本文主要是介绍数据驱动在转转客服工单系统中的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
客服工单系统是客服解决用户实际问题、处理日常工作最常用的系统。为有效辅助客服的工作,系统需要及时提供用户、商品和订单等信息。同时,客服工单的创建、流转和处理,也需要各种类型表单的操作。所以基础信息的展示和交互、表单的展示和操作,对于客服工单系统至关重要。本文就为大家介绍,在转转客服工单系统中,我们是如何通过数据驱动的方式解决这类问题的。
基础信息
展示形式
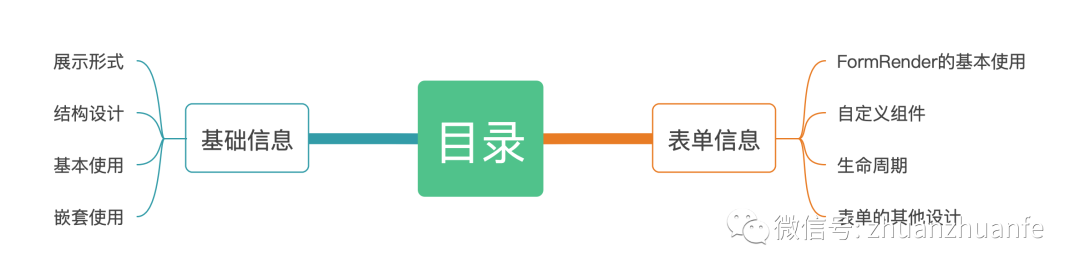
这里以工单详情为例,工单详情以模块的方式,提供包括基础信息、用户信息、订单信息等重要的数据,如下图:
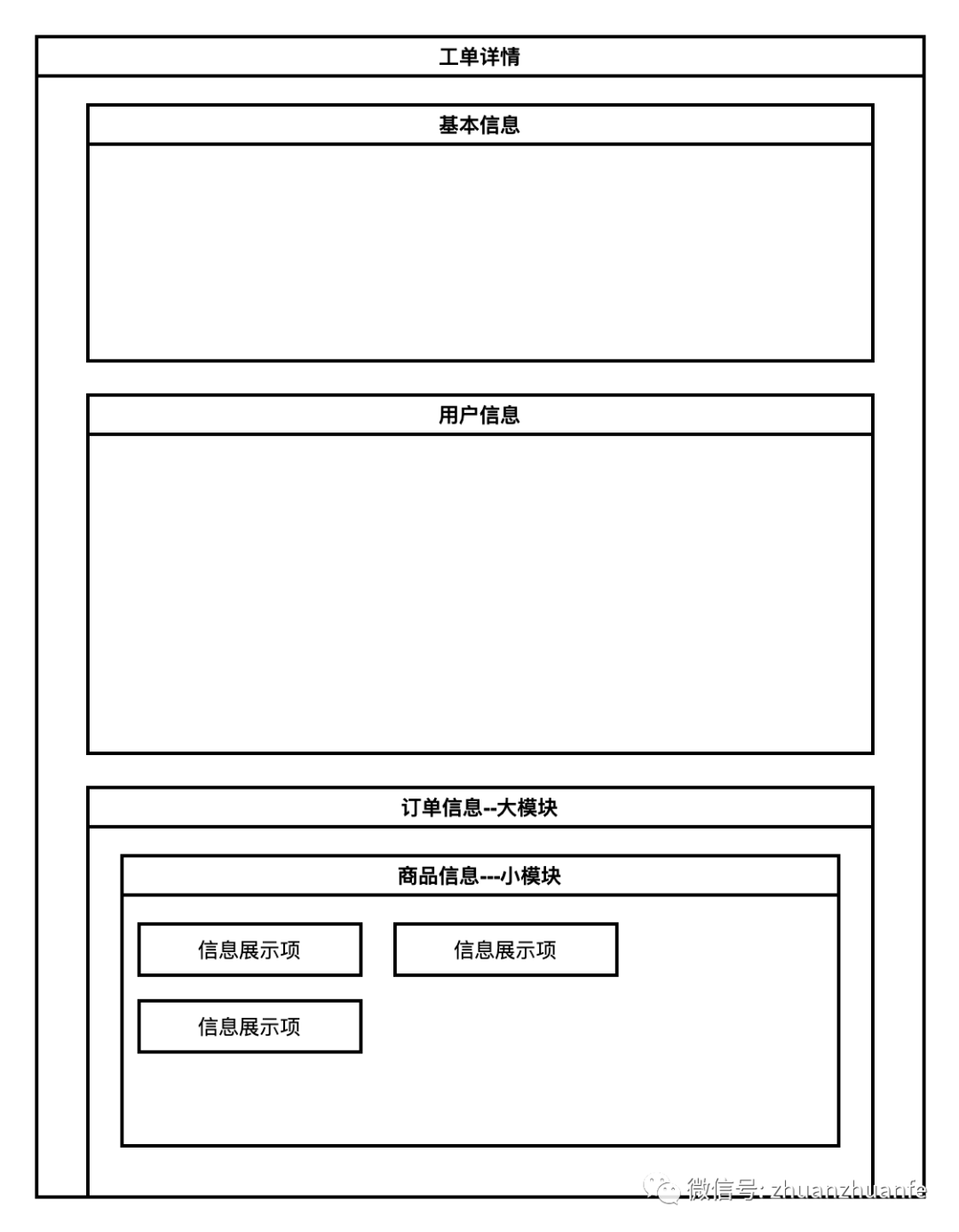
每一个模块都是由大量不同的类型信息平铺展示,如下:

这些信息数据量和类型繁多,数据字段跟公司的业务有关,数据类型涵盖从最简单的文本展示、链接跳转,到图片预览、弹窗交互等,这些不可能由前端单独一一去做处理。所以我们通过归类和抽象,将数据格式进行统一化、对共性组件进行抽离,交由不同的组件处理。在介绍基本使用之前,先看下整体的结构设计。
结构设计
四个层次
工单详情的每一个大模块都可以分为四个层次,分别为:数据共享层、业务层、抽象层、数据展示层。
每一个业务层都是一个可折叠的面板,未展开前都只展示简略信息。其数据均由数据共享层提供,展开后可通过请求共享的 url,获取详细数据。

这里控制请求逻辑的就是抽象层。 其中包括了一个展开后自动请求的 hook---useAbstract,以及一个根据 useAbstract 返回值控制展示的 Abstract 组件,获取到的数据最终传给数据展示层--DetailInfoArea。
// useAbstract
const [infoDataList, isEmptyInfo, loading] = useAbstract({ isShow, initShowData })
