本文主要是介绍中文数据让LLM变笨?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

我这里先贴一下论文的原链接:
https://arxiv.org/abs/2401.10286
然后贴一下我翻译+标注的下载链接:https://gitee.com/chatpaper/arXiv_top_chinese/blob/master/0801_top/%E4%B8%AD%E6%96%87%E4%BC%9A%E8%AE%A9LLM%E5%8F%98%E7%AC%A8%EF%BC%9F.pdf
先说一下我看这篇文章的动机:
-
中文是不是真的太烂了,导致处理中文任务也比不过英文基座模型?
-
有没有是分词不兼容,模型结构、大小等原因导致的?
OK,我们先看它的摘要部分翻译:
尽管在语言模型应用中,任务与训练语料库之间的一致性是一个基本共识,但我们的一系 列实验和我们设计的度量标准揭示,基于代码的大型语言模型(LLMs)在非编码中文任务 中显著优于在与任务紧密匹配的数据上训练的模型。此外,在对中文幻觉高度敏感的任务 中,实验结果表明,具有较少中文语言特性的模型,取得了更好的性能。我们的实验结果可 以在中文数据处理任务中很容易地被复制,例如为检索增强生成(Retrieval-Augmented Generation, RAG)准备数据,只需简单地用基于代码的模型替换基础模型。此外,我们的研究 为讨论哲学上的“中文房间”思想实验提供了一个独特的视角。
上面的结论,直接跳到实验结果中,即4.2.2 Less Chinese Knowledge, Less Hallucination
原文翻译:
表3展示了DeepSeek代码6.7b和Code Llama 7b的评估结果,它们都是在代码数据上训练的,并且具有几乎相 同数量的参数。DeepSeek代码6.7b得分低于Code Llama 7b在EXPERTS上的主要原因是,DeepSeek代码6.7b的 回答有时包含一些源材料中没有的信息【也就是幻觉比较重】。CCR指标也证实了Code Llama 7b具有较少 的幻觉。在我们的知识生成任务中,原始内容的逐字复制是必要的,因此具有较少中文知识的基于代码 的LLM表现更好【这个其实比较难评了,DeepSeek Code 6.7b和Code Llama 7b,这两个模型的训练细节都 完全不一样,没法直接归因到中文数据吧?】。实验结果表明,过多的中文知识可能会干扰任务的完成。这 一结果使我们深思:更大的模型可能拥有更多知识,然而在这个任务中,我们并不需要一个更有知识的模 型,而是需要一个更忠实的模型,减少幻觉。
贴一下表3:
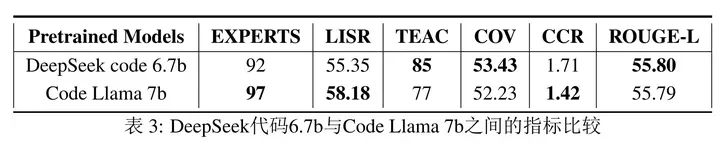
这里的结果,就让我比较迷惑了,如果是同样的网络结构,一个简中版,一个英文版,这样的对比,我是认可的,但两个架构的模型,大小,数据,配比,训练方式都不完全一样,性能的差异,直接归因到中文数据上,我是不太认同的。
但OpenAI的苹果哥也表示同样的观点,所以还是值得大家进一步做探究的,期待更加严格的对比实验。
233,和论文作者沟通了一下,发现我确实忽略了论文最大的一个贡献点:代码模型比普通llm在数据生成任务中效果要好很多,甚至于比论文中没提到的3.5和4.0效果都好,这个发现,对社区的帮助还是很大的。
作者希望大家多关注代码模型在非代码场景下的应用;关注我们提出的抹掉模型中文能力后,用同样中文数据用同样超参和轮数SFT后,在中文评测集上评测模型真实能力的避免训练数据污染的评测方法。
来源 知乎:强化学徒
这篇关于中文数据让LLM变笨?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




