本文主要是介绍【过程发现算法1】-Inductive Miner(归纳式挖掘),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Inductive Miner(归纳式挖掘)是目前已有的过程发现算法中最先进的一种算法,在2013年由sander提出,他是一种基于过程树的算法,并在上面衍生了各种变体算法,比如Inductive Miner-Infrequency, Inductive Miner-Lifecycle等,接下来,我们就详细地介绍这个基本的Inductive Miner算法。
1.背景介绍
| 发现算法 | 代表性算法 | 可重新发现性 | fitness | soundness | 其他 |
| 基于活动顺序关系 | α算法及其变体 | 相对小的日志的同构重发现 | X | X | |
| 基于语义的技术 | the language-based region miner,the state-based region miner,ILP miner | X | X | X | |
| 基于频率的技术 | Heuristics miner | - | X | X | |
| 基于抽象的技术 | Fuzzy Miner | X | X | X | |
| Genetic process discovery algorithms | - | - | V | 不能保证在有限的时间内运行 |
现有的挖掘算法不能保证在有限的时间内(没有死锁和其他异常)模型是fitting(表示所有的行为)和soundness(合理的)。
不合理的模型可以通过模拟退火来修复,使其变得健全,尽管不保留对给定日志的拟合性。不拟合的模型可以通过添加子过程来修复,使其变得拟合,尽管不能保证其可靠性。
因此,需一个更综合的方法保证合理性和拟合度,并且在有限的时间内得到块结构(block-structured)模型。IM算法应用而生。
2.思想概述

上图中的每个小圆圈代表每个子过程,四种运算符的详细规则如下:
排他运算符的规则为一个子过程A与另一个子过程B两个之间没有任何关联,一个子过程A中的活动的后继活动不能在另一个子过程B中,一个子过程B中的活动的后继活动不能在另一个子过程A中,两者互不关联。
顺序运算符的规则为从一个子过程A到另一个子过程B有出边,但是无入边,两者总体上只有一方到另一方。
并发运算符的规则为一个子过程A既有到另一个子过程的出边,也有另一个子过程B到这个子过程A的入边。两者彼此交叉,并行存在。
循环运算符的规则为一个活动从子过程A出发,到达另一个子过程B中,再由B重现回到A。总结为起于此终于此。
3. 举例说明
假设存在事件日志 L = {< a, b, c >, < a, c, b >, < a, d, e >, < a, d, e, f, d, e >}.
(1).将事件日志转化为直接跟随活动图(DFG)

(2).使用四种切分运算符对上述的DFG进行拆分,拆分过程如下:

用过程语言可表示为:
L = {<a, b, c >, < a, c, b >, < a, d, e >, <a, d, e, f, d, e >},依次进行的操作如下:
