本文主要是介绍【大数据】YARN调度器及调度策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
YARN调度器
YARN负责作业资源调度,在集群中找到满足业务的资源,帮助作业启动任务,管理作业的生命周期。
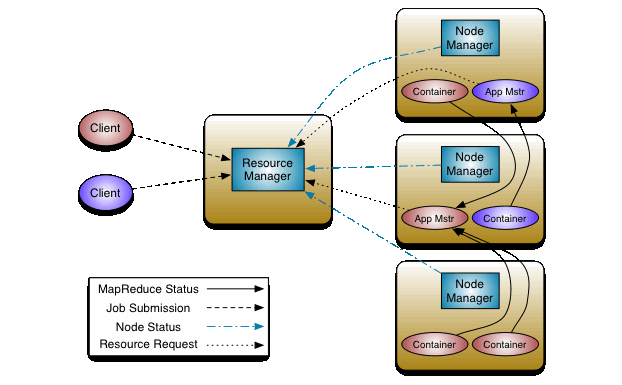
YARN技术架构
目前,Hadoop作业调度器主要有三种:先进先出调度器(First In First Out)、容量调度器(Capacity Scheduler)、公平调度器(Fair Scheduler)。
Apache Hadoop-1.x 默认调度器为先进先出调度器(First In First Out);
Apache-Hadoop-2.7.2 之后默认调度器是容量调度器(Capacity Scheduler);
Apache-Hadoop-3.2.2 默认调度器是公平调度器(Fair Scheduler)。
1.先进先出调度器
FIFO调度器(First In First Out): 单队列,根据提交作业的先后顺序,先到先得。

1.1 先进先出调度器的特点
-
无需任何配置,作业按照先来后到分配资源,但会出现小任务被大任务阻塞的情况。
2.容量调度器
Yahoo开发的多用户调度器,容量调度器每个队列内部先进先出,同一时间队列中只有一个任务在执行,队列的并行度为队列的个数。
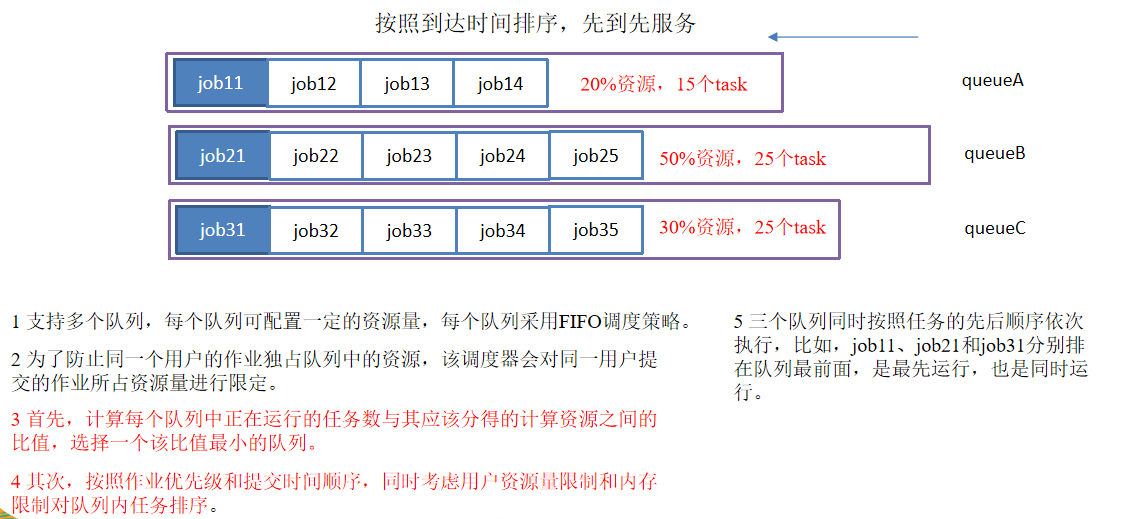
2.1 容量调度器特点
-
多队列:每隔队列可以配置一定的资源量,每个队列内部采用先进先出的调度策略。
-
容量保证:管理员可为每个队列设置资源最低保证和资源使用上限。
-
资源灵活:如果一个队列中的资源有剩余,可以暂时共享给哪些需要资源的队列,而一旦该队列有新的作业提交,则其他队列借调的资源会归还给该队列。
-
多租户:支持多用户共享集群和多作业同时运行;为了防止一个用户的作业独占队列中的资源,可以对用户提交作业所使用的资源进行限定。
2.2 容量调度器配置模板
容量调度器的配置文件是 capacity-scheduler.xml。
| 参数名称 | 说明 |
|---|---|
| capacity | 队列容量百分比 (%),每个级别的所有队列的容量总和必须等于 100,该值也可以配置为绝对资源,如 [memory=10240,vcores=12],这表示 10GB 内存和 12 个 VCore。 |
| maximum-capacity | 队列容量最大百分比(%),需要确保每个队列的绝对最大容量大于等于绝对容量。此外,将此值设置为 -1 会将最大容量设置为 100%,也可以设置为绝对资源。 |
| maximum-allocation-mb | 每个队列在资源管理器上分配给每个容器请求的最大内存限制。此设置覆盖集群配置 yarn.scheduler.maximum-allocation-mb。该值必须小于等于集群最大值。 |
| maximum-allocation-vcores | 每个队列在资源管理器中分配给每个容器请求的虚拟内核的最大限制。此设置会覆盖集群配置 yarn.scheduler.maximum-allocation-vcores。该值必须小于或等于集群最大值。 |
| user-settings.[user-name].weight | 此浮点值用于计算队列中的用户限制资源值。该值将使每个用户的权重大于或小于队列中的其他用户。例如,如果用户 A 在队列中接收的资源比用户 B 和 C 多 50%,则用户 A 的此属性将设置为 1.5。用户 B 和 C 将默认为 1.0。 |
| minimum-user-limit-percent | 如果有资源需求,每个队列都会在任何时刻强制限制分配给用户的资源百分比。用户限制可以在最小值和最大值之间变化,但不会小于此设置值。例如,假设该属性的值为 25,如果两个用户向一个队列提交了应用程序,则没有一个用户可以使用超过 50% 的队列资源。如果第三个用户提交程序,则没有一个用户可以使用超过 33% 的队列资源。对于 4 个或更多用户,任何用户都不能使用超过 25% 的队列资源。值为 100 表示不施加用户限制,默认值为 100,值指定为整数。 |