// 这里infoDataList为返回数据,isEmptyInfo用于控制展示,loading是加载状态// Abstract
<Abstract infoDataList={infoDataList} isEmptyInfo={isEmptyInfo} isLoading={loading}></Abstract>// DetailInfoArea
{!isEmptyInfo? infoDataList.filter((item) => Array.isArray(item.data) && item.data.length).map((infoItem, index) => {return (<Card key={index}><DetailInfoAreaorderId={orderId}bussinessType={bussinessType}data={infoItem.data}/></Card>)})
: null}最终通过一个 type 和组件的映射匹配出相应的组件。
import PopInfo from '../PopUp/PopInfo'
import LinkAirPlane from '../FormComponent/LinkAirPlane'
import Text from '../FormComponent/Text'
import countDown from '../FormComponent/CountDown'
…… // 其他组件export default {// Pop类组件PopInfo,PopDrawer,// link类组件LinkAirPlane,// 其他数据展示组件Text,countDown,……
}三类组件
通用数据展示组件分为三大类:pop 类 、 link 类、其他类型组件。
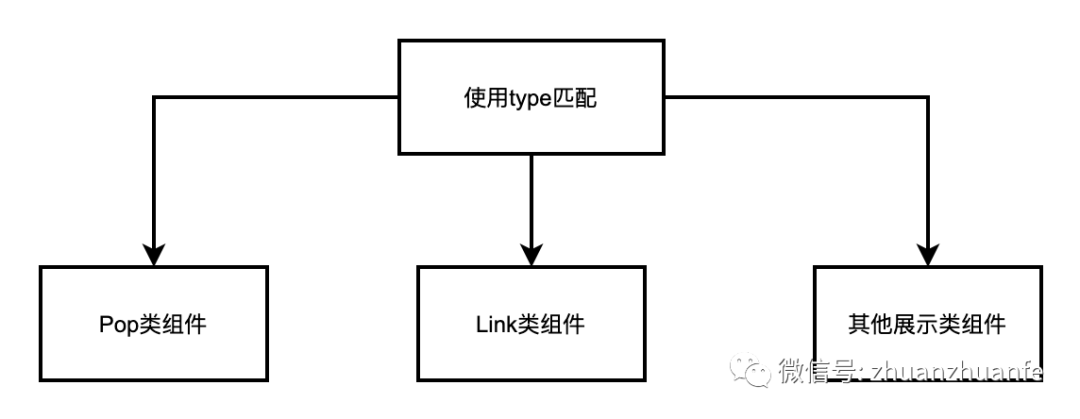
Pop 类组件:用于点击后弹窗/抽屉展示数据或操作--常用做其他数据展示的容器
Link 类组件:由于点击后跳转
其他类型组件:基础展示 text、table 数据、图片/视频展示...
