本文主要是介绍记录job执行批量数据偶发执行失败问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
业务背景
job读取一个中间表数据,执行频率为10min,读取状态未处理数据,同步到第三方系统
代码处理逻辑
1.查询中间表数据,条件:状态未处理 + limit 100
2.循环中处理如下逻辑
A 调用第三方系统,同步状态
B 同步成功,更新中间表处理结果
更新逻辑具体为:
1>根据ID+版本号,再次查询中间表。目的:校验数据存在性+乐观锁
2>更新中间表数据
代码
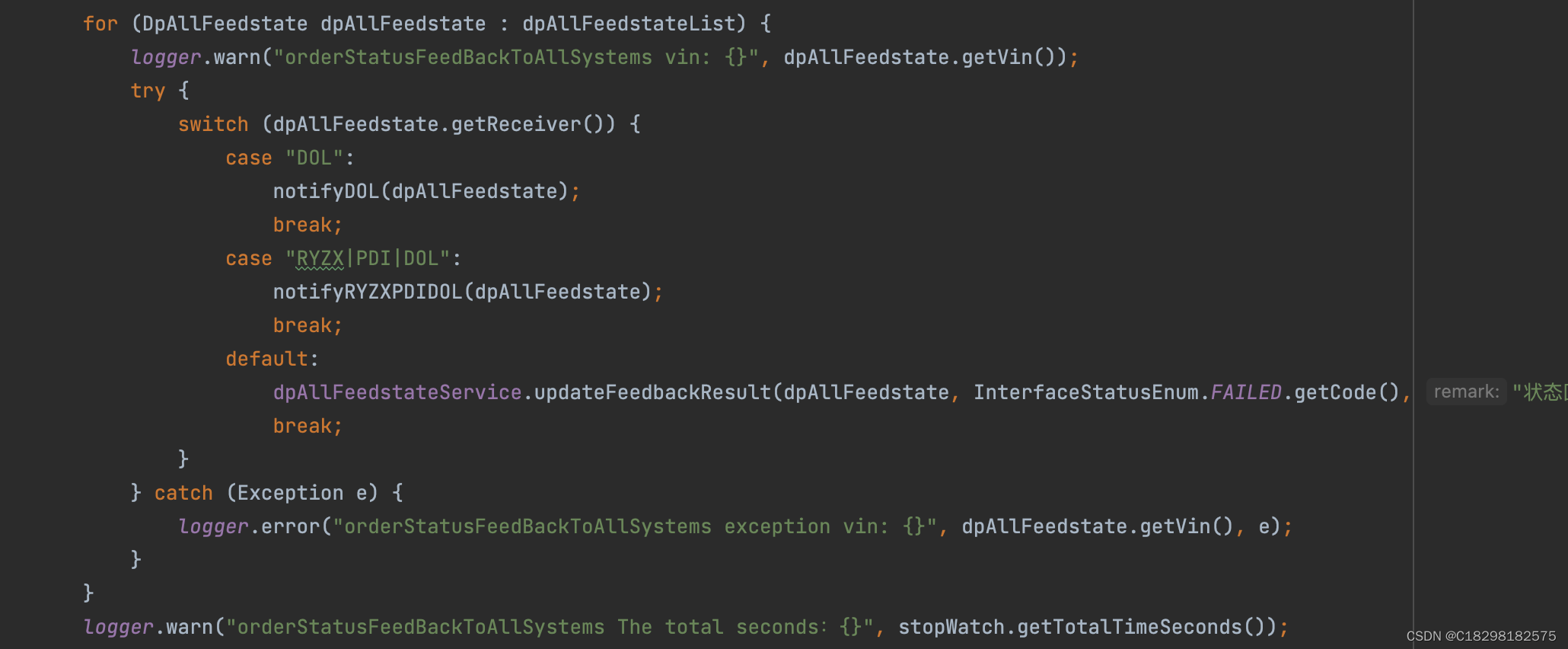
List<DpAllFeedstate> dpAllFeedstateList = dpAllFeedstateService.queryUnprocessedDatas(Integer.valueOf(sysSetting.getValue().trim()), limit);if (CollectionUtils.isEmpty(dpAllFeedstateList)) {return;}try {dpAllFeedstateList.forEach(dpAllFeedstate -> {logger.warn("orderStatusFeedBackToAllSystems vin: {}, uniqueCode: {}", dpAllFeedstate.getVin(), dpAllFeedstate.getUniqueCode());switch (dpAllFeedstate.getReceiver()) {case "DOL":notifyDOL(dpAllFeedstate);break;case "RYZX|PDI|DOL":notifyRYZXPDIDOL(dpAllFeedstate);break;default:dpAllFeedstateService.updateFeedbackResult(dpAllFeedstate, InterfaceStatusEnum.FAILED.getCode(), "状态回传失败,不支持的系统类型", new Date());break;}});} catch (Exception