本文主要是介绍一文速学-selenium高阶操作连接已存在浏览器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
不得不说selenium不仅在自动化测试作为不可或缺的工具,在数据获取方面也是十分好用,能够十分快速的见到效果,这都取决于selenium框架的足够的灵活性,甚至在一些基于web端的自动化办公都十分有效。
通过selenium连接已经存在数据存储的浏览器,可以通过这种方式绕过短期内无法解决的验证码的识别,也可以绕过大部分网页保护措施。那么现在就来看看我们如何实现。
启动浏览器
首先我们要了解浏览器存储了多种内容,其中一些可以在不同网站或网页之间共享,而其他一些则受限于特定的域或浏览器安全策略。
1.Cookies
想象 Cookies 像是酒店的门房,每当你进出酒店(即网站)时,门房都会记住你(存储信息)。他们在你每次访问时识别你,并记住你的偏好(如房间偏好)。但门房的记忆空间很小,只能记住一些基本信息。同时,门房每次见到你都会提醒酒店你的偏好(Cookies 随着每次 HTTP 请求发送到服务器)。
Cookies存储十分重要,Cookies网站为了记录用户信息(如登录状态、用户偏好设置等)而存储在用户本地的小型数据片段。通常只能被设置它们的那个网站访问。不过,有些 cookies(如第三方 cookies)可能被多个网站共享,用于跟踪用户在不同网站的行为。具体介绍在博主前篇文章有详细介绍,有兴趣的请去阅读,这里暂不展开。
2. Local Storage
Local Storage 像是你在酒店房间内的保险箱。它可以存储更多的东西,只要你不清空保险箱或离开酒店(关闭浏览器),你的物品就一直安全地存放在那里。这些物品只属于这个房间,换到别的房间(另一个网站或浏览器标签)时,就无法访问这些物品了。
Local Storage 是一种允许网站在用户的浏览器上存储数据的机制。它是 HTML5 Web Storage API 的一部分,旨在克服传统的 cookie 存储的限制,提供了一种更加安全和高效的方式来存储数据。
-
容量限制:与 cookies 相比,Local Storage 提供更大的存储空间(通常至少 5MB)。
-
生命周期:Local Storage 中的数据没有过期时间,数据会一直存在直到被显式清除,无论浏览器窗口或标签页是否关闭。
-
域限制:数据存储是基于域名的。一个网站只能访问它自己设置的数据,无法访问其他网站的 Local Storage。
-
同源策略:遵循同源策略,即协议、域名和端口号都必须与存储数据的原始网站一致。
虽然 Local Storage 提供的存储空间比 cookies 多,但它仍有限制(一般为 5-10 MB),并且不同浏览器可能有所不同。数据在不同的浏览器会话间是持久的,但它不适用于跨浏览器的数据共享。Local Storage 存储的数据不会随着 HTTP 请求被发送,这有助于提高安全性。但它仍然是存储在客户端,因此不应该用来存储敏感信息。几乎所有现代浏览器都支持 Local Storage,包括移动端浏览器。
3.Session Storage
Session Storage 是 Web Storage API 的一部分,它提供了一种在用户浏览器上存储数据的机制。与 Local Storage 类似,Session Storage 用于存储键值对数据,但它的生命周期和作用域与 Local Storage 有所不同。
-
生命周期:Session Storage 中的数据只在当前浏览器会话期间有效。一旦浏览器窗口或标签页被关闭,存储的数据就会被清除。
-
存储容量:和 Local Storage 一样,Session Storage 提供较大的存储容量(通常至少 5MB),远大于 cookies。
-
作用域:数据存储在特定的窗口或标签页内,即使是相同的网站,在不同的标签页或窗口中的 Session Storage 也是独立的。
-
同源策略:Session Storage 遵守同源策略,即协议、域名和端口号都必须与存储数据的原始网站一致。
三者比较起来:
-
Cookies:有限的存储空间,每次与服务器交互时都会被发送,适合存储需要服务器知道的信息。
-
Local Storage:较大的存储空间,仅在客户端保存,适合存储不需要经常变更的本地数据。
-
Session Storage:存储空间适中,但数据仅在单个会话中有效,适合临时存储敏感操
所以当我们连接到已经有数据存储的浏览器和新创建的浏览器,区别主要就在于这些已经存储好了的数据,了解这些我们就知道为什么我们在已经存储的浏览器访问之前已经登录过的网址是不需要再输入密码验证了的。
我们一般启动浏览器都是双击快捷方式,其实这就是一种指令的运行方式。我们可以打开我们的快捷方式,点击属性查看:

我们在终端输入这条指令起到的效果是一样的:
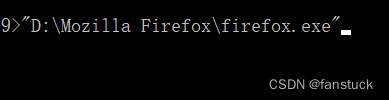
大家可以尝试,所以我们启动浏览器的方式有很多种,我们可以启动FirFox的时候开启Marionette 服务。Marionette 是用于远程控制 Firefox 的协议和接口,经常用于浏览器的自动化测试。Chorm也是一样,不过二者参数名称不同。通过以下这段代码可以实验:
!"D:\Mozilla Firefox\firefox.exe" --marionette --marionette-port 2828指定了 2828为Marionette 服务监听的端口号,然后我们要让geckodriver.exe也就是火狐的驱动连接到该端口:
geckodriver.exe --connect-existing --marionette-port 2828我们还可以在终端输入指令
netstat -ano|findstr "4444"可以看到我们监听的端口:

接下来我们就可以通过selenium来连接这个端口了,这里需要注意的是selenium版本的问题,Selenium 3.x 可能不支持连接到已经打开的浏览器实例。这个功能主要在 Selenium 4.x 中通过对 Service 类的使用而得到支持。但是3.x的谷歌浏览器可以做到,火狐是做不到的。Marionette驱动程序不再适用于FF版本53和Selenium 3.5或更高版本,如果selenium高于这个版本可以用谷歌浏览器,不然会出现selenium.common.exceptions.TimeoutException: Message: 由于目标计算机积极拒绝,无法连接。 (os error 10061)错误。
谷歌浏览器指令为:
"chrome.exe" --remote-debugging-port=9222 --user-data-dir="user_path"一定要指定存储浏览器数据的目录"user_path",端口默认为9222。
链接浏览器
1.谷歌浏览器
如果是谷歌浏览器开放的端口的话:
from selenium import webdriver
from selenium.webdriver.chrome.options import Optionsoptions = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")# 确保您的 chromedriver 路径是正确的
driver = webdriver.Chrome( options=options)
连接完毕后就可以自行操作了。
2.火狐浏览器
from selenium import webdriver
from selenium.webdriver.firefox.options import Options# 创建一个新的Firefox选项对象
options = Options()# 连接到已经存在的Firefox实例
driver = webdriver.Remote(command_executor="http://localhost:4444", options=options)如果火狐出现问题多半是你selenium的版本不匹配,看我上一节点的末尾,有写清楚情况。那么以上基本就可以实现了。
这篇关于一文速学-selenium高阶操作连接已存在浏览器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






