本文主要是介绍web scraper_Web Scraper和服指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
web scraper
Being a frequent reader of Hacker News, I noticed an item on the front page earlier this year which read, “Kimono – Never write a web scraper again.” Although it got a great number of upvotes, the tech junta was quick to note issues, especially if you are a developer who knows how to write scrapers. The biggest concern was a non-intuitive UX, followed by the inability of the first beta version to extract data items from websites as smoothly as the demo video suggested.
作为Hacker News的常客,我注意到今年早些时候头版上的一句话是 “ 和服–不再写网络刮板 ”。 尽管得到了很多支持,但是技术联盟很快就注意到了问题,特别是如果您是知道如何编写刮板的开发人员。 最大的问题是用户界面不直观,其次是Beta版本无法像演示视频所建议的那样顺利地从网站提取数据项。
I decided to give it a few months before I tested it out, and I finally got the chance to do so recently.
我决定在测试之前几个月给它,最后我终于有机会这样做。
Kimono is a Y-Combinator backed startup trying to do something in a field where others have failed. Kimono is focused on creating APIs for websites which don’t have one, another term would be web scraping. Imagine you have a website which shows some data you would like to dynamically process in your website or application. If the website doesn’t have an API, you can create one using Kimono by extracting the data items from the website.
和服是Y-Combinator支持的创业公司,试图在其他人失败的领域做点事情。 和服致力于为没有网站的网站创建API,另一个术语是网站抓取。 假设您有一个网站,其中显示了一些您想在网站或应用程序中动态处理的数据。 如果网站没有API,则可以使用和服通过从网站提取数据项来创建API。
合法吗? (Is it Legal?)
Kimono provides an FAQ section, which says that web scraping from public websites “is 100% legal” as long as you check the robots.txt file to see which URL patterns they have disallowed. However, I would advise you to proceed with caution because some websites can pose a problem.
和服提供了一个“常见问题解答”部分,其中说,只要您检查robots.txt文件以查看禁止使用哪些URL模式,从公共网站上进行网络抓取是“ 100%合法的”。 但是,我建议您谨慎行事,因为某些网站可能会引起问题。
A robots.txt is a file that gives directions to crawlers (usually of search engines) visiting the website. If a webmaster wants a page to be available on search engines like Google, he would not disallow robots in the robots.txt file. If they’d prefer no one scrapes their content, they’d specifically mention it in their Terms of Service. You should always look at the terms before creating an API through Kimono.
robots.txt是一个文件,可为爬网程序(通常是搜索引擎)提供访问网站的指导。 如果网站站长希望某个网页在Google等搜索引擎上可用,则他不会在robots.txt文件中禁止使用机器人。 如果他们不希望任何人抓取其内容,则可以在其服务条款中特别提及。 通过和服创建API之前,应始终仔细阅读术语。
An example of this is Medium. Their robots.txt file doesn’t mention anything about their public posts, but the following quote from their TOS page shows you shouldn’t scrape them (since it involves extracting data from their HTML/CSS).
这方面的一个例子是中。 他们的robots.txt文件未提及他们的公开帖子,但他们的TOS页面中的以下引号表明您不应抓取它们(因为它涉及从其HTML / CSS中提取数据)。
For the remainder of the site, you may not duplicate, copy, or reuse any portion of the HTML/CSS, JavaScipt, logos, or visual design elements without express written permission from Medium unless otherwise permitted by law.
在本网站的其余部分,未经法律明确许可,不得复制,复制或重复使用HTML / CSS,JavaScipt,徽标或视觉设计元素的任何部分。
If you check the #BuiltWithKimono section of their website, you’d notice a few straightforward applications. For instance, there is a price comparison API, which is built by extracting the prices from product pages on different websites.
如果查看他们网站的#BuiltWithKimono部分 ,您会注意到一些简单的应用程序。 例如,有一个价格比较API ,它是通过从不同网站上的产品页面提取价格而构建的。
Let us move on and see how we can use this service.
让我们继续前进,看看如何使用此服务。
我们要做什么? (What are we about to do?)
Let’s try to accomplish a task, while exploring Kimono. The Blog Bowl is a blog directory where you can share and discover blogs. The posts that have been shared by users are available on the feeds page. Let us try to get a list of blog posts from the page.
