本文主要是介绍Java大数据学习09--Mapreduce数据压缩介绍和配置方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、概述:
数据压缩是mapreduce的一种优化策略:通过压缩编码对mapper或者reducer的输出进行压缩,以减少磁盘IO,提高MR程序运行速度(但相应增加了cpu运算负担)
二、基本原则:
运算密集型的job,少用压缩
IO密集型的job,多用压缩
注:
1、 Mapreduce支持将map输出的结果或者reduce输出的结果进行压缩,以减少网络IO或最终输出数据的体积
2、 压缩特性运用得当能提高性能,但运用不当也可能降低性能
三、MR支持的压缩编码
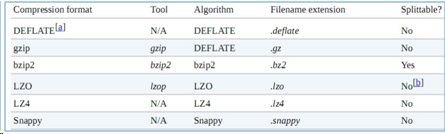
四、MR数据压缩的配置
四、MR数据压缩的配置
1、Reducer输出压缩
a、配置文件中配置
mapreduce.output.fileoutputformat.compress=false
mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodec
mapreduce.output.fileoutputformat.compress.type=RECORD
b、代码中配置
Job job = Job.getInstance(conf);
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, (Class<? extends CompressionCodec>) Class.forName(""));
2、Mapper输出压缩
a、配置文件中配置
mapreduce.map.output.compress=false
mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.DefaultCodec
b、代码中配置
conf.setBoolean(Job.MAP_OUTPUT_COMPRESS, true);
conf.setClass(Job.MAP_OUTPUT_COMPRESS_CODEC, GzipCodec.class, CompressionCodec.class);
3、压缩文件的读取
Hadoop自带的InputFormat类内置支持压缩文件的读取,比如TextInputformat类,在其initialize方法中:
public void initialize(InputSplit genericSplit,TaskAttemptContext context) throws IOException {FileSplit split = (FileSplit) genericSplit;Configuration job = context.getConfiguration();this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.MAX_VALUE);start = split.getStart();end = start + split.getLength();final Path file = split.getPath();// open the file and seek to the start of the splitfinal FileSystem fs = file.getFileSystem(job);fileIn = fs.open(file);
//根据文件后缀名创建相应压缩编码的codecCompressionCodec codec = new CompressionCodecFactory(job).getCodec(file);if (null!=codec) {isCompressedInput = true; decompressor = CodecPool.getDecompressor(codec);//判断是否属于可切片压缩编码类型if (codec instanceof SplittableCompressionCodec) {final SplitCompressionInputStream cIn =((SplittableCompressionCodec)codec).createInputStream(fileIn, decompressor, start, end,SplittableCompressionCodec.READ_MODE.BYBLOCK);//如果是可切片压缩编码,则创建一个CompressedSplitLineReader读取压缩数据in = new CompressedSplitLineReader(cIn, job,this.recordDelimiterBytes);start = cIn.getAdjustedStart();end = cIn.getAdjustedEnd();filePosition = cIn;} else {//如果是不可切片压缩编码,则创建一个SplitLineReader读取压缩数据,并将文件输入流转换成解压数据流传递给普通SplitLineReader读取in = new SplitLineReader(codec.createInputStream(fileIn,decompressor), job, this.recordDelimiterBytes);filePosition = fileIn;}} else {fileIn.seek(start);//如果不是压缩文件,则创建普通SplitLineReader读取数据in = new SplitLineReader(fileIn, job, this.recordDelimiterBytes);filePosition = fileIn;}
喜欢的朋友点点关注哦~~
这篇关于Java大数据学习09--Mapreduce数据压缩介绍和配置方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







