本文主要是介绍每日coding 2846. 边权重均等查询 236. 二叉树的最近公共祖先 35. 搜索插入位置 215. 数组中的第K个最大元素 2. 两数相加,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2846. 边权重均等查询
xs,已放弃,考到直接寄
236. 二叉树的最近公共祖先
236. 二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
示例 1:
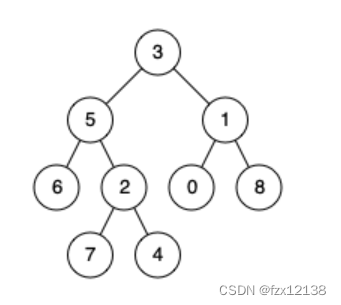
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出:3 解释:节点5和节点1的最近公共祖先是节点3 。
示例 2:
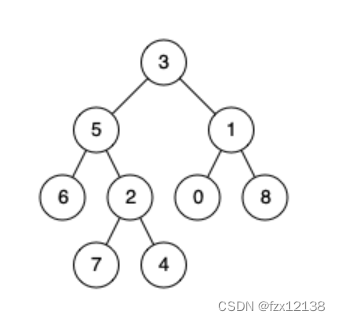
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 输出:5 解释:节点5和节点4的最近公共祖先是节点5 。因为根据定义最近公共祖先节点可以为节点本身。
示例 3:
输入:root = [1,2], p = 1, q = 2 输出:1
这道题目的话用dfs做就行了,它首先通过调用dfs方法来构建从根节点到节点p和q的路径。然后,它比较这两个路径,并从第一个不匹配的节点开始向前查找,直到找到一个匹配的节点。这个节点就是最近公共祖先。
class Solution {
public:TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {vector<TreeNode*> vec1, vec2;dfs(root, p, vec1); dfs(root, q, vec2);TreeNode* ans = nullptr;for (int i = 0; i < min(vec1.size(), vec2.size()) && vec1[i] == vec2[i]; i++){ans = vec1[i];} return ans;}bool dfs(TreeNode* cur, TreeNode* t, vector<TreeNode*>& path) {if (!cur) return false;path.push_back(cur);if (cur == t || dfs(cur->left, t, path) || dfs(cur->right, t, path)) {return true;} else {path.pop_back();return false;}}
};35. 搜索插入位置
35. 搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
示例 1:
输入: nums = [1,3,5,6], target = 5 输出: 2
示例 2:
输入: nums = [1,3,5,6], target = 2 输出: 1
示例 3:
输入: nums = [1,3,5,6], target = 7 输出: 4
提示:
1 <= nums.length <= 104-104 <= nums[i] <= 104nums为 无重复元素 的 升序 排列数组-104 <= target <= 104
二分法来做,但是记得二分法需要已经排序好的数组,然后注意边界。
class Solution {
public:int searchInsert(vector<int>& nums, int target) {int n = nums.size(), left = 0, right = n - 1, mid = 0;while(left <= right){mid = (left + right) / 2; if(nums[mid] < target) left = mid + 1;else right = mid - 1;}return left;}
};215. 数组中的第K个最大元素
215. 数组中的第K个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入: [3,2,1,5,6,4], k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6], k = 4
输出: 4
提示:
1 <= k <= nums.length <= 105-104 <= nums[i] <= 104
这里直接借助优先级队列,这里需要出一期排序的总结,应该用堆排序的。
class Solution {
public:int findKthLargest(vector<int>& nums, int k) {priority_queue<int, vector<int>, greater<int>> pq;for (const auto& n : nums) {if (pq.size() == k && pq.top() >= n) continue;if (pq.size() == k) pq.pop();pq.push(n);}return pq.top();}
};
2. 两数相加
2. 两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:
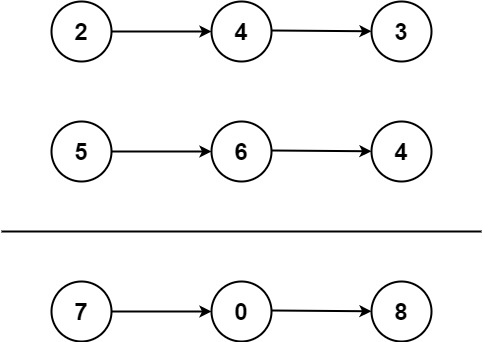
输入:l1 = [2,4,3], l2 = [5,6,4] 输出:[7,0,8] 解释:342 + 465 = 807.
示例 2:
输入:l1 = [0], l2 = [0] 输出:[0]
示例 3:
输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9] 输出:[8,9,9,9,0,0,0,1]
提示:
- 每个链表中的节点数在范围
[1, 100]内 0 <= Node.val <= 9- 题目数据保证列表表示的数字不含前导零
这道题目主要是利用一个进位标志来进行运算,新建链表。
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {ListNode* dummyHead = new ListNode(0);ListNode* cur = dummyHead;int forward = 0, tmp = 0;while(l1 || l2 || forward){forward += (l1 ? l1->val : 0) + (l2 ? l2->val : 0);tmp = forward;forward %= 10;cur = cur->next = new ListNode(forward);forward = tmp / 10;if(l1) l1 = l1->next;if(l2) l2 = l2->next;}return dummyHead->next;}
};这篇关于每日coding 2846. 边权重均等查询 236. 二叉树的最近公共祖先 35. 搜索插入位置 215. 数组中的第K个最大元素 2. 两数相加的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





