本文主要是介绍自动弹性,QPS线性提升|一文读懂云原生数仓AnalyticDB弹性技术原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
在全球经济增长放缓的大背景之下,企业在加强数字化建设的过程中,实现效益最大化成为一个绕不开的话题。阿里云瑶池旗下的云原生数仓AnalyticDB MySQL湖仓版(以下简称AnalyticDB MySQL)在发布之初提供了定时弹性功能,帮助业务有规律的客户定时升降配计算资源以节省成本。时隔一年,AnalyticDB MySQL针对用户痛点,再推出Multi-Cluster弹性资源模式,它具备贴合用户负载、自动配置、性能线性提升等优点,进一步帮用户节省成本,提高计算效率。
弹性模型介绍
弹性模型分为两种,分别是Min-Max弹性模型和Multi-Cluster弹性模型。
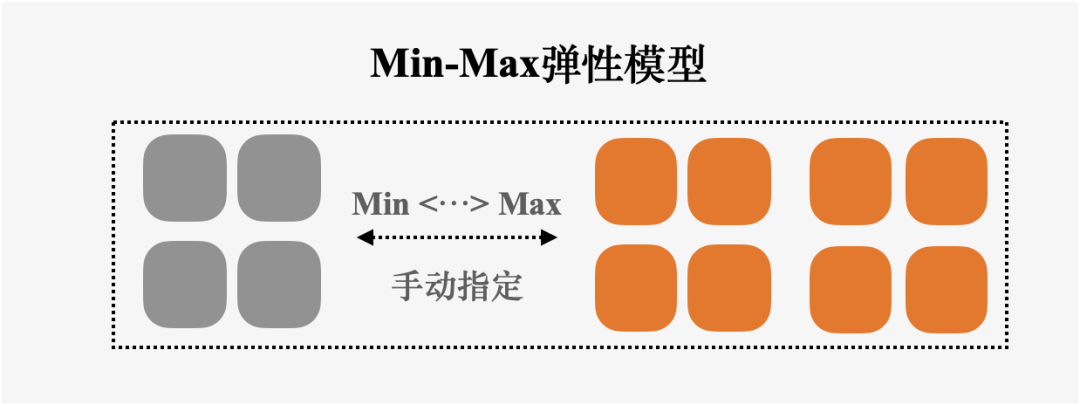
▶︎ Min-Max弹性模型:
单个SQL可使用的资源量在Min和Max资源量之间进行扩缩,该模型适用于ETL场景,用于提升单个SQL的性能。例如,Min=16 cores,Max=32cores,单个SQL可使用的资源量在区间[16cores, 32cores]中。
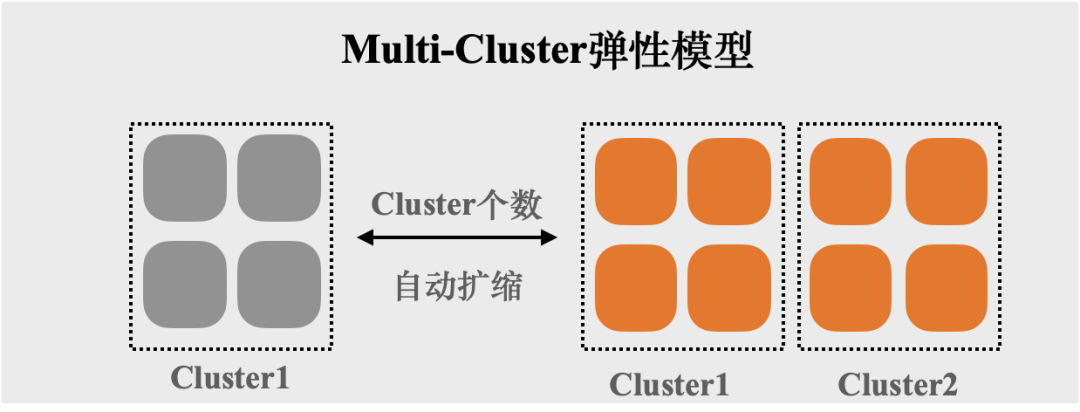
▶︎ Multi-Cluster弹性模型:
以Cluster粒度进行资源扩缩,单个SQL可使用的资源量为单个Cluster,Cluster之间资源隔离,该模型适用于在线分析和交互式分析场景,用于提升SQL的并发度。