<property><name>yarn.scheduler.capacity.root.queues</name> // 队列列表,新增加的队列需要在这个配置项中添加<value>a,b,c</value><description>当前等级的队列,root表示根队列</description>
</property>
<property><name>yarn.scheduler.capacity.root.a.queues</name> // 子队列配置<value>a1,a2</value><description>当前等级的队列,root表示根队列</description>
</property>
<!--子队列样例 test-->
<property><name>yarn.scheduler.capacity.root.test.capacity</name><value>3</value>
<description>test队列在默认标签下标准队列容量,各个队列该属性相加必须等于100</description>
</property>
<property><name>yarn.scheduler.capacity.root.test.maximum-capacity</name><value>4.5</value><description>test队列在默认标签下最大队列容量,当其他队列空闲时,可以占用空闲的资源。通常该值给上边标准容量值的1.5倍,该属性相加不用等于100</description>
</property>
<property><name>yarn.scheduler.capacity.root.test.maximum-applications</name><value>1000</value><description>test队列最大任务提交数,通常普通租户给200左右即可</description>
</property>
<property><name>yarn.scheduler.capacity.root.test.acl_submit_applications</name><value>tdpzj</value><description>test队列的提交权限用户</description>
</property>
<property><name>yarn.scheduler.capacity.root.test.acl_administer_queue</name><value>tdpzj</value><description>test队列的管理权限用户</description>
</property>
<property><name>yarn.scheduler.capacity.root.test.state</name><value>RUNNING</value><description>test队列的状态,包括RUNNING和STOPPED状态</description>
</property>3.公平调度器
Facebook开发的多用户调度器,
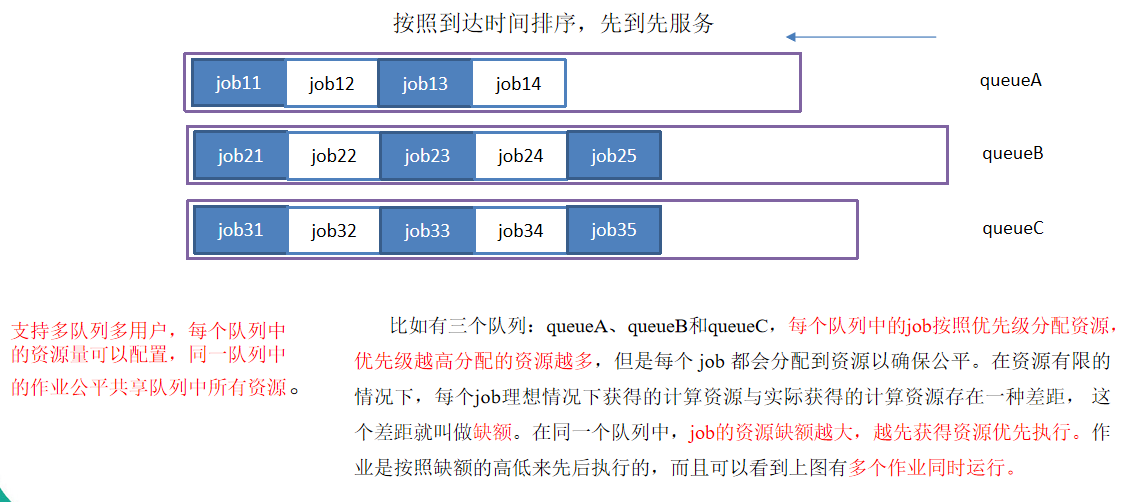
3.1 公平调度器的特点
-
多队列:每隔队列可配置一定的资源,每个队列内部采用先进先出的调度策略。
-
容量保证:管理员可为每个队列设置资源最低保证和资源使用上限。
-
资源灵活:如果一个队列中的资源有剩余,可以暂时共享给哪些需要资源的队列,而一旦该队列有新的作业提交,则其他队列借调的资源会归还给该队列。
-
多租户:支持多用户共享集群和多作业同时运行;为了防止一个用户的作业独占队列中的资源,可以对用户提交作业所使用的资源进行限定。
3.2 公平调度器配置模板
公平调度器配置文件是 fair-scheduler.xml。
| 参数名称 | 说明 |
|---|---|
| minResources | 最少资源保证量,设置格式为“X mb, Y vcores”,当一个队列的最少资源保证量未满足时,它将优先于其他同级队列获得资源,对于不同的调度策略(后面会详细介绍),最少资源保证量的含义不同,对于fair策略,则只考虑内存资源,即如果一个队列使用的内存资源超过了它的最少资源量,则认为它已得到了满足;对于drf策略,则考虑主资源使用的资源量,即如果一个队列的主资源量超过它的最少资源量,则认为它已得到了满足。 |
