本文主要是介绍C语言KR圣经笔记 6.6 表查询 6.7 typedef,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
6.6 表查询
为了说明结构体的更多方面,本节我们来写一个表查询功能包的内部代码。在宏处理器或编译器的符号表管理例程中,这个代码是很典型的。例如,考虑 #define 语句,当遇到如下行
#define IN 1时,名称 IN 与其对应的替换文本 1 都要存到一张表中。然后,当名称 IN 出现在如下语句中时,
state = IN;它必须被替换成 1。
有两个例程用来操纵名称及其替换文本。install(s, t) 将名称 s 和 替换文本 t 记录到表格中,s 和 t 仅仅只是字符串。lookup(s) 在表格中搜索 s,并在找到时返回其指向的指针,若没找到则返回 NULL。
算法是哈希(hash)搜索——传入的名称被转换成一个小的非负整数,后续会用作指针数组的下标索引。一个数组元素指向一个链表的开头,该链表中所有元素名称的哈希值都等于该数组元素的下标值。如果没有一个名称的哈希值等于某个下标值,则该下标对应的数组元素值为NULL。
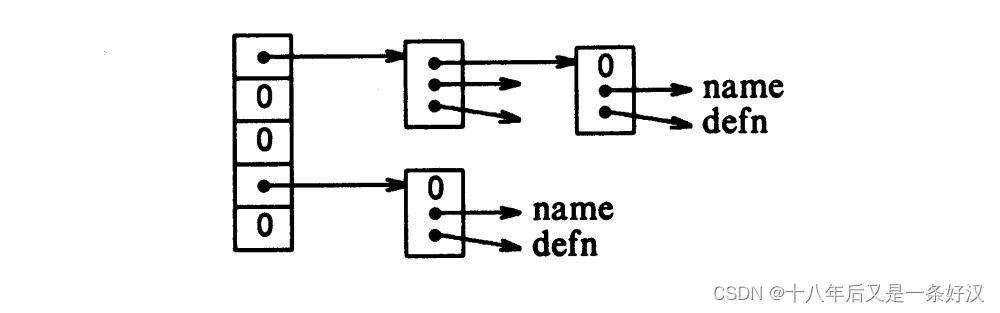
链表中的块(元素)是一个结构体,包含了:名称的指针,替换文本的指针,链表中下一个块的指针。若下一个指针为空,则标记链表结尾。
struct nlist { /* 表项 */struct nlist * next; /* 链表中的下一项 */char *name; /* 定义的名称 */char *defn; /* 替换文本 */
};而指针数组就是
#define HASHSIZE 101
static struct nlist *hastab[HASHSIZE]; /* 指针表 */lookup 和 install 都要使用的 hash 函数,会把字符串中每个字符值都加到对之前字符打散组合得到的值上,并返回对数组大小取模后得到的余数。这不是最好的hash函数,但是简短而高效。
/* hash:对字符串s生成哈希值 */
unsigned hash(char *s)
{unsigned hashval;for (hashval = 0; *s != '\0'; s++)hasval = *s + 31 * hashval;return hashval % HASHSIZE;
}无符号算术运算保证哈希值为非负。
哈希过程在数组 hashtab 中生成了一个起始的下标索引;如果字符串能被找到,它会位于从此处开始的链表中。搜索是通过 lookup 来执行的。如果 lookup 发现该项已经存在,则返回指向它的指针,否则返回 NULL。
/* lookup:在hashtab中搜索s */
struct nlist *lookup(char *s)
{struct nlist *np;for (np = hashtab[hash(s)]; np != NULL; np = np->next)if (strcmp(s, np->name) == 0)return np; /* 找到 */return NULL; /* 没找到 */
}lookup 中的 for 循环是遍历链表的标准用法:
for (ptr = head; ptr != NULL; ptr = ptr->next)...install 使用 lookup 来确定要加入的名称是否已经存在;如果是,则新定义会替换老的。否则,创建一个新的项。如果由于某种原因没有足够的空间来保存新的项,则 install 返回 NULL。
struct nlist *lookup(char *);
char *strdup(char *);/* install:将(name, defn)存入 hashtab 中*/
struct nlist *install(char *name, char *defn)
{struct nlist *np;unsigned hashval;if ((np = lookup(name)) == NULL) { /* 没找到 */np = (struct nlist *)malloc(sizeof(struct nlist));if (np == NULL || (np->name = strdup(name)) == NULL)return NULL;hashval = hash(name);np->next = hashtab[hashval];hashtab[hasval] = np;} else /* 已经存在 */free((void *) np->defn); /* 释放之前的defn */if ((np->defn = strdup(defn)) == NULL)return null;return np;
}练习6-5、写个程序 undef, 从 lookup 和 install 维护的表中删除一个名称和定义。
练习6-6、基于本节的例程,写出一个适用于 C 程序的简单版本(即不带参数的)的 #define 预处理器。你会发现 getch 和 ungetch 也有用。
6.7 typedef
C语言提供了一种叫做 typdef 的机制,来创建新的数据类型名称。例如,声明
typedef int Length;使 Length 这个名称成为 int 的同义词。类型 Length 可以用在声明,强制类型转换等等地方,与 int 类型可以使用的地方完全相同:
Length len, maxlen;
Length *lengths[];类似地,如下声明
typedef char *String;使 String 成为 char * 或字符指针的同义词,也能用于声明和强制类型转换:
String p, lineptr[MAXLINES], alloc(int);
int strcmp(String, String);
p = (String)malloc(100);注意,在 typedef 中声明的类型出现在变量名的位置,而不是紧跟在 typedef 单词后面。在语法上,typedef 类似存储类型关键字如 extern, static 等。我们把 typedef 定义的类型名首字母大写,使其更醒目。
举个更复杂的例子,我们对本章前面例子中的树节点使用 typedef:
typedef struct tnode *Treeptr;typedef struct tnode { /* 树节点: */char *word; /* 指向文本 */int count; /* 出现次数 */struct tnode *left; /* 左子节点 */struct tnode *right; /* 右子节点 */
} Treenode;这就创建了两个新的类型关键字: Treenode(结构体)和 Treeptr(结构体指针)。因此 talloc 例程可以写成:
Treeptr talloc(void)
{return (Treeptr) malloc(sizeof(Treenode));
}必须强调,typedef 声明绝对没有创建新的类型;它仅仅是给某些已经存在的类型加了新的名字。typedef 也没有引入新的语义:用这种方式声明的变量,与不用它而显式写出的变量,两者属性完全相同。实际上, typedef 就像是 #define,区别在于它是由编译器解析的,因此能处理超出预处理器能力的文本替换。例如
typedef int (*PFI)(char *, char *);创建了 PFI 类型,代表“返回 int 类型的函数的指针(有两个 char * 参数)”,它能用在对应的上下文,例如第五章的排序程序中:
PFI strcmp, numcmp;除了纯粹的美学问题外,使用 typedef 还有两个主要原因。首先是将程序参数化以应对可移植性问题。如果把 typedef 用于可能依赖机器的数据类型,那么当程序需要移植时,就只有 typedef 需要修改。一种常见的情况是用 typedef 来命名各种不同的整数数量,然后为每种主机选择一套合适的 short、int 和 long。标准库中的 size_t 和 ptrdiff_t 就是这样的例子。
使用 typedef 的第二个目的是为程序提供更好的说明——名为 Treeptr 的类型,会比仅声明为指向复杂结构体类型的指针更好理解。
这篇关于C语言KR圣经笔记 6.6 表查询 6.7 typedef的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