e) {logger.error("orderStatusFeedBackToAllSystems exception dpAllFeedstateList size: {}", dpAllFeedstateList.size(), e);} String keyWords = dolOrderStatusDTO.getVin() + ";" + dolOrderStatusDTO.getUniqueCode() + ";" + dolOrderStatusDTO.getCommandField();String responseJsonStr = DataTransportUtil.requestDolESB(targetServiceId, Constant.XYX_DPS_ID, esburl, keyWords, dataMap, 5000, 5000);ServiceResponse serviceResponse = DataTransportUtil.parseRouteResponse(responseJsonStr);if (Boolean.TRUE.equals(serviceResponse.isSuccess())) {dpAllFeedstateService.updateFeedbackResult(dpAllFeedstate, InterfaceStatusEnum.SUCCESS.getCode(), "状态回传DOL成功", new Date());} else {dpAllFeedstateService.updateFeedbackResult(dpAllFeedstate, InterfaceStatusEnum.FAILED.getCode(), "状态回传DOL失败:" + serviceResponse.getDesc(), new Date());}@Overridepublic int update(DpAllFeedstate entity) {DpAllFeedstate dpAllFeedstate = dpAllFeedstateDao.selectById(entity);if( dpAllFeedstate == null ){throw new MallException("-1000000","状态反馈(dp->all)您要更新的数据不存在或版本号不正确,请刷新后操作!");}entity.setUpdateDate(new Date());if (CurrentUserUtils.getCurrentUser().getMaxusUserId()!