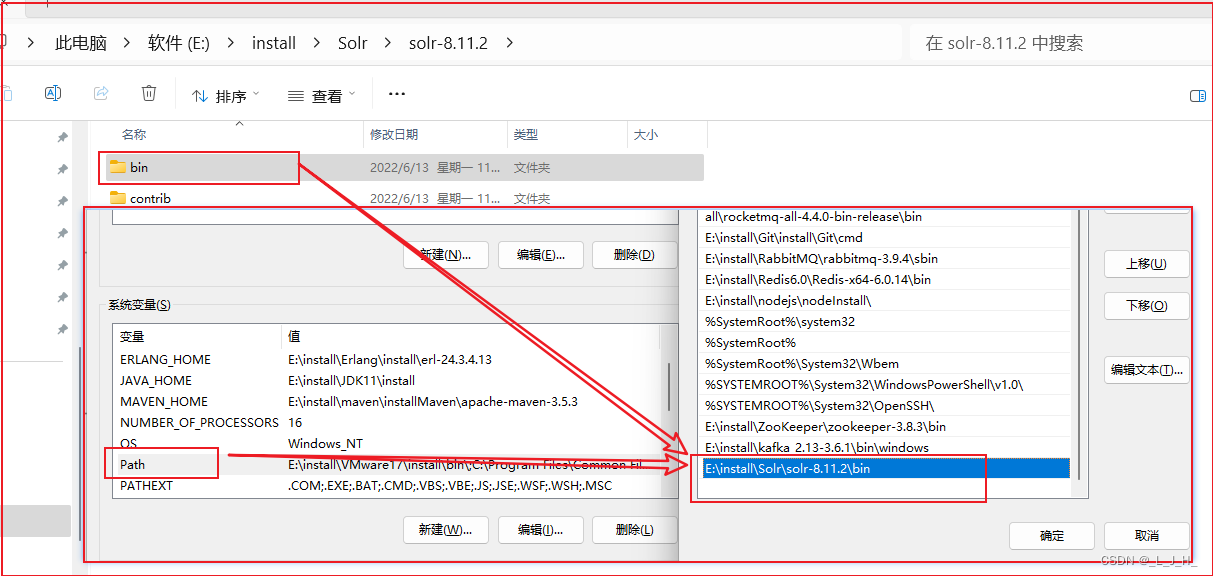
JAVA_HOME:就是jdk的环境变量
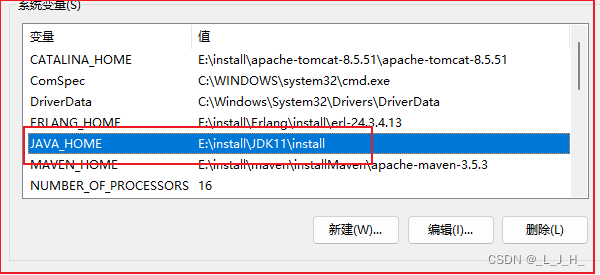
3、启动 Solr
执行如下命令即可启动Solr:
solr start -p <端口>
如果不指定端口,Solr 默认的端口是8983
直接输入 solr start 启动就可以了;
显示:在8983端口上启动Solr服务器,等待长达30分钟。寻找快乐!