具体组件类型、名称和作用如下:
| 归属类型 | 组件名称 | 作用 |
|---|---|---|
| Pop 类组件 | PopInfo | 通用弹窗信息展示 |
| PopIframe | 通用弹窗嵌入页面展示 | |
| PopForm | 通用弹窗表单组件 | |
| PopDrawer | 抽屉信息展示 | |
| Link 类组件 | LinkAirPlane | 带有特殊 UI 样式的链接 |
| LinkGroup | 多链接 | |
| Link | 单一链接 | |
| 其他类型组件 | Text | 纯文本项展示,最基础的展示 |
| AudioPlayInfo | 音频播放 | |
| SimpleTable | 表格数据展示 | |
| ClickReplace | 脱敏数据展示,点击查看全部 | |
| ImgHoverPop | 图片展示及预览 | |
| CountDown | 倒计时,用于工单某些流程的计时 |
数据结构
以下为每一个数据展示项的基本数据结构
[{"type": "", // 用于匹配系统中内置的组件"label": "", // 标识数据项的标题"value": "", // 标识数据项的值"noAuth": "", // 没有该项查看权限的标识"extInfo": { // 额外的信息,可以放入href、formType字段从而达到嵌套组件的形式....}}...]基本使用
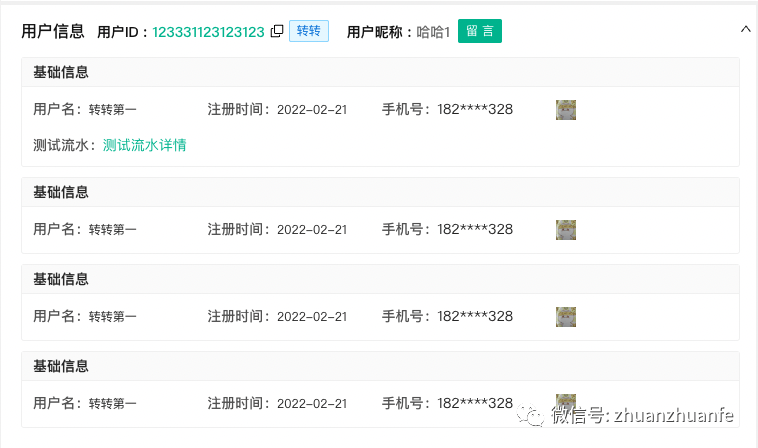
案例 1:展示用户的基础信息,其中包括用户名、注册时间、手机号、头像以及一个测试流水表格
{"respData":[ // 对应最外层模块内容{"label":"基础信息", // 模块的名称"data":[ // 模块中信息项:以label--value的形似展示{"label":"用户名","value":"转转第一""noAuth":false},{"label":"注册时间","value":"2022-02-21","noAuth":false},{"label":"手机号","value":"182****328","type":"ClickReplace","extInfo":{ // extInfo用于放一些组件需要的特殊参数"params":{"uid":"12345678910233445"},"url":"url"},"noAuth":false},{"label":"","value":"https://abababab.jpeg","type":"ImgHoverPop","extInfo":{"popWidth":"200px"},"noAuth":false},{"label":"","value":"测试流水","type":"SimpleTable","extInfo":{"data":[// 表格数据],"columns":[// 表格列配置]},"noAuth":false}],"noAuth":false}],"respCode":"0"
