本文主要是介绍VGGnet详细介绍与TensorFlow实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1. VGG介绍
- 2. VGG网络结构及测试结果分析
- 3. 使用Tensorflow 实现其网络结构
1. VGG介绍
VGG是由牛津大学计算机视觉组(Visual Geometry Group)提出的,也是VGG名称的由来。相关信息发表在论文《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITIO》,作者是Karen Simonyan和 Andrew Zisserman。该网络在2014的ImageNet-ILSVRC比赛中获得分类任务第二名和定位任务第一名。
为了测试增加深度对识别能力的影响, VGG使用了十分规整的网络结构,并进行了大量的试验,主要特点为:
-
使用小的卷积核
均采用 3 ∗ 3 3*3 3∗3的卷积核(极小量的 1 ∗ 1 1*1 1∗1卷积核),步长 s t r i d e s = 1 strides=1 strides=1。
我们在关于感受野的计算 一文中,介绍了如何计算感受野,有以下公式成立
r 0 = 1 , r 1 = k 1 , r n = ( k n − 1 ) ∏ i = 1 n − 1 s i + r n − 1 r_0 = 1,r_1 = k_1, r_n = (k_n-1)\prod\limits_ {i = 1}^{n-1}s_i + r_{n-1} r0=1,r1=k1,rn=(kn−1)i=1∏n−1si+rn−1
我们很容易根据公式推导出经过两层 3 ∗ 3 3*3 3∗3卷积后的感受野
r 2 = ( 3 − 1 ) s 1 s 2 + r 1 = 2 ∗ 1 ∗ 1 + 3 = 5 r_2 = (3-1)s_1s_2+r_1 = 2*1*1+3 = 5 r2=(3−1)s1s2+r1=2∗1∗1+3=5
如果我们对原图使用 1 1 1层 5 ∗ 5 5*5 5∗5的卷积核,得到特征图的感受野也为 5 5 5,因此我们可以使用两层 3 ∗ 3 3*3 3∗3的卷积代替一层 5 ∗ 5 5*5 5∗5的卷积。同理我们可以使用 3 3 3层 3 ∗ 3 3*3 3∗3的卷积代替一层 7 ∗ 7 7*7 7∗7的卷积。使用多层小卷积核替代浅层大卷积核带来的好处是:
-
增加非线性,提高决策函数的表达能力
3 3 3层 3 ∗ 3 3*3 3∗3的卷积核比 1 1 1层 7 ∗ 7 7*7 7∗7卷积核使用更多的激活函数(Relu),增加了非线性。
-
减少参数
我们假设卷积的输入和输出的通道数均为 C C C,则使用 1 1 1层 7 ∗ 7 7*7 7∗7卷积核的参数量为 7 ∗ 7 ∗ C ∗ C = 49 C 2 7*7*C*C = 49C^2 7∗7∗C∗C=49C2 个,使用 3 3 3层 3 ∗ 3 3*3 3∗3卷积核的参数量为 3 ∗ 3 ∗ 3 ∗ C ∗ C = 27 C 2 3*3*3*C*C=27C^2 3∗3∗3∗C∗C=27C2,仅为 7 ∗ 7 7*7 7∗7卷积核参数的 55 % 55\% 55%
-
-
使用小的池化
池化大小 2 ∗ 2 2*2 2∗2,步长 s t r i d e s = 2 strides=2 strides=2
-
使用小的卷积核减少了参数和计算量,加上池化层的使用,使得网络可以更深,特征图的通道数也更大。VGG的特征图通道数(卷积核的个数)设计也很简单,即通道数从 64 64 64开始,每经过一次池化,特征图通道数量变成之前的 2 2 2倍,直到通道数增加至 512 512 512,作者认为该通道数足够大,不需要在增大了。
2. VGG网络结构及测试结果分析
下图为6组VGG结构图,从A-E,网络层数(只计算权重层)逐渐增加(图中的加黑字体表示比前一个网络增加或不同的地方),其中较为出名的为VGG-16(图中D)和VGG-19(图中E)。
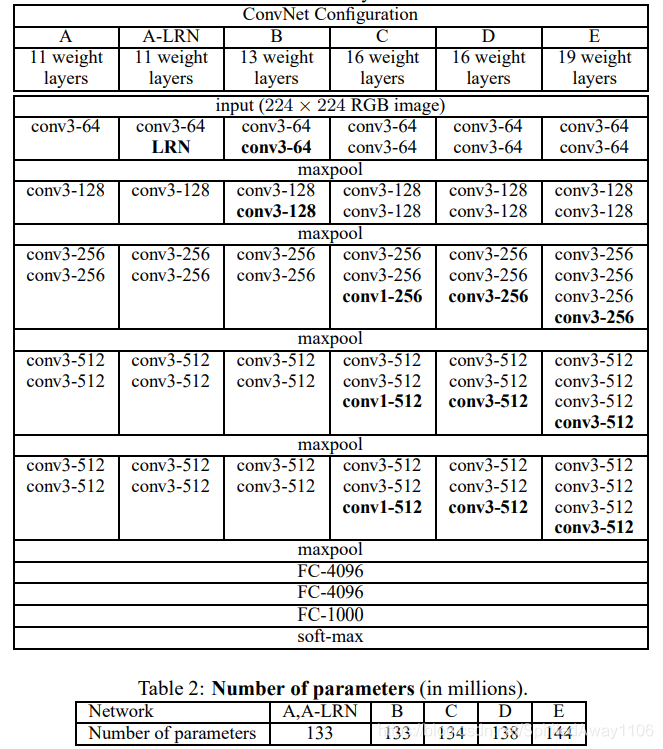
从图也能看出其网络结构很规整,输入图像大小为 224 ∗ 224 ∗ 3 224*224*3 224∗224∗3,经过几次卷积层(图中卷积层的定义为 conv<kernel size>-<number of channels>)然后接最大池化层,这几组网络的使用相同结构的三个全连接层:两个具有4096个神经元的全连接层和一个具有1000个神经元的输出层。
各个网络的测试结果如下图

根据网络结果和结果分析,我们可以有以下结论:
-
A vs A-LRN表明,使用LRN无法提高准确率,增加LRN层反而增加了错误率,且带来更多的内存和计算时间的消耗,因此的后续的网络结构中,均不采用LRN
-
B vs C 表明,增加 1 ∗ 1 1*1 1∗1的卷积,可以提高准确率,作者认为是加入 1 ∗ 1 1*1 1∗1的卷积会提高非线性,增加模型的决策能力。此外,针对网络B,作者还测试了使用一个 5 ∗ 5 5*5 5∗5的卷积核替换两个 3 ∗ 3 3*3 3∗3的卷积核,试验结果表明,使用小卷积核的准确度提高了 7 % 7\% 7%,由此作者认为使用小卷积核训练更深的网络比使用大卷积核训练较浅的网络更加有效。
-
C vs D,将 1 ∗ 1 1*1 1∗1的卷积替换为 3 ∗ 3 3*3 3∗3的卷积,可以提高准确率,作者认为使用 3 ∗ 3 3*3 3∗3的卷积将会比 1 ∗ 1 1*1 1∗1的卷积能获取更多的空间特性
-
D vs E,当网络结构增加至19层时,准确率的提高似乎到达了极限,需要使用更多的训练数据来提高准确率。训练时使用随机缩放(随机范围是[256-512])可以看做是数据增强(Data Augmentaion)的一种实现方式,试验表明能获得更好的效果。
-
从A - E,随着网络层数的增加,准确率在逐步提升,认为加深网络模型,有助于提高分类精度。
3. 使用Tensorflow 实现其网络结构
#!/usr/bin/python3# @Time : 2021/04/01 10:07
# @Author :
# @File : vggnet
# @Software: PyCharm
# @Description : 使用TensorFlow实现VGGNet网络结构import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Conv2D,MaxPool2D,Dropout,Activation,Flatten,Dense
from tensorflow.keras import Model
import os# 设置VGG配置,分别对应论文的'A','B','D','E'模型