| maxResources | 最多可以使用的资源量,fair scheduler会保证每个队列使用的资源量不会超过该队列的最多可使用资源量。 |
| maxRunningApps | 最多同时运行的应用程序数目。通过限制该数目,可防止超量Map Task同时运行时产生的中间输出结果撑爆磁盘。 |
| minSharePreemptionTimeout | 最小共享量抢占时间。如果一个资源池在该时间内使用的资源量一直低于最小资源量,则开始抢占资源。 |
| schedulingMode/schedulingPolicy | 队列采用的调度模式,可以是fifo、fair或者drf。 |
| aclSubmitApps | 可向队列中提交应用程序的Linux用户或用户组列表,默认情况下为“*”,表示任何用户均可以向该队列提交应用程序。需要注意的是,该属性具有继承性,即子队列的列表会继承父队列的列表。配置该属性时,用户之间或用户组之间用“,”分割,用户和用户组之间用空格分割,比如“user1, user2 group1,group2”。 |
| aclAdministerApps | 该队列的管理员列表。一个队列的管理员可管理该队列中的资源和应用程序,比如可杀死任意应用程序。 |
配置示例:
<?xml version="1.0"?>
<allocations><queue name="sample_queue"> //队列名<minResources>10000 mb,0vcores</minResources> //最小资源<maxResources>90000 mb,0vcores</maxResources> //最大资源<maxRunningApps>50</maxRunningApps> //可以同时运行的作业数<weight>2.0</weight> //权值<schedulingPolicy>fair</schedulingPolicy> //队列内部调度策略,可选的有:fair、fifo、drf 或者 继承该类的子类(org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.SchedulingPolicy)<queue name="sample_sub_queue"> //队列的子目录<minResources>5000 mb,0vcores</minResources></queue></queue><user name="sample_user"> //对于特定用户的配置<maxRunningApps>30</maxRunningApps></user><userMaxAppsDefault>5</userMaxAppsDefault> //默认的用户最多可以同时运行的任务
</allocations>4.公平调度器与容量调度器的区别
4.1 核心调度策略不同
-
容量调度器优先选择资源利用率低的队列;
-
公平调度器优先选择对资源缺额比例大的队列。
4.2 每个队列可设置的调度策略不同
-
容量调度器:FIFO、DRF(内存+CPU);
-
公平调度器:FIFO、FAIR、DRF。
5.调度策略
5.1. FIFO策略
公平调度器每个队列资源分配策略如果选择FIFO的话,此时公平调度器相当于上面讲过的容量调度器。
5.2 Fair策略
Fair 策略(默认)是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到1/2的资源;如果三个应用程序同时运行,则每个应用程序可得到1/3的资源。
具体资源分配流程和容量调度器一致:选择队列、选择作业、选择容器,以上三步,每一步都是按照公平策略进行资源的分配。
5.3 DRF策略
DRF(Dominant Resource Fairness),在进行作业资源分配的分配时同时考虑内存和CPU。
例如集群中一共用100CPU和10TB的内存,作业A需要(2CPU,300GB),作业B需要(6CPU,100GB),在集群中两个作业分别需要(2%CPU,3%内存)、(6%CPU,1%内存)的资源,这表示作业A是内存主导的,作业B是CPU主导的,针对这种场景,可以考虑引入DRF策略对不同的作业进行内存和CPU的限制。
这篇关于【大数据】YARN调度器及调度策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




