本文主要是介绍【Python】03快速上手爬虫案例三:搞定药师帮,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 1、破解验证码
- 2、获取数据
前言
流程:通过用户名、密码、搞定验证码,登录进药师帮网站,然后抓取想要的数据。
爬取数据,最终效果图:

1、破解验证码
使用药师帮测试系统:https://dianrc.ysbang.cn/#/home
引入打码平台进行破解,我这里使用的是云码。
代码如下:
code_result.py
import json
import requests
import base64class YdmVerify(object):_custom_url = "http://api.jfbym.com/api/YmServer/customApi"_token = "" #云码的token_headers = {'Content-Type': 'application/json'}def common_verify(self, image, verify_type="10103"):#注意10110不行,这里要使用10103payload = {"image": base64.b64encode(image).decode(),"token": self._token,"type": verify_type}print(payload)resp = requests.post(self._custom_url, headers=self._headers, data=json.dumps(payload))print(resp.text)return resp.json()['data']['data']# 云码打码对应代码
Y = YdmVerify()
with open("codeysb.png", 'rb') as f:img_content = f.read()
resp = Y.common_verify(img_content)
2、获取数据
步骤:
1)使用Chrome浏览器模拟打开网页
2)使用selenium自动登录
3)登录成功之后,继续在浏览器中打开需要获取数据的url
4)获取数据,导出cvs表格
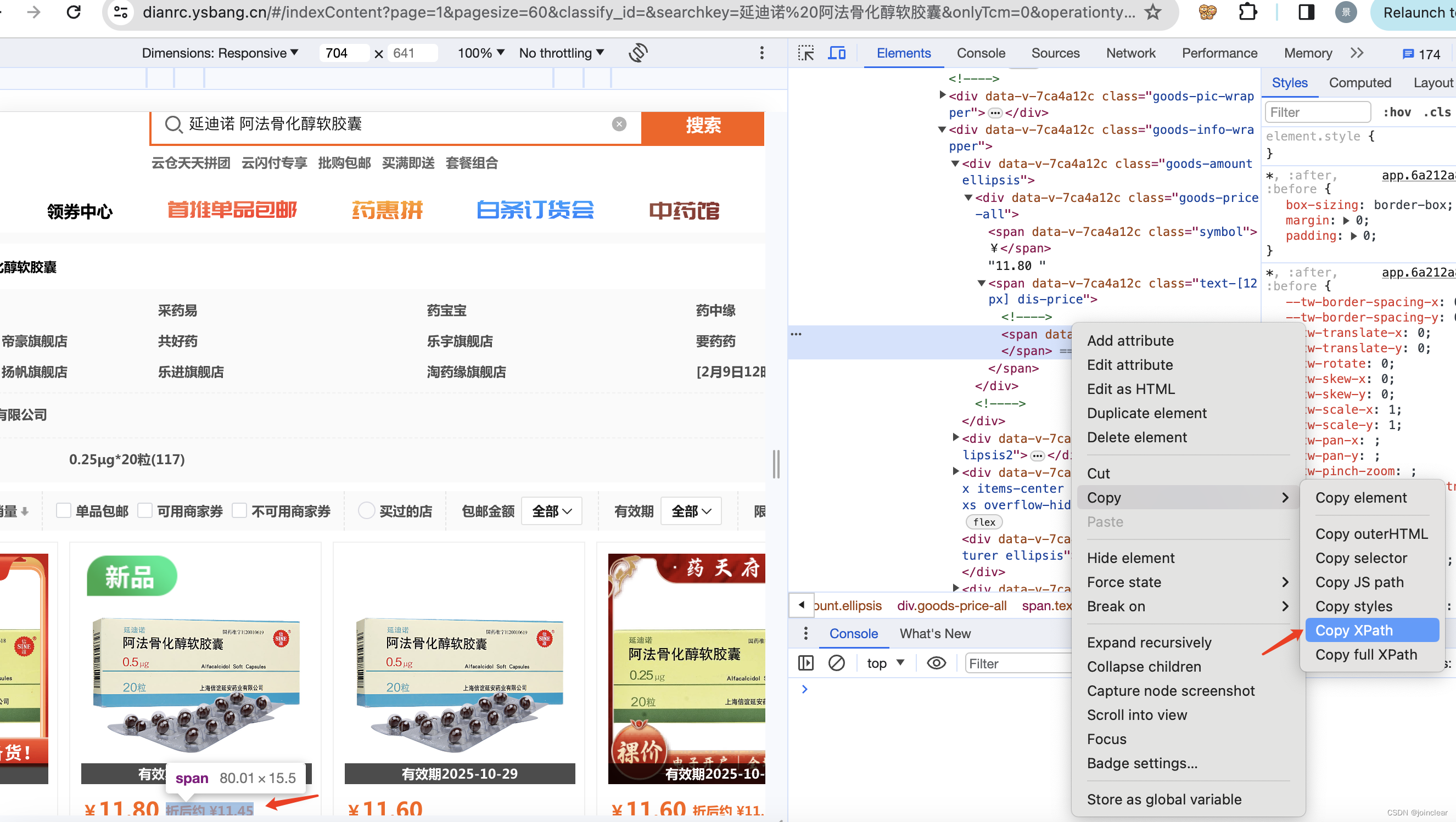
代码如下(只获取第一页数据):
from selenium.webdriver.common.by import By
from selenium import webdriverimport time
import requests
from lxml import etree
from code_result import YdmVerify
import csvdriver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://dianrc.ysbang.cn/#/login?redirect=%2Fhome')
time.sleep(2)name = driver.find_element(By.NAME, 'userAccount') # 账号输入框位置
name.send_keys("") # 输入你的账号
pwd = driver.find_element(By.CSS_SELECTOR, "#password") # 密码输入框位置
pwd.send_keys("") # 输入你的密码
code = driver.find_element(By.CSS_SELECTOR, "#captcha") # 验证码输入框位置
imgCode = driver.find_element(By.CSS_SELECTOR, "#captchaImg") # 验证码图片位置imgCode.screenshot("codeysb.png") # 将验证码截图
time.sleep(1)# 云码打码
Y = YdmVerify()
with open("codeysb.png", 'rb') as f:img_content = f.read()
resp = Y.common_verify(img_content)
print(resp)
code.send_keys(resp)login = driver.find_element(By.CLASS_NAME, 'btn') # 找到登录的位置
login.click() # 点击登录按钮
time.sleep(2)# 获取数据
html=""
url = "https://dianrc.ysbang.cn/#/indexContent?page=1&pagesize=60&classify_id=&searchkey=%E5%BB%B6%E8%BF%AA%E8%AF%BA%20%E9%98%BF%E6%B3%95%E9%AA%A8%E5%8C%96%E9%86%87%E8%BD%AF%E8%83%B6%E5%9B%8A&onlyTcm=0&operationtype=1&provider_filter=&qualifiedLoanee=0&factoryNames=&specs=&drugId=-1&tagId=&showRecentlyPurchasedFlag=true&onlyShowRecentlyPurchased=false&onlySimpleLoan=false&sn=&deliverFloor=0&purchaseLimitFloor=0&validMonthFloor=0&activityType=%5B%5D&providerSelectList=%5B%5D&factorySelectList=%5B%5D&gradeNameSelectList=%5B%5D&exeStandardSelectList=%5B%5D&specSelectList=%5B%5D&classItem_0=null&classItem_1=null&classItem_2=null&tagName=&_t=1706324500733&_isReplace=true&trafficType=1"