}展示内容如图所示
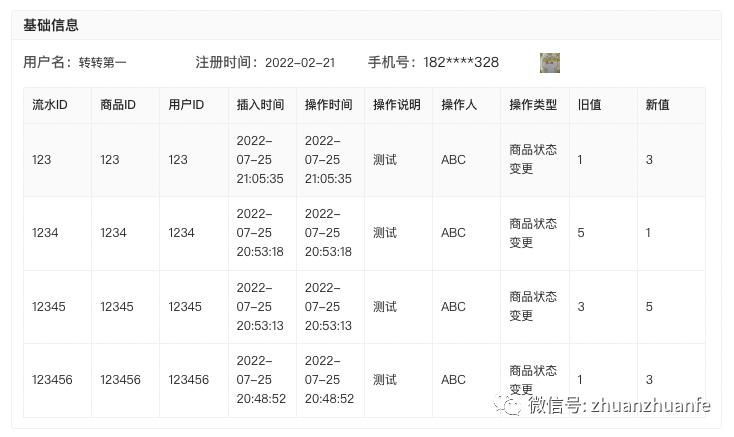
本例前两个字段使用的默认的渲染类型,只展示单一信息
手机号和头像展示则匹配了内部的通用组件:
手机号采用了脱敏的方式,只有在点击之后才会加载全手机号,属于单一数据展示类组件
第三项使用了缩略图的展示形式,点击后会对图片进行预览,属于单一数据展示类组件

最后的流水表格使用内部的SimpleTable组件展示
嵌套使用
案例 2:我们在基础信息部分需要展示一个流水,以弹窗的方式实现。这里就要通过嵌套的方式进行处理。
这里涉及到的弹窗组件就是上文所说的 Pop 类组件,如下所示:
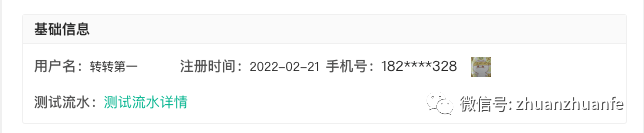
这里使用的是 PopInfo,extInfo 中增加 url 表示弹窗的内容通过 getUserFlowList 获取,因此点击“测试流水详情”后会请求该接口。
{"label":"测试流水","value":"测试流水详情","type":"PopInfo","extInfo":{"url":"getUserFlowList"},"noAuth":false
}获取接口后,其返回数据既返回了数据 data,也返回了表格的列配置。
{"respData":{"dataGroup":[{"type":"SimpleTable","extInfo":{"data":[// ......],"columns":[// ......]}}]},"respCode":"0"}此处弹窗中的内容为流水信息,使用表格来展示,type 为案例 1 所用的 SimpleTable 组件。
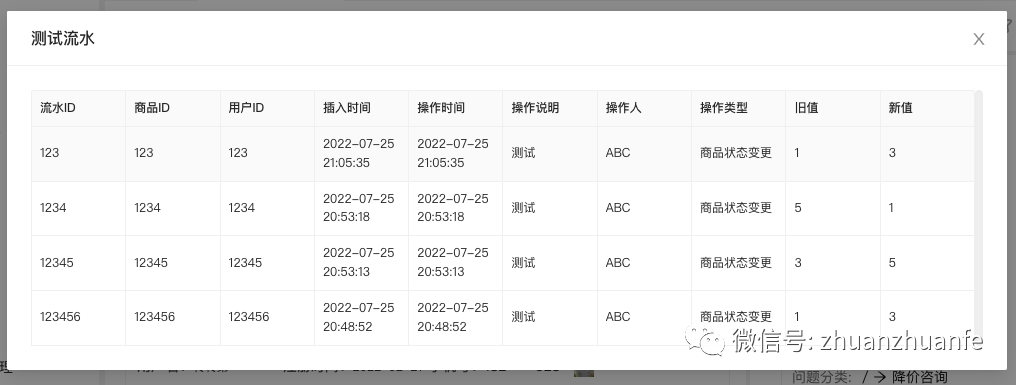
对比一下案例 1 中直接使用 SimpleTable,此处嵌套使用时,只需通过数据获取接口来衔接弹窗和内部数据的,其返回数据的结构都是保持一致的,这也是此设计可以嵌套使用的根本原因。
接下来将焦点转移到工单系统中的表单信息。表单在工单系统的地位用“灵魂”形容可能也不为过,因为客服解决用户问题的过程,涉及到记录问题内容、问题分类、沟通细节、处理方式、工单流转等,这些操作都依赖表单的能力。所以一套强大的表单处理系统对实现工单系统流转起到关键作用,下面介绍由数据驱动的 FormRender 在工单系统中的应用。
表单信息
在工单系统,我们使用 FormRender 处理表单。为什么是 FormRender,而不是普通的 Form?