1.SEQUENCESPLIT(L,({a},{b, c, d, e, f})) =[L1={< a >},L2={<b, c >, <c, b >, <d, e >, <d, e, f, d, e >}]
2.EXCLUSIVECHOICESPLIT(L2,({b, c},{d, e, f})) = {L3=<b, c>, < c, b >},{L4=< d, e >, <d, e, f, d, e >}]
3.PARALLELSPLIT(L3,({b},{c})) ={<b >},{<c >}
4.LOOPSPLIT(L4,({d, e},{f})) = {<d, e >},{< f >}
(3).根据上述过程转化为过程树语言如下:
发现模型: M= →(a, X(∧(b, c), Q (→ (d,e),f)))
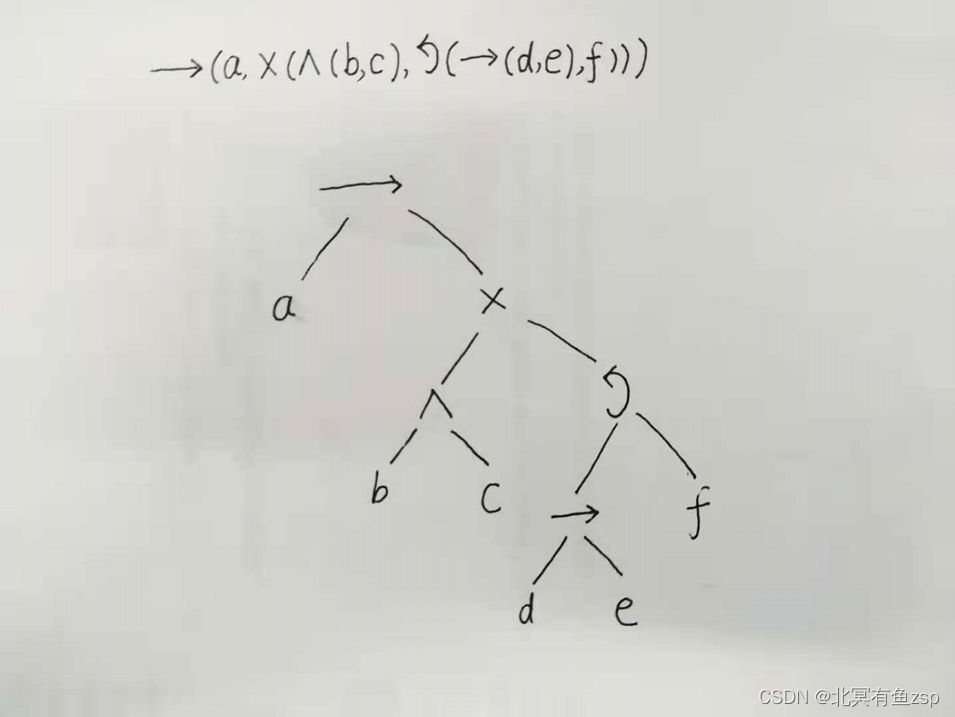
(4).过程树转化为Petri网
四种基本形式的对应转化:
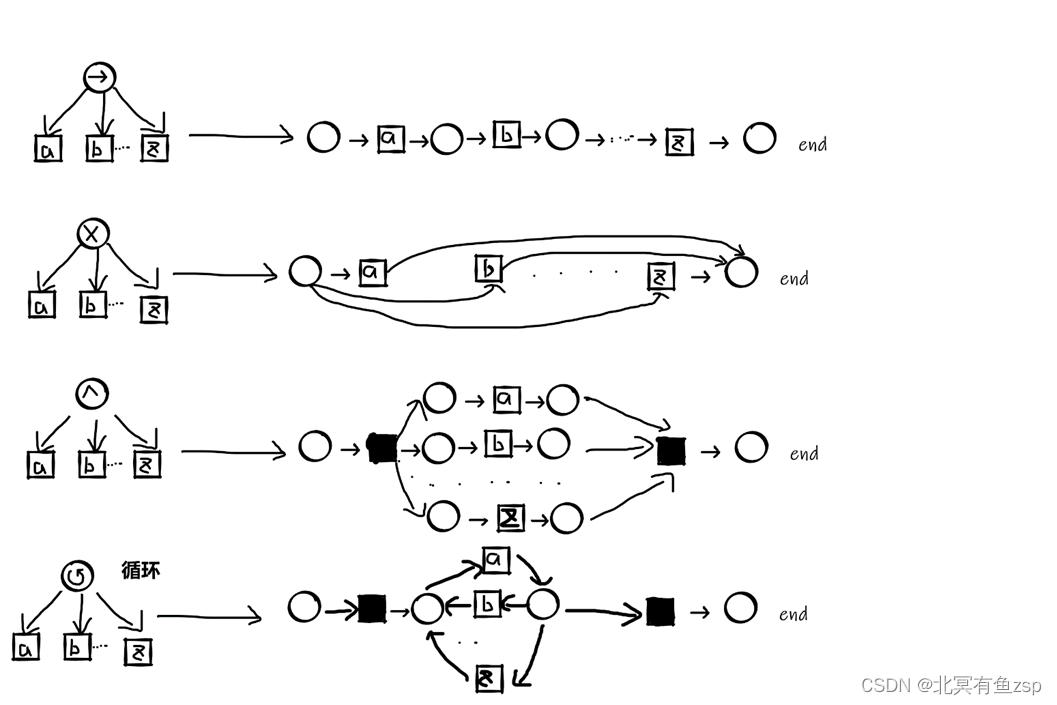
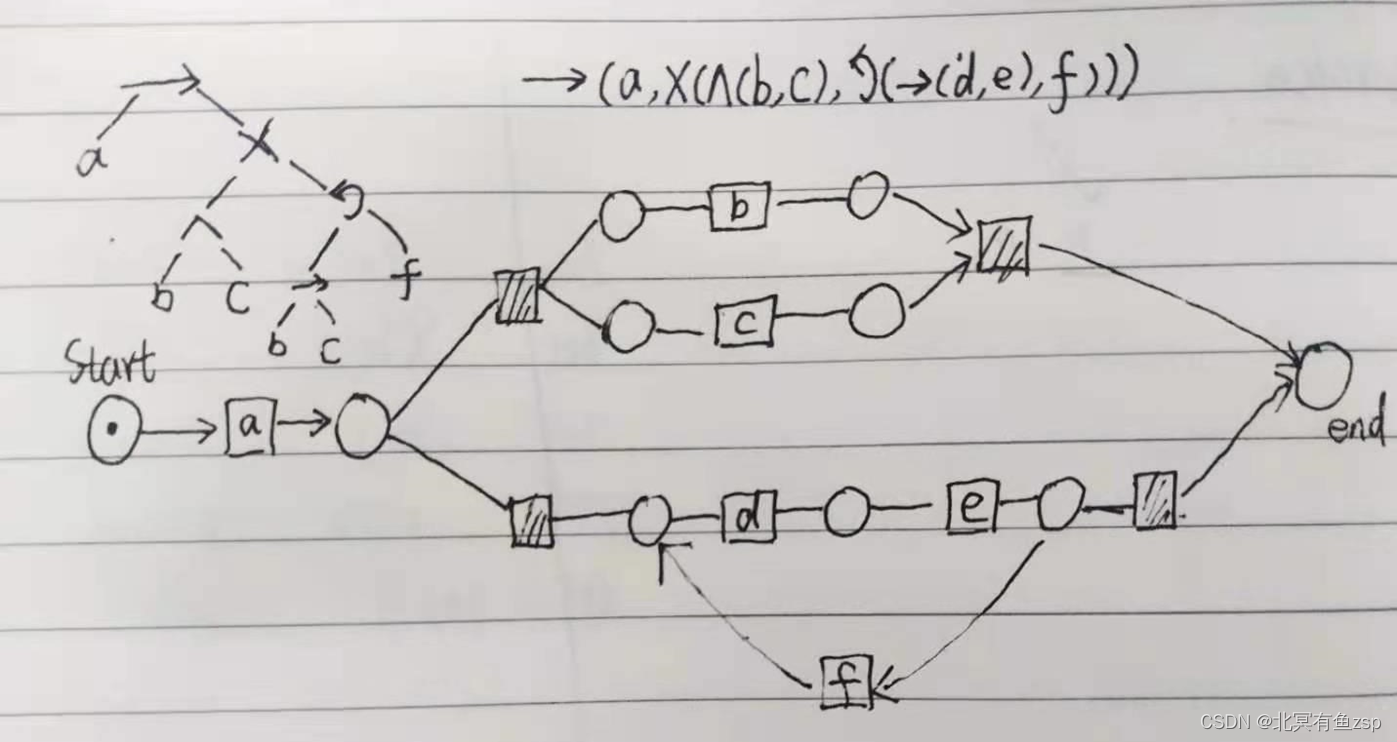
按照以上四种基本规则,最终得到的Petri网结果如下:
4.工具插件
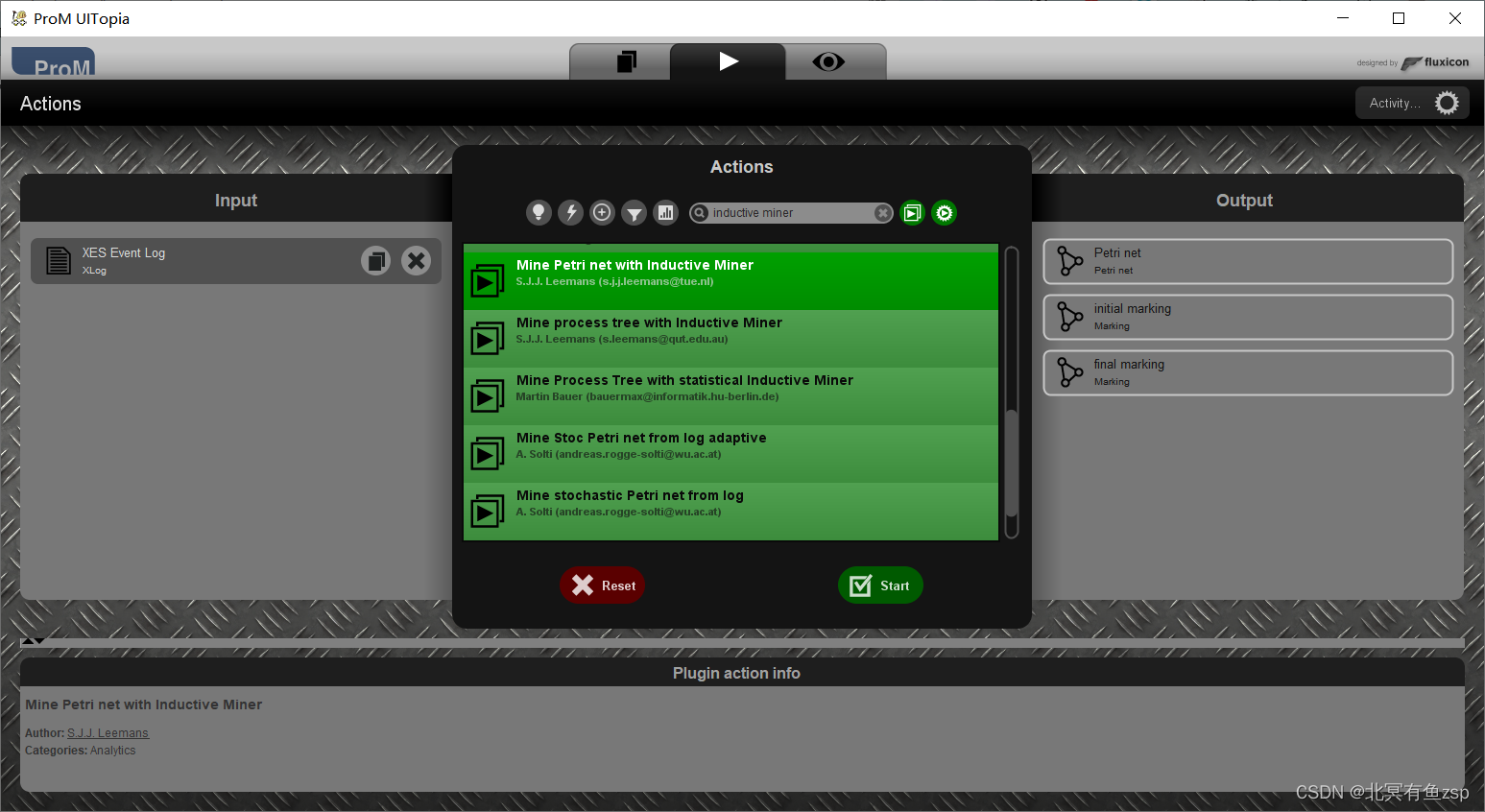
(1)使用prom6运行的插件svn下载地址:prom - Revision 46111: /Packages/InductiveMinerDeprecated/Trunk (tue.nl)
运行插件界面图:
(2)使用pm4py调用Inductive Miner算法的链接地址:
PM4Py - Process Mining for Python (fraunhofer.de)
4.总结
由Inductive Miner得到的过程模型能够完全拟合事件日志中的行为,但还存在以下不足:
(1)没有考虑事件日志中直接跟随活动关系的频次;
(2)在过程树转化为Petri网的过程中,无声变迁(上图中的黑色方块)数量增多,导致过程模型的精度降低。
参考文献:LEEMANS S J J, FAHLAND D, VAN DER AALST W M P. Discovering block-structured process models from event logs-a constructive approach[C]//International conference on applications and theory of Petri nets and concurrency. Berlin, Germany: Springer-Verlag, 2013: 311-329.
下一讲将针对Inductive Miner存在的不足,介绍其算法的变体-Inductive Miner-infrequent。
如需进行相关的了解或者交流,欢迎私信或者加入QQ群:

这篇关于【过程发现算法1】-Inductive Miner(归纳式挖掘)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









