本文主要是介绍大数据实战(下)-搭建hadoop2 HA,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大纲
- NameNode高可用整体架构
- NameNode的主备切换
- NameNode的共享存储
NameNode高可用整体架构
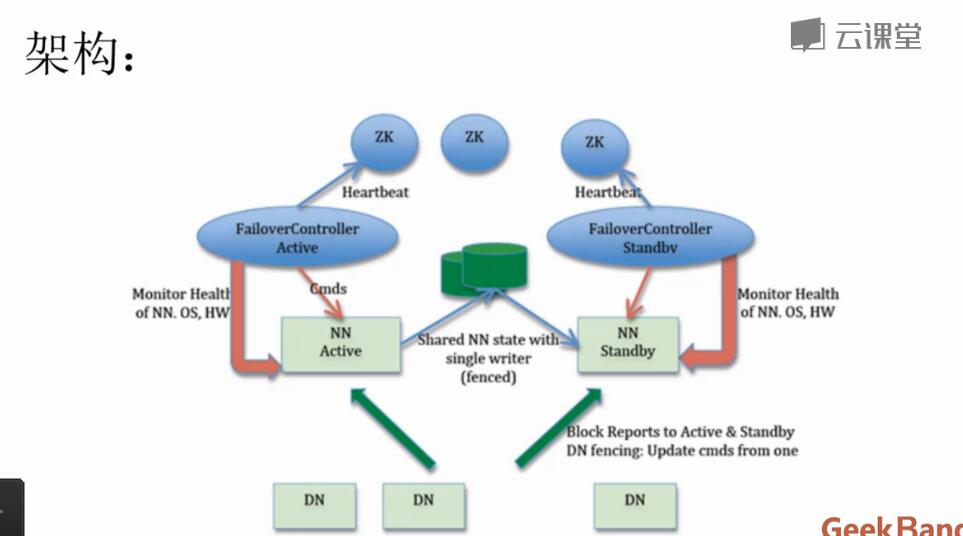
hadoop1.x 两大核心hdfs、mapRedure,这两个都存在一个单点问题。
hadoop2.0的HA 机制有两个namenode,一个是active namenode,状态是active;另外一个是standby namenode,状态是standby。两者的状态是可以切换的,但不能同时两个都是active状态,最多只有1个是active状态。只有active namenode提供对外的服务,standby namenode是不对外服务的。active namenode和standby namenode之间通过NFS或者JN(journalnode,QJM方式)来同步数据。
active namenode会把最近的操作记录写到本地的一个edits文件中(edits file),并传输到NFS或者JN中。standby namenode定期的检查,从NFS或者JN把最近的edit文件读过来,然后把edits文件和fsimage文件合并成一个新的fsimage,合并完成之后会通知active namenode获取这个新fsimage。active namenode获得这个新的fsimage文件之后,替换原来旧的fsimage文件。
这样,保持了active namenode和standby namenode的数据的实时同步,standby namenode可以随时切换成active namenode(譬如active namenode挂了)。而且还有一个原来hadoop1.0的secondarynamenode,checkpointnode,buckcupnode的功能:合并edits文件和fsimage文件,使fsimage文件一直保持更新。所以启动了hadoop2.0的HA机制之后,secondarynamenode,checkpointnode,buckcupnode这些都不需要了。
组件:
- Active NameNode
- Standby NameNode
- ZKFailoverController
- Zookeeper集群
- 共享存储系统
- DataNode
NameNode主备切换
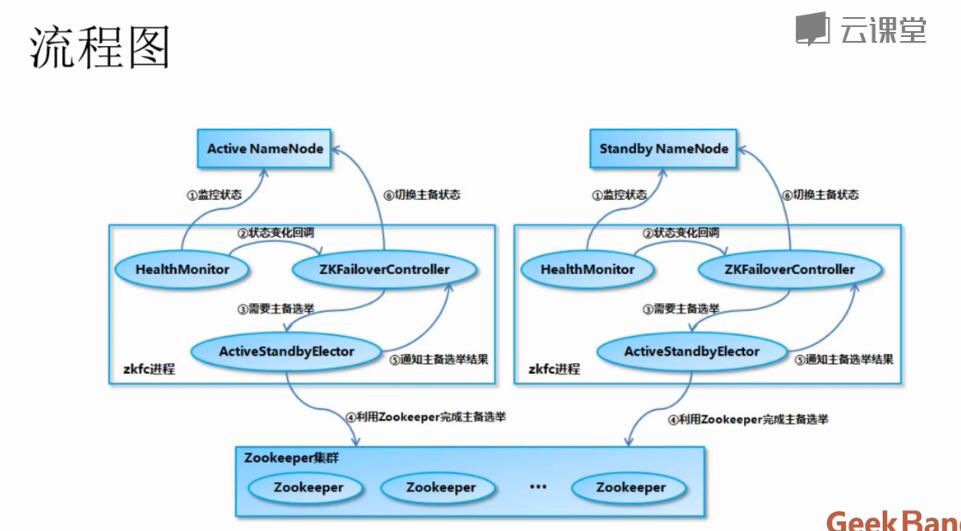
NameNode的共享储存
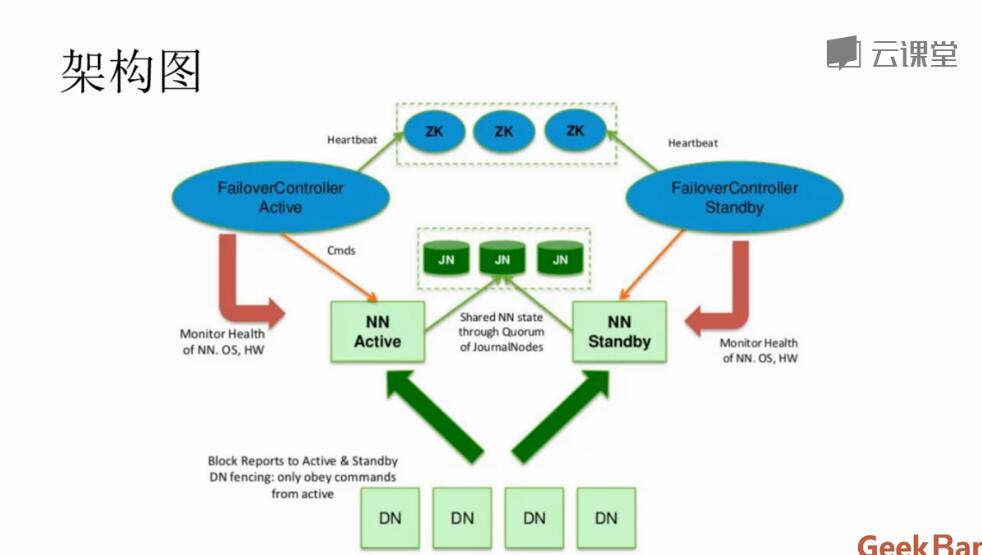
NameNode 初始化启动,进入 Standby 状态
在 NameNode 以 HA 模式启动的时候,NameNode 会认为自己处于 Standby 模式,在 NameNode 的构造函数中会加载 FSImage 文件和 EditLog Segment 文件来恢复自己的内存文件系统镜像。在加载 EditLog Segment 的时候,调用 FSEditLog 类的 initSharedJournalsForRead 方法来创建只包含了在 JournalNode 集群上的共享目录的 JournalSet,也就是说,这个时候只会从 JournalNode 集群之中加载 EditLog,而不会加载本地磁盘上的 EditLog。另外值得注意的是,加载的 EditLog Segment 只是处于 finalized 状态的 EditLog Segment,而处于 in-progress 状态的 Segment 需要后续在切换为 Active 状态的时候,进行一次数据恢复过程,将 in-progress 状态的 Segment 转换为 finalized 状态的 Segment 之后再进行读取。