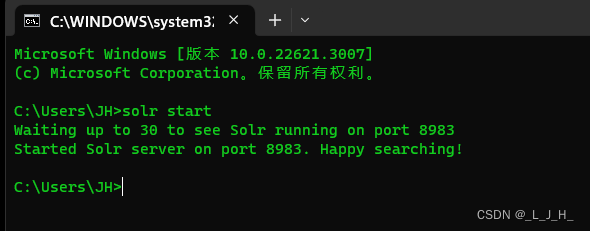
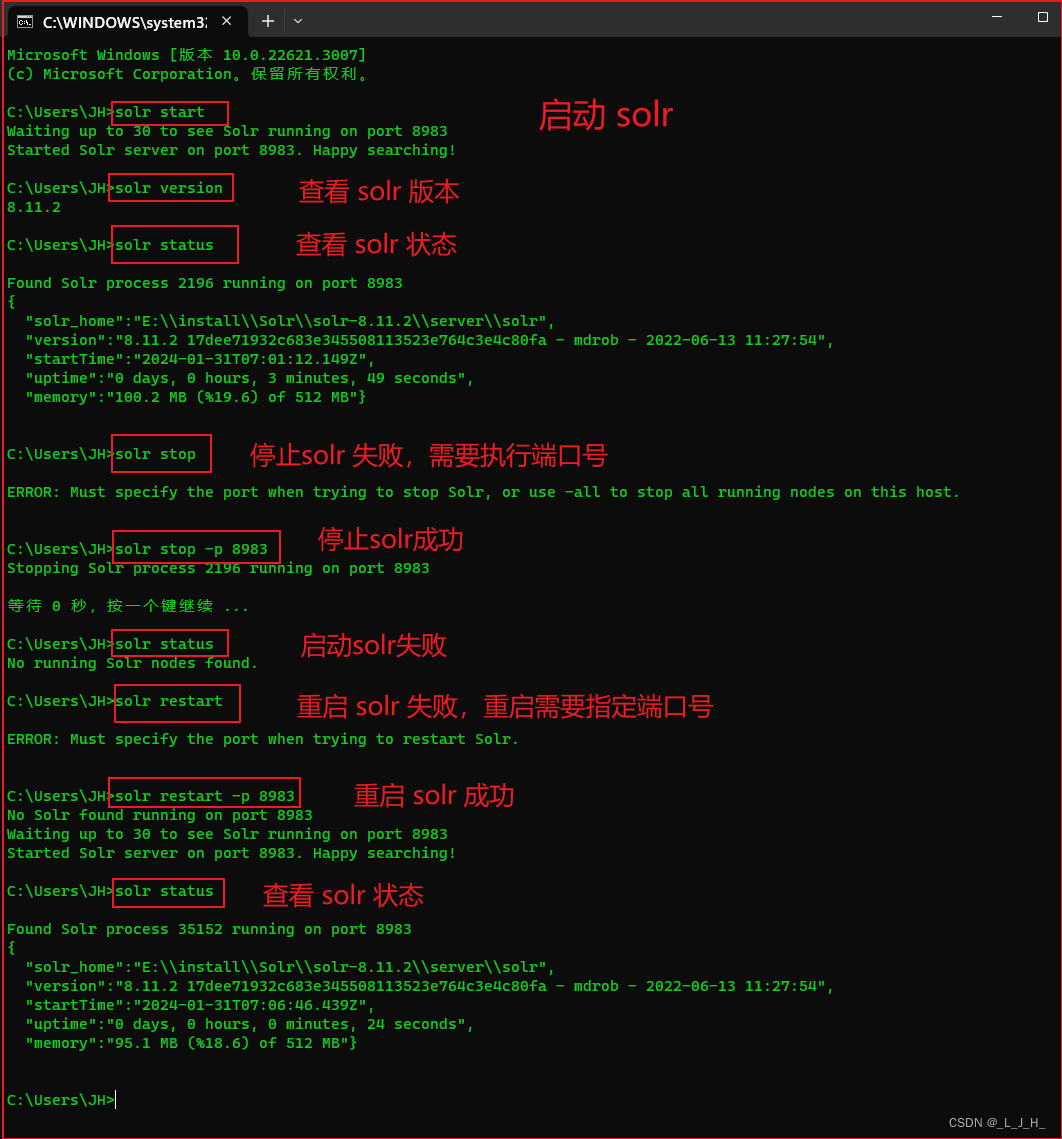
Solr 所支持的子命令:
如果solr命令不指定-p选项,那么Solr将默认监听8983端口。
此外,solr命令还支持如下常用子命令:
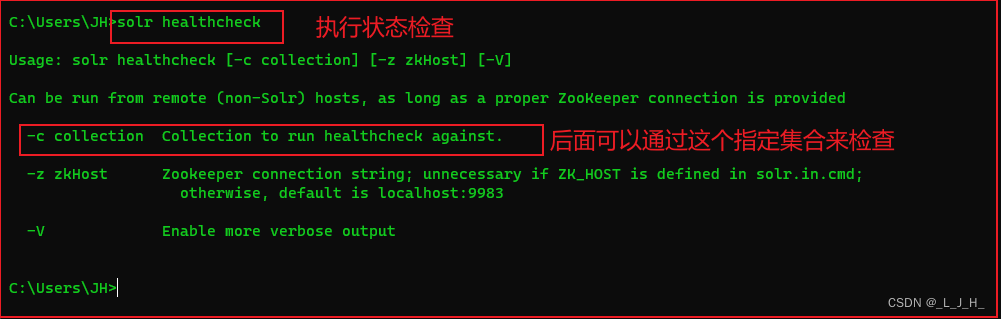
stop:停止Solr服务器。restart:重启Solr服务器。healthcheck:执行状态检查。create_core:用于为Solr服务器创建Core。create_collection:用于为Solr服务器创建Collection。create:根据Solr的运行状态选择创建Core或Collection;如果Solr以单机方式运行,该命令创建core;若Solr以云模式运行,该命令创建Collection。delete:删除Core或Collection。version:显示Solr的版本。