1、同基础信息类似,表单中的字段非常多,包含输入框、单选框、多选框、下拉框、日期选择、时间选择、级联等。
2、字段本身有很多的配置项,如校验规则、默认值、联动信息等,所以需要一种强约束的数据格式保证表单字段的正常渲染和交互。
3、针对不同的用户问题,客服创建的工单需要由不同的字段组合来承载信息,如果没有统一的表单管理,维护效率不容乐观。
FormRender(后面简称 FR) 是一个通过 JSON Schema 生成标准 Form 的渲染引擎,也是一站式表单方案,拥有比较强大的功能,可以满足复杂的表单需求。接下来看看 FR 如何运用在工单系统中。
FormRender 的基本使用
比较下面的代码
// input第一种写法
<Form><Form.Itemrequiredlabel={'这是输入框'}<Input placeholder={'请输入~'} className={style['my-input']}/></Form.Item>
</Form>// formRender的写法
const form = useForm()
const renderSchema = {displayType: 'row',labelWidth: 130,type: 'object',properties: {content: {title: '这是输入框',placeholder: '请输入~',type: 'string',required: true,"props": {className: style['my-input'],}}}
}
<FormRender schema={renderSchema} form={form} />最终的效果如下:

我们可以看到,其实 FR 是借助schema对表单做了相应的配置化。
FR 是如何通过 schema 渲染指定的组件呢?FR 属性 type,描述组件的值的数据类型,属性 format,用来描述输入框的格式,它与属性 type 一起可以判断使用哪个组件来渲染,以及校验表单数据。
内置组件与 scheme 的默认匹配规则为:
export const mapping = {default: 'input',string: 'input',array: 'list',boolean: 'checkbox',integer: 'number',number: 'number',object: 'map',html: 'html','string:upload': 'upload','string:url': 'url','string:dateTime': 'date','string:date': 'date','string:time': 'time','string:textarea': 'textarea','string:color': 'color','string:image': 'imageInput','range:time': 'timeRange','range:date': 'dateRange','range:dateTime': 'dateRange','?enum': 'radio','?enum_long': 'select','array?enum': 'checkboxes','array?enum_long': 'multiSelect','*?readOnly': 'html',
};除了有以上内置组件外,FR 还支持自定义组件,通过 widget 属性(将在下一节中介绍)注入。
另外,FR 通过 rules 属性来配置对表单的校验规则,通过 props 属性透传给组件,用来扩展字段,值得强调的是 FR 支持所有 antd 组件库支持的展示。
自定义组件
工单系统目前支持的表单类型包括:文本框、文本域、单选、多选、下拉、级联、日期选择、时间选择,大部分都可由 FR 的内置组件支持,但有些特殊的需求,FR 不能很好的支持,级联组件就是其中一个。
如何在 FR 中写一个自定义组件?