让我们尝试探索和服的同时完成一项任务。 博客碗是一个博客目录,您可以在其中共享和发现博客。 供稿页面上提供了用户共享的帖子。 让我们尝试从该页面获取博客文章列表。
The simple thought process when scraping the data is parsing the HTML (or searching through it, in simpler terms) and extracting the information we require. In this case, let’s try to get the title of the post, its link, and the blogger’s name and profile page.
抓取数据时,一个简单的思考过程就是解析HTML(或更简单地搜索它)并提取我们需要的信息。 在这种情况下,让我们尝试获取帖子的标题,其链接以及博客的名称和个人资料页面。
入门 (Getting Started)
The first step is, of course, to register. Once you’ve signed up, choose either of two options to run Kimono: through a Chrome extension or a bookmarklet.
当然,第一步是注册。 注册后,可以选择两个选项来运行和服:通过Chrome扩展程序或小书签。
报废的舞台物品 (Stage items to be scraped)
We’ll start by using the bookmarklet, where we start with our base URL (http://theblogbowl.in/feeds/). The next step is to select items we would like to store. In our case, we just store the titles of posts and the names of bloggers. The respective links (or any other HTML attributes) associated with these texts are automatically picked up by Kimono. Once you have selected the data you want, you can check the advanced view or the sample data output by changing the views.
我们将从使用小书签开始,从我们的基本URL( http://theblogbowl.in/feeds/ )开始。 下一步是选择我们要存储的项目。 在我们的案例中,我们只存储帖子的标题和博客作者的姓名。 与这些文本关联的相应链接(或任何其他HTML属性)由和服自动提取。 选择所需的数据后,您可以通过更改视图来检查高级视图或示例数据输出。
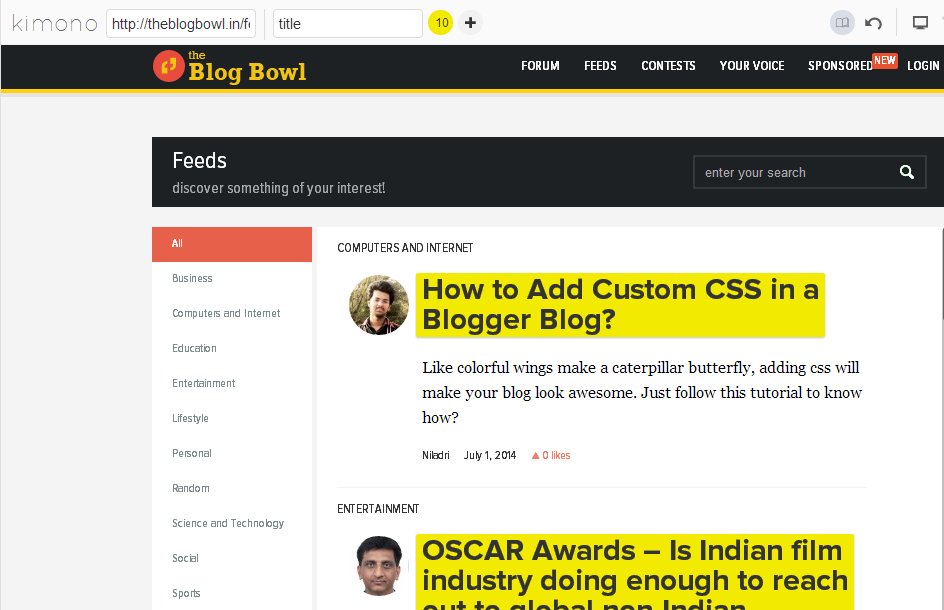
This is where you’ll start to notice some hiccups in the process. It’s not very intuitive at making selections, but you should be able to figure out the correct process eventually. Once you click on an item, all other similar items on the page are highlighted, and you need to point out whether the selections were correct, by selecting one of the pair of small icons (a tick and a cross) that appear next to the selections. If you need to add more items to your list, click the on the “+” icon at the top and repeat the process.
在这里,您将开始注意到此过程中的一些问题。 进行选择不是很直观,但是您最终应该能够找出正确的过程。 单击某个项目后,页面上所有其他类似的项目都会突出显示,您需要通过选择出现在旁边的一对小图标(对勾和叉号)之一来指出选择是否正确。选择。 如果需要在列表中添加更多项目,请单击顶部的“ +”图标,然后重复该过程。
Kimono gives you the ability to create collections, and group similar data items into one. Although it doesn’t make a difference from the point of view of the scraper, it helps in simplifying the data conceptually, which might help others understand what you did.