Solr 的 Core 和 Collection 介绍
Core 和 Collection 都表现成逻辑的“索引库”,有点类似于RDBMS的表(就是都类似关系型数据库中的表,比如mysql的表)。
逻辑索引库,也就是上面讲的反向索引库。
**从形象上来讲,可以把 Core 和 Collection 都理解成一张表。类似 MongoDB 的表 **
RDBMS:全拼是 Relational Database Management System ,字面上就是: 关系数据库管理系统例如:MySQL、Oracle、SQL Server 这些关系型数据库,都是基于"关系模型的数据库系统(RDBMS)”,简称关系型数据库,R是Relational的缩写。关系型数据库,就是把数据放入表格中,这些表格可以相互关联
在单机模式下,一个Core 等于一个 Collection。Solr的Core有点类似于RDBMS的表,
Solr Core同样具有支持唯一标识的主键,也需要定义多个Field。
与RDBMS不同的是,Core中存放的是各种文档,且这些文档不需要具有相同的 Field(其实和 MongoDB 的表里面存的是文档一样)
在单机模式下,一个Core就是一个逻辑索引库。
添加文档时为文档所指定的 Field 应该是 Core 所包含的 Field 的子集。
在SolrCloud模式下(云模式),一个 Collection 由分布在不同节点上的多个Core组成,但这个Collection仍然作为一个逻辑索引库,只是这个Colletion由不同的Core包含不同的Shards(分片)组成。
简而言之:
单机模式下,一个 Core 就等于一个逻辑索引库。