// 引入自定义组件
import CascaderSingle from './CascaderSingle'
// 定义schema数据
const renderSchema = {displayType: 'row',labelWidth: 130,type: 'object',properties: {cascader: {title: '城市',type: 'string',widget: 'CascaderSingle' // widget指定自定义组件名称"props": { // 定义渲染数据options: [{id: '1001',name: '北京',children: [{id: '10011',name: '海淀',children: [{id: '100111',name: '好地方'}]},{id: '10011',name: '朝阳'}]}]}}}}
// 将自定义组件,通过widgets通知FR渲染
<FormRender widgets={{ CascaderSingle }} schema={renderSchema} form={form} />渲染效果如下:

总结以下几点:
自定义的组件,需要支持 value/onChange 这两个 props,用于双向绑定;
通过 widgets 给 FR 注册自定义的组件;
设置对应的 schema 数据,包括 widget 属性和自定义组件接受的 props(上述例子中的 options)
一般自定义组件,通常是解决特定的场景需求,如特殊 UI、特定的组件、异步加载数据的组件等。在下一节会介绍异步加载数据的场景。
生命周期
对于 FR 来说,生命周期是指渲染和提交数据的时机,根据官网介绍,包括 onMount、beforeFinish 和 onFinish。
onMount 用于加载初始数据;
beforeFinish 用于提交表单前的服务器校验;
onFinish 是获取表单数据和校验信息。
onMount 需要特别强调的是,它是指表单首次加载时执行,而且 schema 数据不能为空(undefined、null 和{}均表示空数据)。如果初始的 schema 数据是由服务器异步加载,那么 onMount 一般无法满足需求,官方则推荐使用 react 的 componentDidMount 或类似的 hooks 来加载。
在工单系统中,绝大多数的表单初始数据都是由接口获取,所以一般很少用到 onMount。但有一个例外,其中有一个级联表单,虽然初始数据是非空 schema 数据(一般是简单的配置项),但真正的 options 数据是由单独的接口异步获取,这时 onMount 就派上用场了,因为 onMount 还能用来通过异步获取数据的方式进一步补充 schema。
const onMount = () => {//通过接口异步获取数据apiQueryAllRootCause().then((res) => {const _data = res?.dataList?.map((item) => {return { ...item, name: item.causeName, key: item.id, isLeaf: item.isEnd == 1 }})//获取需要补充schema的字段的路径const schemaPath = getSchemaPath(infos?.formData?.find((it) => it.fieldType == type))//补充schema数据form.setSchemaByPath(schemaPath, {props: {options: handleGetFaqData(_data)},enumArea: _data})})}<FormRenderwidgets={widgets}schema={renderSchema}form={form}onMount={onMount}/>这里用到了 FR 的 setSchemaByPath 方法,它的目的就是对指定路径修改 schema。由于 schema 是有一定结构格式的数据,为了方便快速定位具体某个元素,用 path 来表示该元素相对表单数据的位置。我们看官网给的例子:
const formData = { x: [{ y: { z: 1 } }] };
那么 z 元素的 path 是 x[0].y.z。所以在工单系统复杂的表单中,要对指定的表单元素修改 schema,通过 path 设置是一个非常高效的选择。(更多关于 path 的内容,详见:如何正确书写 path https://xrender.fun/form-render/demos/index3)
表单的其他设计

在工单系统,系统管理人员会配置大量的字段,由于历史原因,保存字段的时候并非标准 schema 数据,所以当通过字段创建表单时,需要进行一次格式转换,如下图。左图为转换之前格式,右图为转换后的 schema 格式。


在右图中我们注意到,字段元素【字段 2】外层又包裹了一层 schema 格式数据,并且用字母 a 表示元素数据,这是为了美化排版,节省页面空间,产品设计中增加了双列展示的效果,系统通过字母组合来表示具体的某一行。如下图:

在组件自定义方面,增加上传功能、拖拽功能、异步请求的级联组件、联动组件等,可以满足业务多种场景需求。
总结
数据驱动的好处,在于前后端可以通过清晰的数据格式明确页面的呈现和交互效果;另外,在修改数据时,可以只修改接口返回,而前端无需上线。
数据驱动在客服工单系统中的应用还有很多,比如表格视图、流程渲染等,这些应用都能大幅提高开发效率和维护性。
在追求低代码的大潮流下,客服工单系统虽然非常复杂,但我们吸取低代码的设计思想去简化系统的复杂度。
想了解更多转转公司的业务实践,点击关注下方的公众号吧!
这篇关于数据驱动在转转客服工单系统中的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