driver.get(url)
driver.implicitly_wait(5)
time.sleep(5)
html = driver.page_source
print(html)
time.sleep(3)
driver.quit()parse = etree.HTML(html)
# 数据
all_tr = parse.xpath('//*[@id="wrapper"]/div[5]/div[3]/div')# 创建csv文件
with open('ysb.csv', 'a', encoding='utf_8_sig', newline='') as fp: header = ['名称','价格', '折扣价', '公司', '旗舰店', '有效期', '图片'] writer = csv.writer(fp) writer.writerow(header)for tr in all_tr:price2 = ''.join(tr.xpath('./div[2]/div[1]/div/span[2]/span/text()')).strip()if len(price2) == 0:price = ''.join(tr.xpath('./div[2]/div[1]/div/div/text()')).strip()else:price = ''.join(tr.xpath('./div[2]/div[1]/div/text()')).strip()tr_data = {'name': ''.join(tr.xpath('./div[2]/div[2]/span/text()')).strip(), # 名称'price': price, # 价格'price2': price2, # 折扣价'commpany': ''.join(tr.xpath('./div[2]/div[4]/text()')).strip(), # 公司'qjd': ''.join(tr.xpath('./div[3]/div[1]/span/a/text()')).strip(), # 旗舰店'yxq': ''.join(tr.xpath('./div[1]/span/text()')).strip(), # 有效期'img': ''.join(tr.xpath('./div[1]/img/@src')).strip(), # 图片}# 写入数据行with open('ysb.csv', 'a', encoding='utf_8_sig', newline='') as fp: fieldnames = ['name','price', 'price2', 'commpany', 'qjd', 'yxq', 'img'] writer = csv.DictWriter(fp, fieldnames) writer.writerow(tr_data)代码如下(获取所有页数据):
from selenium.webdriver.common.by import By
from selenium import webdriverimport time
import requests
from lxml import etree
from code_result import YdmVerify
import csvdriver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://dianrc.ysbang.cn/#/login?redirect=%2Fhome')
time.sleep(2)name = driver.find_element(By.NAME, 'userAccount') # 账号输入框位置
name.send_keys("") # 输入你的账号
pwd = driver.find_element(By.CSS_SELECTOR, "#password") # 密码输入框位置
pwd.send_keys("") # 输入你的密码
code = driver.find_element(By.CSS_SELECTOR, "#captcha") # 验证码输入框位置
imgCode = driver.find_element(By.CSS_SELECTOR, "#captchaImg") # 验证码图片位置imgCode.screenshot("codeysb.png") # 将验证码截图
time.sleep(1)# 云码打码
Y = YdmVerify()
with open("codeysb.png", 'rb') as f:img_content = f.read()
resp = Y.common_verify(img_content)
print(resp)
code.send_keys(resp)login = driver.find_element(By.CLASS_NAME, 'btn') # 找到登录的位置