和服使您能够创建集合,并将相似的数据项分组为一个。 尽管从刮板的角度来看并没有什么区别,但它有助于从概念上简化数据,这可能有助于其他人了解您的工作。
分页 (Pagination)
For any web scraper, managing pagination is a very important issue. As a developer, you’ll either check the URL pattern of the pages (http://theblogbowl.in/feeds/?p=[page_no] in our case) and iterate through the pages, or you save the pagination links and open them one by one. Naturally, the former way is better. Kimono allows pagination and you need to click the icon on the top right to activate the feature.
对于任何刮板来说,管理分页都是非常重要的问题。 作为开发人员,您将检查页面的URL模式(在我们的情况下为http://theblogbowl.in/feeds/?p=[page_no] )并循环浏览页面,或者保存分页链接并打开他们一个接一个。 当然,前一种方法更好。 和服允许分页,您需要单击右上角的图标以激活该功能。
Click on the button or link that takes you to the next page. In this page, the “>” link does this work, so we select the item after activating the pagination feature.
单击按钮或链接,将您带到下一页。 在此页面中,“>”链接可完成此工作,因此我们在激活分页功能后选择该项目。
Click the tick icon as shown in the screenshot below once you are done selecting the next page link.
选择完下一页链接后,请单击下面的屏幕快照中所示的勾号图标。
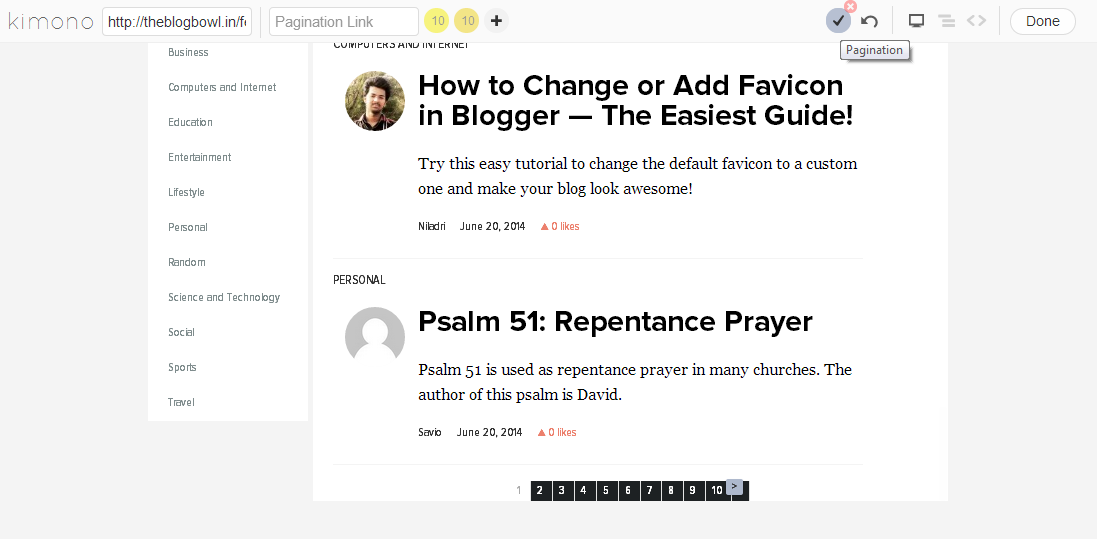
When you are all done, click the “Done” button to proceed.
完成后,单击“完成”按钮继续。
Although it looked like Kimono understood what to look for, I’ll explain a loophole in their pagination feature later in the post.