加载完 FSImage 文件和共享目录上的 EditLog Segment 文件之后,NameNode 会启动 EditLogTailer 线程和 StandbyCheckpointer 线程,正式进入 Standby 模式。如前所述,EditLogTailer 线程的作用是定时从 JournalNode 集群上同步 EditLog。而 StandbyCheckpointer 线程的作用其实是为了替代 Hadoop 1.x 版本之中的 Secondary NameNode 的功能,StandbyCheckpointer 线程会在 Standby NameNode 节点上定期进行 Checkpoint,将 Checkpoint 之后的 FSImage 文件上传到 Active NameNode 节点。
NameNode 从 Standby 状态切换为 Active 状态
当 NameNode 从 Standby 状态切换为 Active 状态的时候,首先需要做的就是停止它在 Standby 状态的时候启动的线程和相关的服务,包括上面提到的 EditLogTailer 线程和 StandbyCheckpointer 线程,然后关闭用于读取 JournalNode 集群的共享目录上的 EditLog 的 JournalSet,接下来会调用 FSEditLog 的 initJournalSetForWrite 方法重新打开 JournalSet。不同的是,这个 JournalSet 内部同时包含了本地磁盘目录和 JournalNode 集群上的共享目录。这些工作完成之后,就开始执行“基于 QJM 的共享存储系统的数据恢复机制分析”一节所描述的流程,调用 FSEditLog 类的 recoverUnclosedStreams 方法让 JournalNode 集群中各个节点上的 EditLog 达成一致。然后调用 EditLogTailer 类的 catchupDuringFailover 方法从 JournalNode 集群上补齐落后的 EditLog。最后打开一个新的 EditLog Segment 用于新写入数据,同时启动 Active NameNode 所需要的线程和服务。
NameNode 从 Active 状态切换为 Standby 状态
当 NameNode 从 Active 状态切换为 Standby 状态的时候,首先需要做的就是停止它在 Active 状态的时候启动的线程和服务,然后关闭用于读取本地磁盘目录和 JournalNode 集群上的共享目录的 EditLog 的 JournalSet。接下来会调用 FSEditLog 的 initSharedJournalsForRead 方法重新打开用于读取 JournalNode 集群上的共享目录的 JournalSet。这些工作完成之后,就会启动 EditLogTailer 线程和 StandbyCheckpointer 线程,EditLogTailer 线程会定时从 JournalNode 集群上同步 Edit Log。
内容来自网易微专业课堂
来自搜索内容
这篇关于大数据实战(下)-搭建hadoop2 HA的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