=null){entity.setUpdateBy(CurrentUserUtils.getCurrentUser().getMaxusUserId().toString());} if(null == entity.getVersion()){entity.setVersion(1);}else {entity.setVersion(entity.getVersion()+1);}return dpAllFeedstateDao.update(entity);}问题
1.执行频率不正确
正常执行频率10min,从凌晨到早上6点,执行时间间隔近1小时才执行,不是10min。
查看日志,发现只有job开始时日志,没有执行完成日志

2024-01-29 02:13:26.427 ERROR [Thread-27140] com.alibaba.druid.pool.DruidDataSource.?:? -discard connection
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
The last packet successfully received from the server was 7,208,946 milliseconds ago. The last packet sent successfully to the server was 7,208,946 milliseconds ago.
at sun.reflect.GeneratedConstructorAccessor267.newInstance(Unknown Source)
原因
看频率,推测xxl-job问题,但是只有开始日志没有结束日志,推测是代码问题
2.任务堆积
实际调度时间正常,但是任务没有被执行,大量任务堆积,
且查看日志,发现只有job开始时日志,没有执行完成日志
且只有少数一两个任务存在堆积情况,其他job都是正常执行

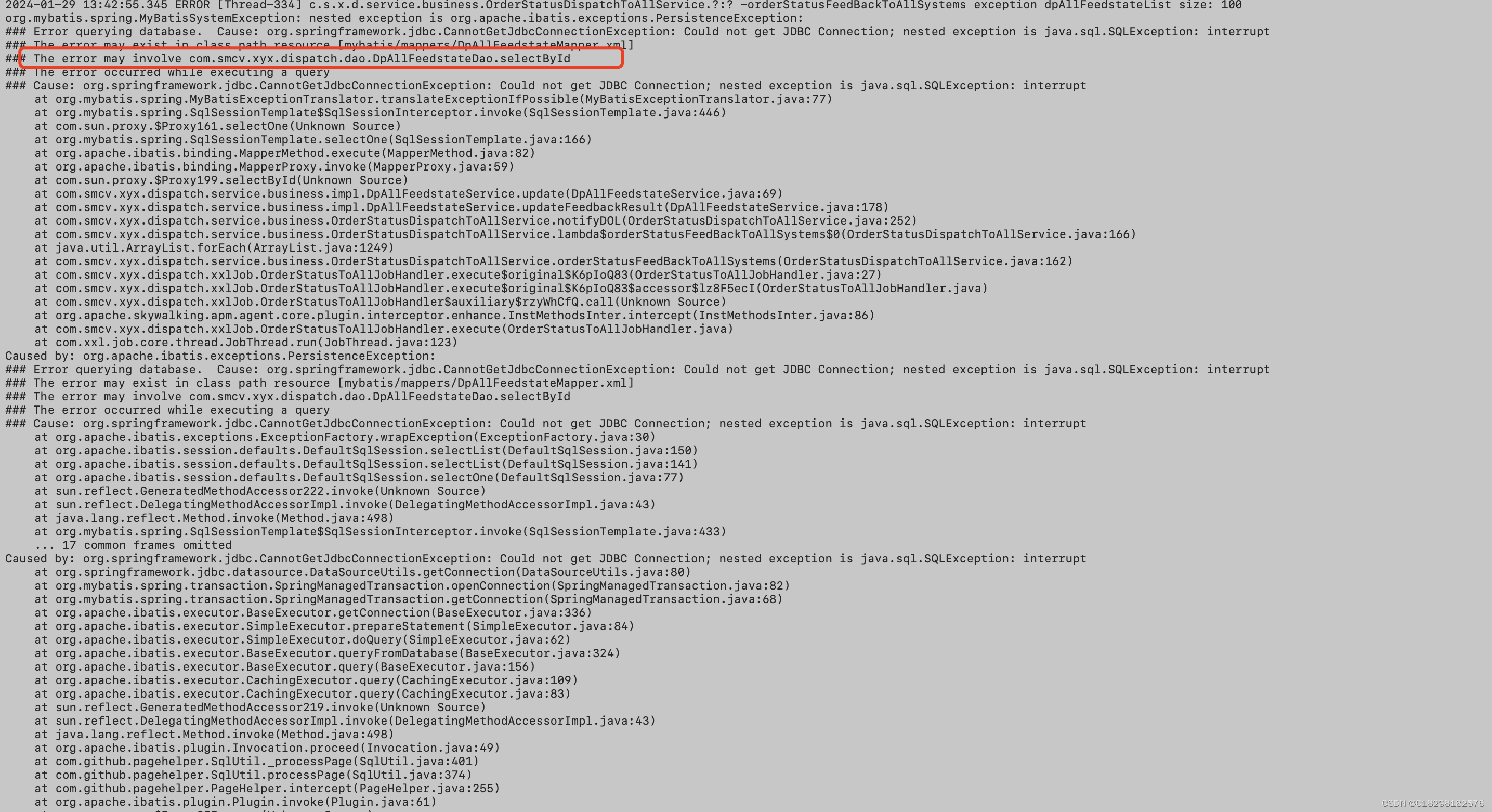 The error may involve com.smcv.xyx.dispatch.dao.DpAllFeedstateDao.selectById
The error may involve com.smcv.xyx.dispatch.dao.DpAllFeedstateDao.selectById
### The error occurred while executing a query
### Cause: org.springframework.jdbc.CannotGetJdbcConnectionException: Could not get JDBC Connection; nested exception is java.sql.SQLException: interrupt
为什么报上面错误,这个回答比较像,那为什么最大连接数达到最大
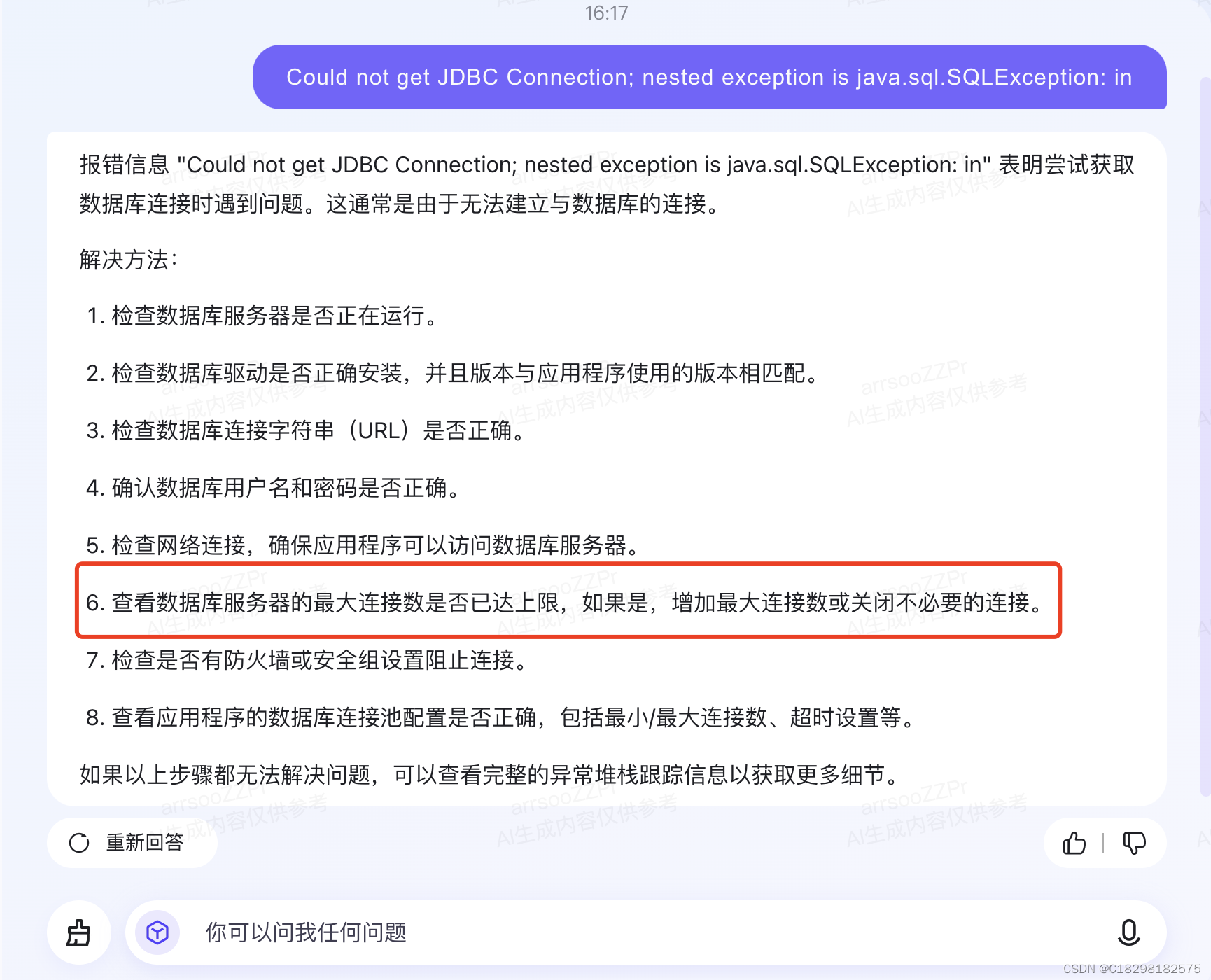
再次梳理代码逻辑
100条数据循环处理,更新时先做了查询,然后更新,一条数据处理占用两个连接,100条数据forEach处理,此时占用连接,可能大于最大连接。(日志报错查询时无法获取数据库连接)
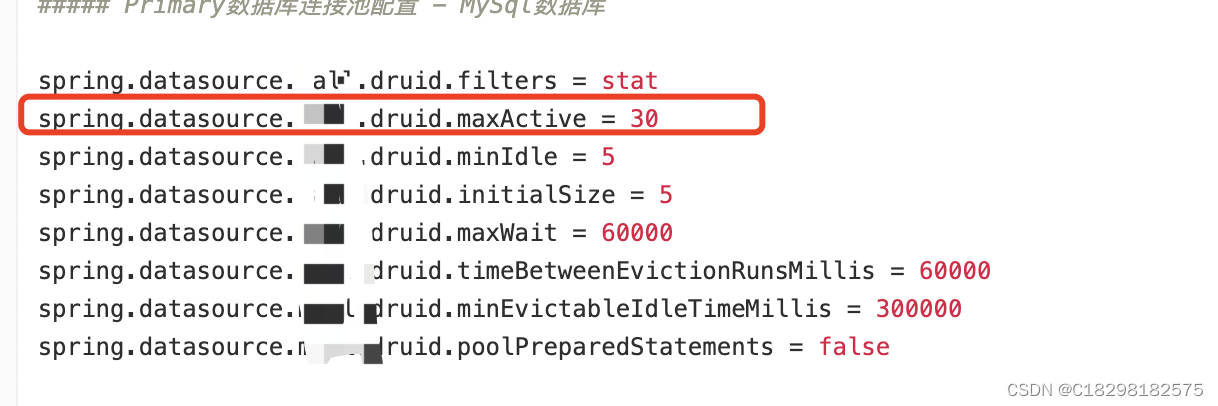
那最大连接是多少,如下配置30吗,严重怀疑不是,且这个最大连接数,只是一个数据库实例下某个数据库的配置,每个项目都有自己的配置,意思是一个项目他的最大连接数是30
也不对吧,这么多接口,稍微比较耗时查询,不很容易就达到最大了。
原因
结合以上信息,推测是业务代码问题
解决方案
1.减少批处理量,由100改成20
2.增加job执行频率,之前100条数据,执行时间2-3min,改成3min执行一次
3.循环方式,java8 forEach改成 for(),避免线程逻辑中异常信息被吞掉
4.优化try catch逻辑,缩小粒度,针对每一条数据catch异常
这篇关于记录job执行批量数据偶发执行失败问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