尽管看上去和服理解了要寻找的内容,但在后面的文章中,我将解释其分页功能中的漏洞。
运行刮板 (Running the scraper)
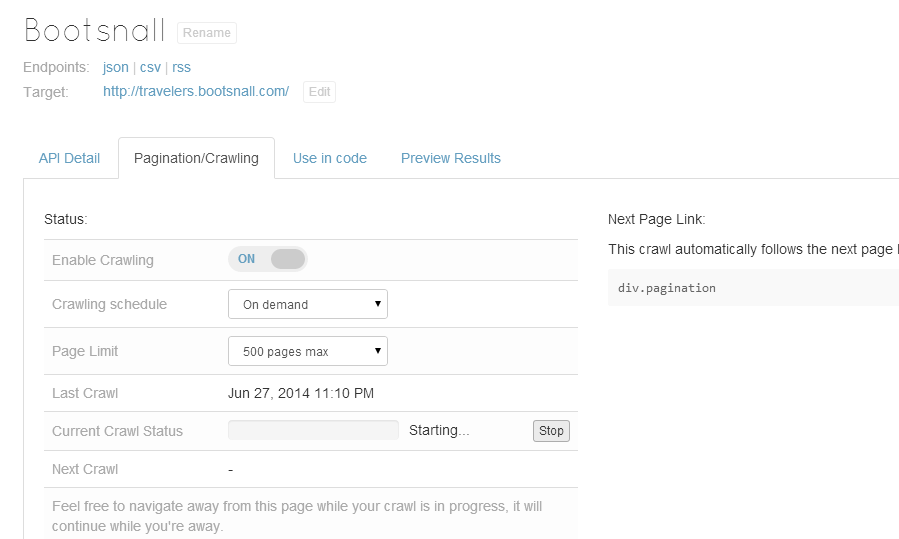
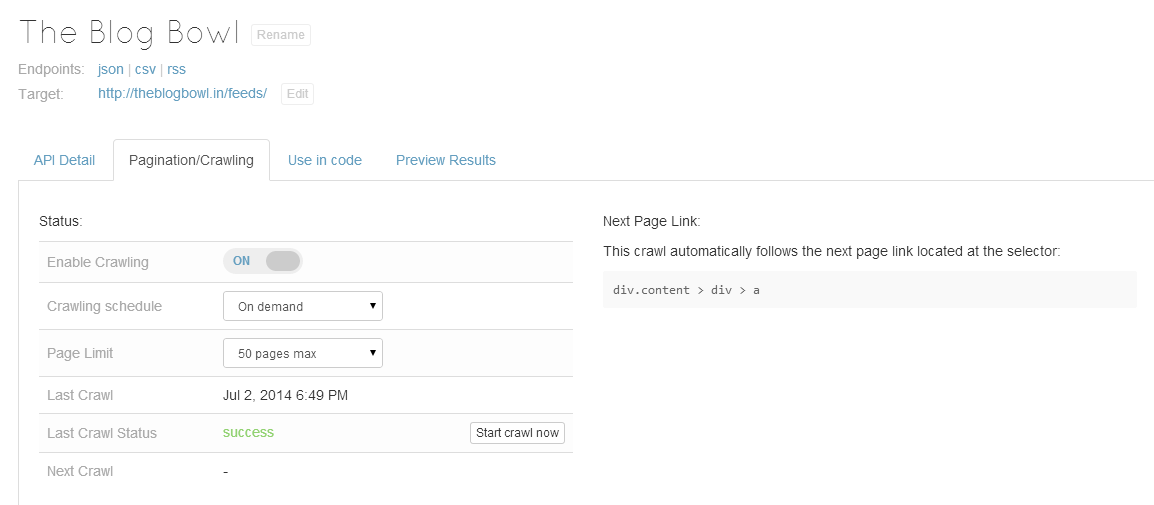
Once we save the scraper, we can either set it to run at regular intervals, or run it on demand. In our case, we chose the latter. Although there were 92 pages, I set the limit to 500 to see how it goes.
保存刮板后,我们可以将其设置为定期运行,也可以按需运行。 在我们的案例中,我们选择了后者。 尽管有92页,但我将限制设置为500,以查看其效果。
结果 (Results)
Once the scraping task is complete, let us look at the results.
抓取任务完成后,让我们看一下结果。
Although I put a limit of 50 pages, I stopped it at approximately 18 pages to see the results. Here they are.