vgg_cfgs = {'vgg11':[64,'MaxPooling',128,'MaxPooling',256,256,'MaxPooling',512,512,'MaxPooling',512,512,'MaxPooling'],'vgg13':[64,64,'MaxPooling',128,128,'MaxPooling',256,256,'MaxPooling',512,512,'MaxPooling',512,512,'MaxPooling'],'vgg16':[64,64,'MaxPooling',128,128,'MaxPooling',256,256,256,'MaxPooling',512,512,512,'MaxPooling',512,512,512,'MaxPooling'],'vgg19':[64,64,'MaxPooling',128,128,'MaxPooling',256,256,256,256,'MaxPooling',512,512,512,512,'MaxPooling',512,512,512,512,'MaxPooling']}def vggnet(model_name='vgg16',im_height=224,im_width=224,class_num=1000):if model_name in vgg_cfgs.keys():inputs = tf.keras.Input(shape=(im_height,im_width,3),name='Input-0')x = inputsconv_k,maxppool_k = 1,1for k,cfg in enumerate(vgg_cfgs[model_name]):if cfg=='MaxPooling':x = MaxPool2D(pool_size=2,strides=2,name='MaxPooling-'+str(maxppool_k))(x)maxppool_k += 1else: x = Conv2D(filters=cfg,kernel_size=3,padding='same',activation='relu',name='Conv3-'+str(cfg)+'-'+str(conv_k))(x)conv_k += 1x = Flatten(name='Flatten')(x)x = Dense(units=4096,activation='relu',name='Dense-1')(x)x = Dropout(rate=0.5,name='Dropout-1')(x)x = Dense(units=4096,activation='relu',name='Dense-2')(x)x = Dropout(rate=0.5,name='Dropout-2')(x)outputs = Dense(units=class_num,activation='softmax',name='Output-1')(x)return Model(inputs=inputs,outputs=outputs,name=model_name.upper())else:print('模型名不存在,请检测')return Nonemodel = vggnet(model_name='vgg16')
model.summary()模型摘要如下
Model: "VGG16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
Input-0 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
Conv3-64-1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
Conv3-64-2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
MaxPooling-1 (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
Conv3-128-3 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
Conv3-128-4 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
MaxPooling-2 (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
Conv3-256-5 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
Conv3-256-6 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
Conv3-256-7 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
MaxPooling-3 (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
Conv3-512-8 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
Conv3-512-9 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
Conv3-512-10 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
MaxPooling-4 (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
Conv3-512-11 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
Conv3-512-12 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
Conv3-512-13 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
MaxPooling-5 (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
Flatten (Flatten) (None, 25088) 0
_________________________________________________________________
Dense-1 (Dense) (None, 4096) 102764544
_________________________________________________________________
Dropout-1 (Dropout) (None, 4096) 0
_________________________________________________________________
Dense-2 (Dense) (None, 4096) 16781312
_________________________________________________________________
Dropout-2 (Dropout) (None, 4096) 0
_________________________________________________________________
Output-1 (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
这篇关于VGGnet详细介绍与TensorFlow实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