云模式下,一个 Collection 由多个 Core 所组成,且对外表现仍然为一个逻辑索引库。
Solr 的Web控制台
通过 “solr start -p <端口>”命令启动Solr之后,启动浏览器,访问http://localhost:8983/(假设没通过-p选项改变Solr的默认端口)将看到Web管理界面。
在Web管理界面可以看到如下5个标签:
DashBoard(仪表盘):显示Solr运行状态一览。
Logging(日志):显示Solr运行日志。
Core Admin(Core管理):提供了图形界面来管理Core。
备注: Core:在单机模式下,core 代表了逻辑索引库,类似于RDBMS的表。在云模式下,就是 Collection 来代表逻辑索引库
Java Properties(Java属性):显示当前运行的JVM属性一览。
Thread Dump(线程转储):显示Solr内部的线程转储。
在该图形管理界面上,用得最多的可能还是“Core Admin”。
DashBoard(仪表盘)
DashBoard(仪表盘):显示Solr运行状态一览
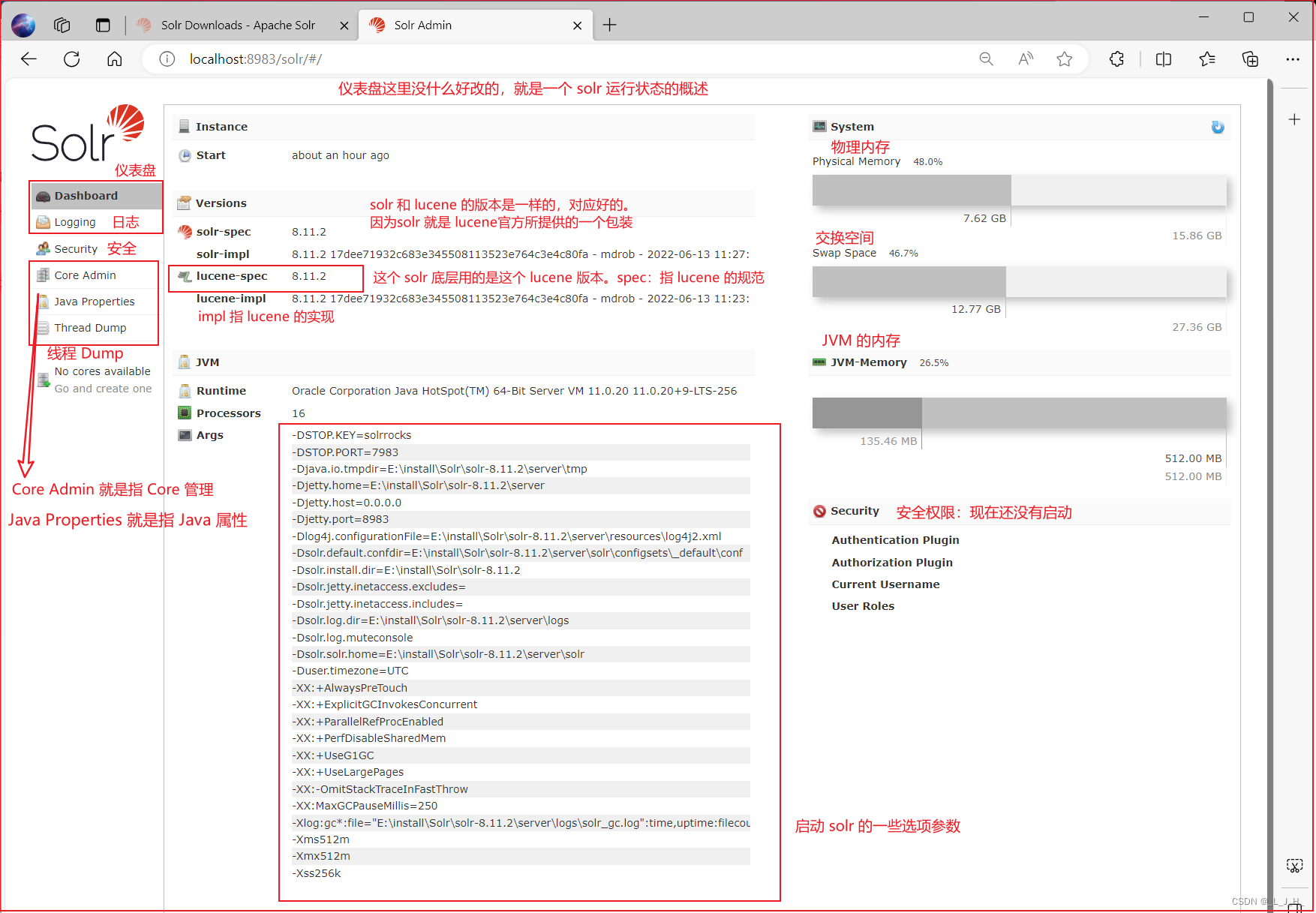
Logging(日志)
Logging(日志):显示Solr运行日志。
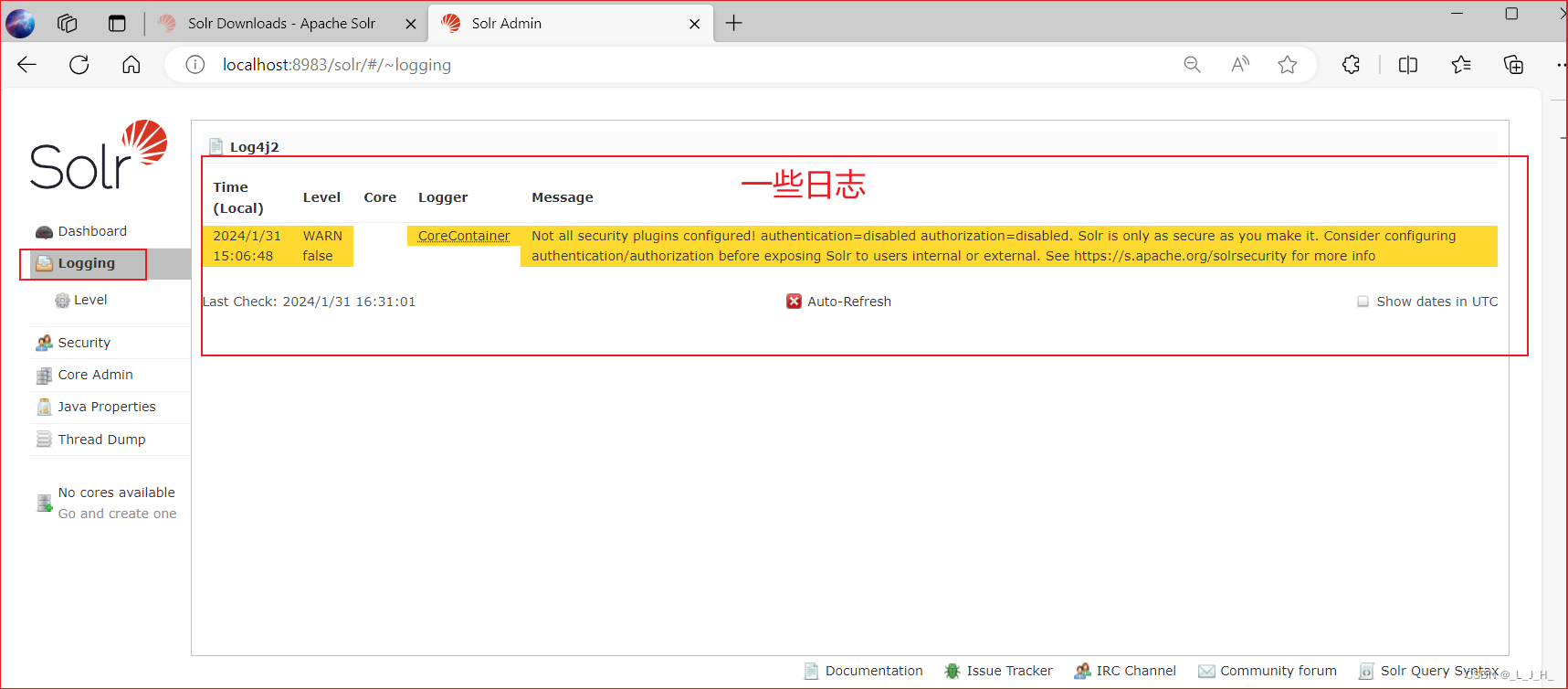
Core Admin(Core管理)
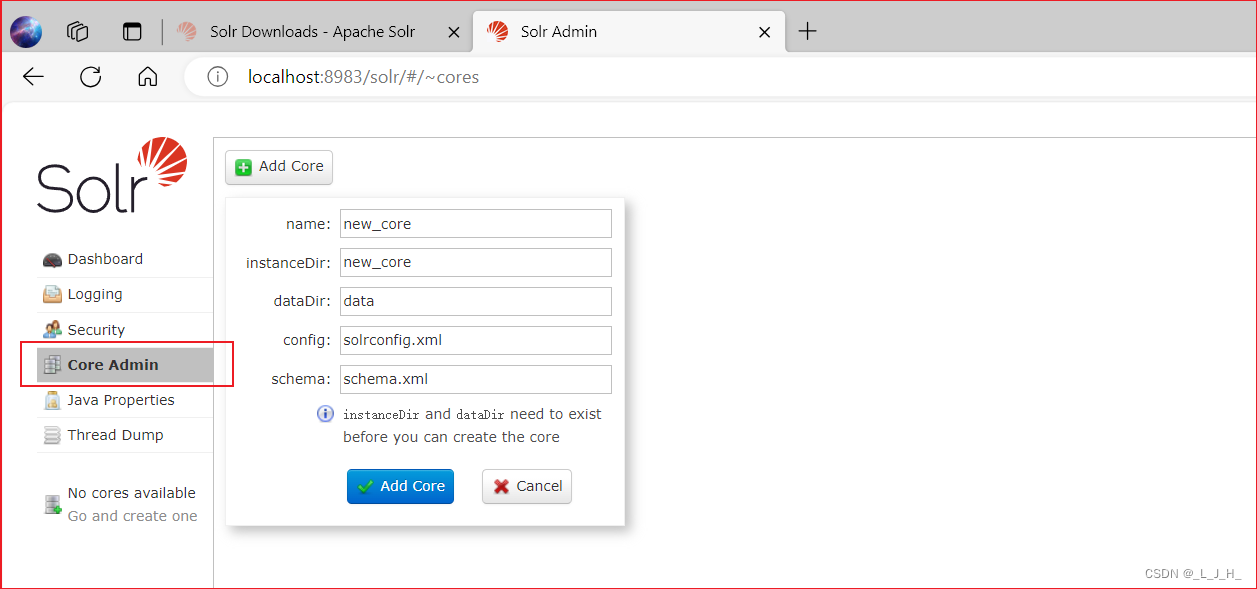
Core Admin(Core管理):提供了图形界面来管理Core。(用的最多)
我现在是在单机模式下运行这个 Solr ,所以这里显示的是 Core, core 代表了逻辑索引库