login.click() # 点击登录按钮
time.sleep(2)def getData(page):print(f"开始第{page}页数据获取")driver.implicitly_wait(5)time.sleep(5)html = driver.page_sourceparse = etree.HTML(html) # 数据all_tr = parse.xpath('//*[@id="wrapper"]/div[5]/div[3]/div')for tr in all_tr:price2 = ''.join(tr.xpath('./div[2]/div[1]/div/span[2]/span/text()')).strip()if len(price2) == 0:price = ''.join(tr.xpath('./div[2]/div[1]/div/div/text()')).strip()else:price = ''.join(tr.xpath('./div[2]/div[1]/div/text()')).strip()tr_data = {'name': ''.join(tr.xpath('./div[2]/div[2]/span/text()')).strip(), # 名称'price': price, # 价格'price2': price2, # 折扣价'commpany': ''.join(tr.xpath('./div[2]/div[4]/text()')).strip(), # 公司'qjd': ''.join(tr.xpath('./div[3]/div[1]/span/a/text()')).strip(), # 旗舰店'yxq': ''.join(tr.xpath('./div[1]/span/text()')).strip(), # 有效期'img': ''.join(tr.xpath('./div[1]/img/@src')).strip(), # 图片}# 写入数据行with open('ysb.csv', 'a', encoding='utf_8_sig', newline='') as fp: fieldnames = ['name','price', 'price2', 'commpany', 'qjd', 'yxq', 'img'] writer = csv.DictWriter(fp, fieldnames) writer.writerow(tr_data)if len(all_tr) == 60:return Trueprint(f"所有数据获取完成")# 创建csv文件
with open('ysb.csv', 'a', encoding='utf_8_sig', newline='') as fp: header = ['名称','价格', '折扣价', '公司', '旗舰店', '有效期', '图片'] writer = csv.writer(fp) writer.writerow(header)page = 1
url = f"https://dianrc.ysbang.cn/#/indexContent?page=1&pagesize=60&classify_id=&searchkey=%E5%BB%B6%E8%BF%AA%E8%AF%BA%20%E9%98%BF%E6%B3%95%E9%AA%A8%E5%8C%96%E9%86%87%E8%BD%AF%E8%83%B6%E5%9B%8A&onlyTcm=0&operationtype=1&provider_filter=&qualifiedLoanee=0&factoryNames=&specs=&drugId=-1&tagId=&showRecentlyPurchasedFlag=true&onlyShowRecentlyPurchased=false&onlySimpleLoan=false&sn=&deliverFloor=0&purchaseLimitFloor=0&validMonthFloor=0&activityType=%5B%5D&providerSelectList=%5B%5D&factorySelectList=%5B%5D&gradeNameSelectList=%5B%5D&exeStandardSelectList=%5B%5D&specSelectList=%5B%5D&classItem_0=null&classItem_1=null&classItem_2=null&tagName=&_t=1706324500733&_isReplace=true&trafficType=1"
driver.get(url)for i in range(0, 999):if getData(page):page+=1nextBtn = driver.find_element(By.CLASS_NAME, 'pagination-next') # 下一页按钮的位置nextBtn.click() # 点击下一页按钮else:driver.quit()break注意:重要的是,登录成功之后,是使用driver.get(url)打开新的页面,通过html = driver.page_source去取页面数据。而不是使用r = requests.get,html = r.text 去取页面数据。
这篇关于【Python】03快速上手爬虫案例三:搞定药师帮的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