尽管我限制了50页,但我在大约18页的页面上停了下来以查看结果。 他们在这里 。
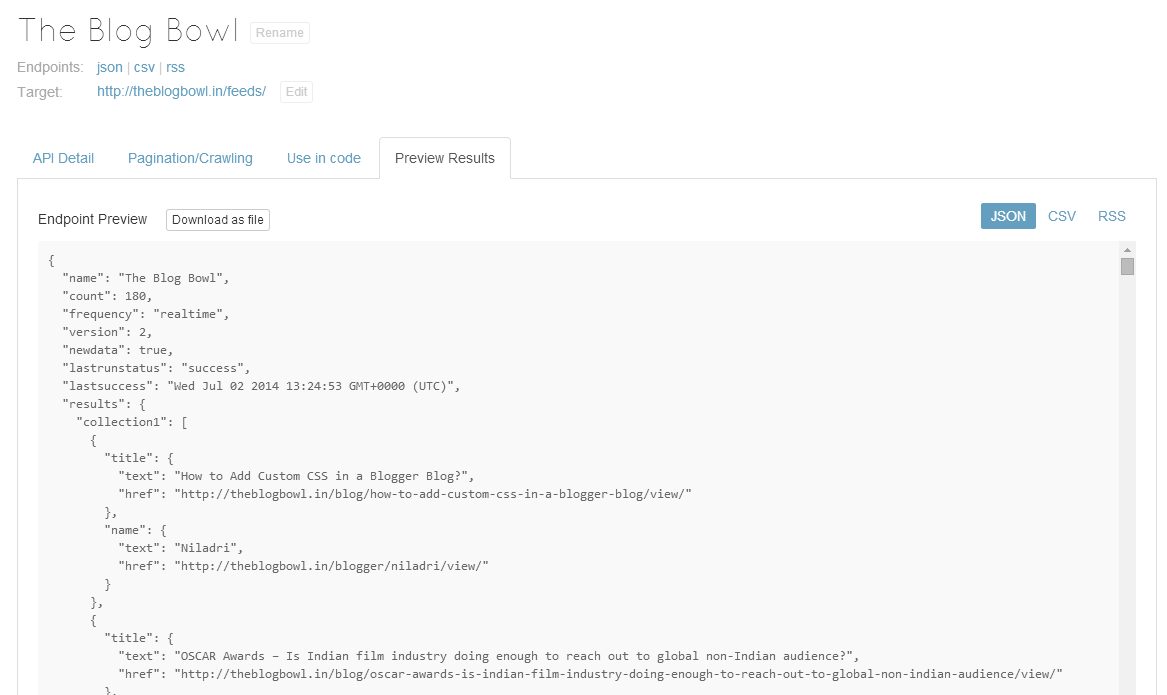
We were successfully able to extract the data that we required. But is it a perfect service?
我们能够成功提取所需的数据。 但这是一项完美的服务吗?
什么时候会出错? (When can it go wrong?)
In our task, we conveniently selected the next button for the pagination. The official documentation mentions that we must feed the Next link to the API for Kimono to understand the pagination.
在我们的任务中,我们方便地选择了下一个用于分页的按钮。 官方文档中提到,我们必须将“ Next链接提供给和服API,以了解分页。
This means that Kimono’s pagination works only in presence of a “next” button. This means that websites which do not have a “next” button can’t be scraped by Kimono.
这意味着和服的分页仅在存在“下一个”按钮的情况下有效。 这意味着和服无法删除没有“下一步”按钮的网站。
For instance, this website contains a lot of information and the list of pages is displayed below. However, a “Next” or “Previous” button is absent.
例如, 此网站包含很多信息,页面列表显示在下面。 但是,没有“下一个”或“上一个”按钮。
和服的未来是什么? (What’s the future for Kimono?)
Kimono is great to build APIs for single page applications. If you require it to scrape multiple pages, with different structures, Kimono might not be able to accomplish it.
和服非常适合为单页应用程序构建API。 如果需要它刮擦具有不同结构的多页,和服可能无法完成。
If you need to scrape complex web pages with a lot of logic in between, Kimono is not advanced enough to accomplish your needs. Kimono is constantly evolving (after all, it’s backed by YC!) and there might be a day when “you don’t have to write a web scraper again.”
如果您需要在中间有很多逻辑的情况下抓取复杂的网页,和服的功能还不足以满足您的需求。 和服不断发展(毕竟,它得到了YC的支持!),可能有一天“您不必再次编写网络抓取工具”。
Until then, you just have to depend on your regex skills and an HTML parser if you want to undertake these complex tasks!
在此之前,如果您要执行这些复杂的任务,则只需要依靠正则表达式技能和HTML解析器即可!
Have you had any experience with Kimono? What do you think of the service?
您有和服方面的经验吗? 您如何看待这项服务?
翻译自: https://www.sitepoint.com/web-scrapers-guide-kimono/
web scraper
这篇关于web scraper_Web Scraper和服指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