如果是在云模式下运行这个 Solr ,那么这里就会显示 Collection ,由 Collection 来代表逻辑索引库
在图形管理界面上,用得最多的可能还是“Core Admin”。
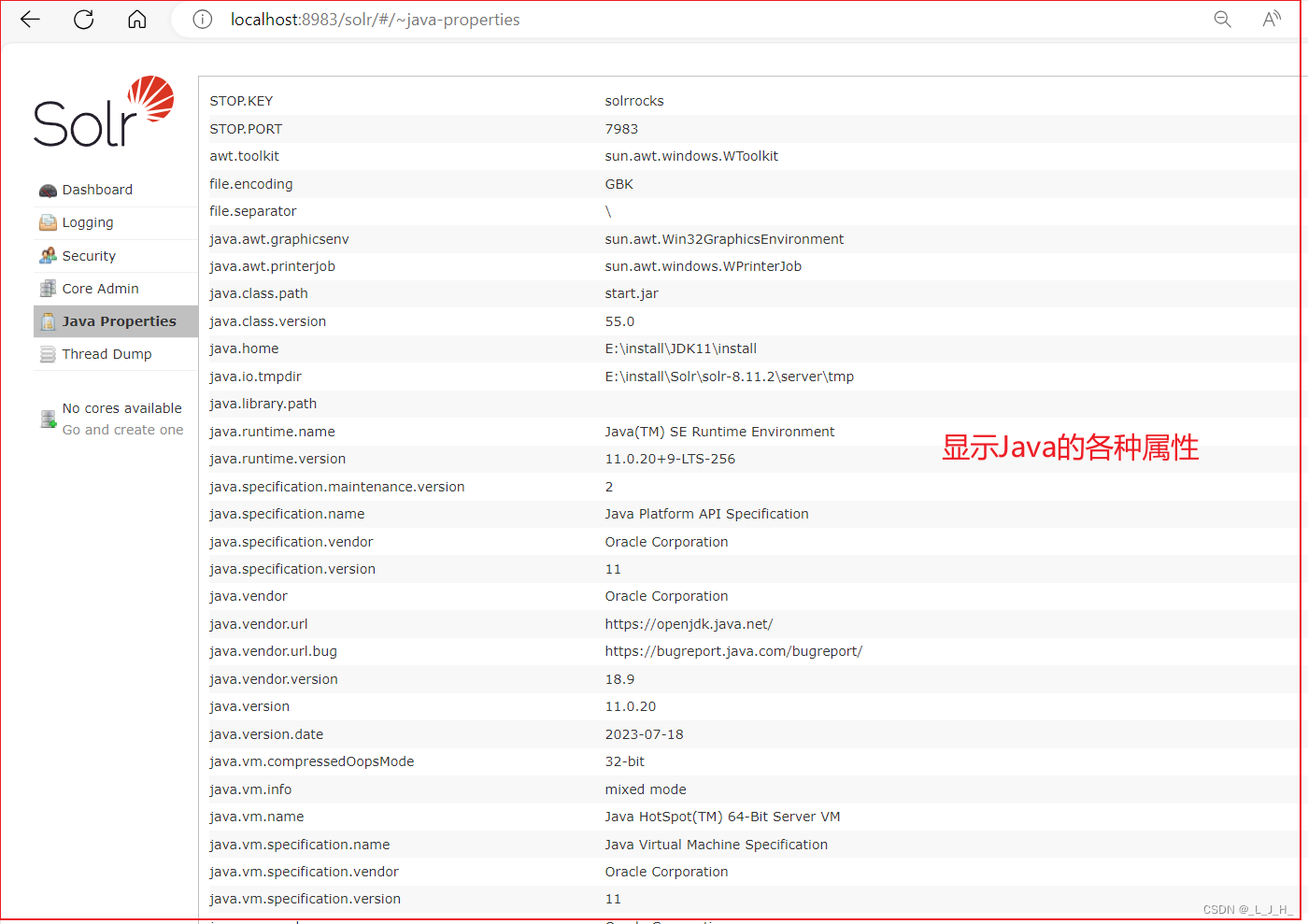
Java Properties(Java属性)
Java Properties(Java属性):显示当前运行的JVM属性一览。
显示各种 Java 属性
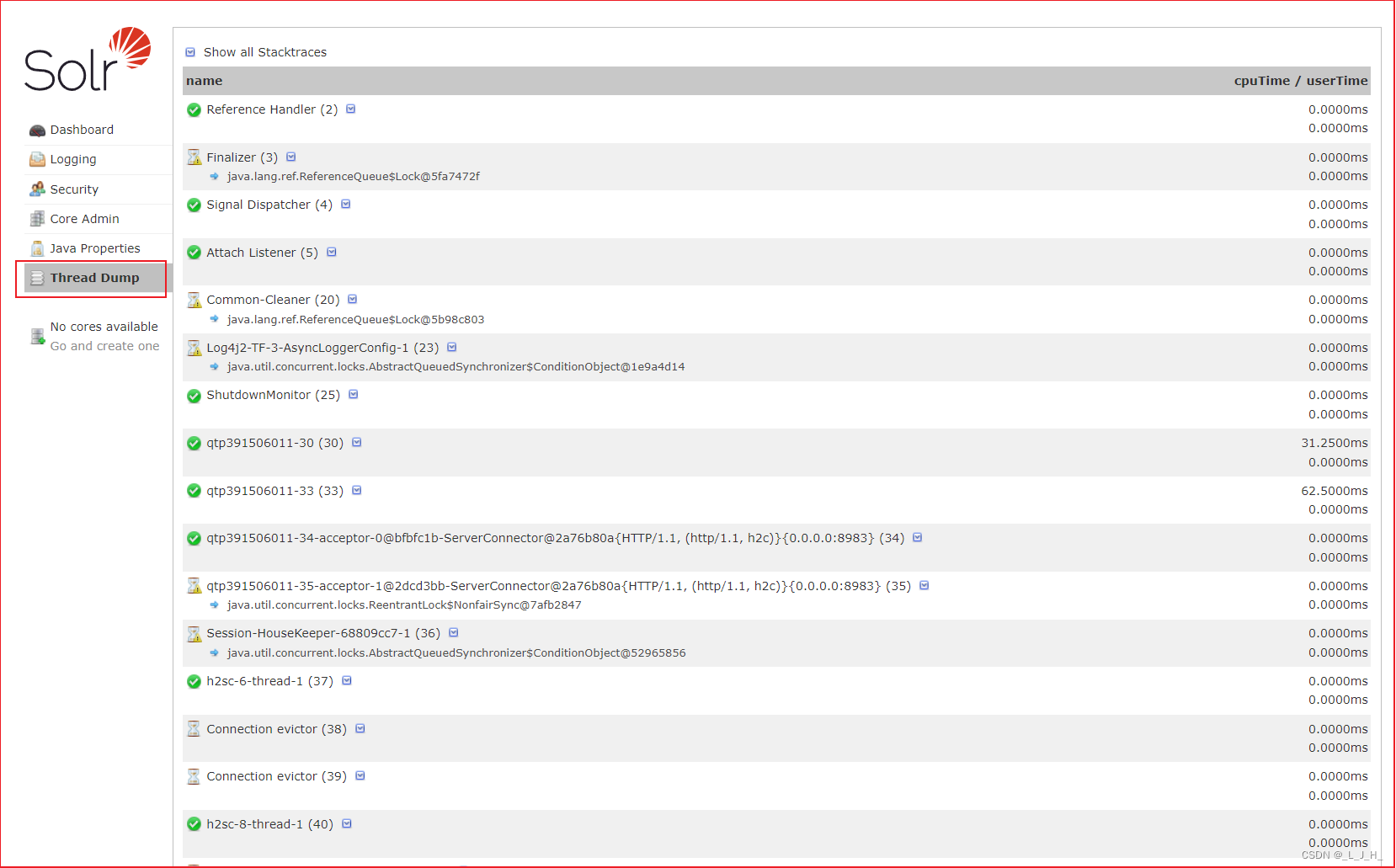
Thread Dump(线程转储)
Thread Dump(线程转储):显示Solr内部的线程转储。
这篇关于02、全文检索 ------ Solr(企业级的开源的搜索引擎) 的下载、安装、Solr的Web图形界面介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