例如,单个Cluster大小=16cores,最小Cluster和最大Cluster个数分别为1和2,那么,每个SQL可使用的资源量为16cores(单个Cluster),随着SQL并发度的提高或降低,Cluster个数可以在1和2之间自动进行调整,Cluster1中运行的SQL不会影响Cluster2中的SQL。
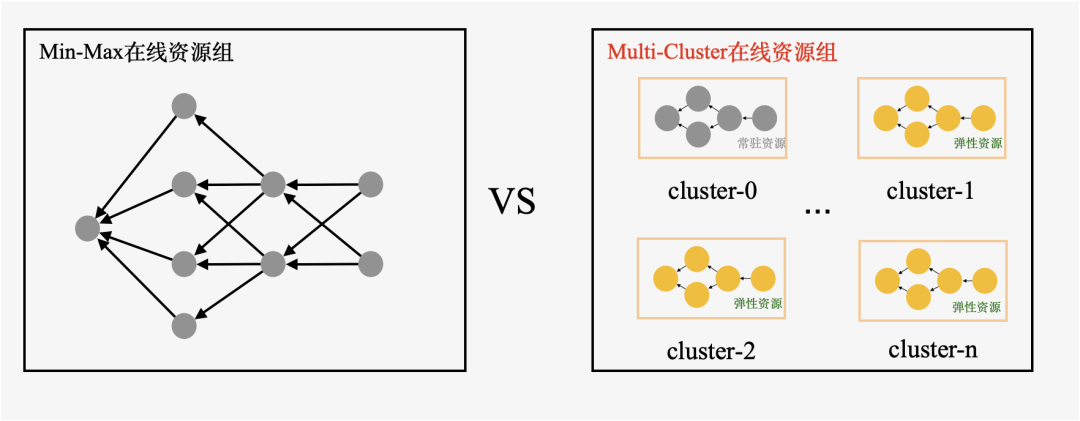
Multi-Cluster弹性模式优势
AnalyticDB MySQL在没有Multi-Cluster弹性模型之前,采用的是Min-Max弹性模型,通过定时弹性实现资源的弹起和释放,存在不少限制,具体表现在以下方面:
- 易用性:用户只能根据业务规律,在固定时间段将资源弹升,弹性计划生效间隔长(最短间隔10分钟);
- 性能:小查询的性能容易受到大查询的干扰, 查询并发数不随资源组大小变化,查询可能排队;
- 成本:用户需要指定固定时间段的弹升规格,难以贴合实时的业务负载,短时间段的业务波谷无法缩容。
为了解决上述问题,应对查询的高并发实时分析场景,AnalyticDB MySQL引入了Multi-Cluster弹性模型。Multi-Cluster弹性模型作用在AnalyticDB MySQL在线资源组内部,一个在线资源组由一个或者多个Cluster组成,相比Min-Max弹性模型,在易用性、性能和成本上均有了较大提升。
易用性
自动根据当前实例的负载进行Cluster个数的扩缩,无需手动设置资源扩缩时间,更灵活地应对不同的业务流量。用户只需设置好Cluster个数的上限、下限及每个Cluster大小即可。
性能
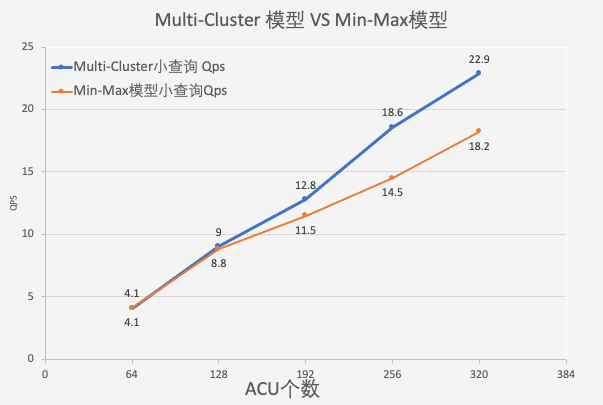
Cluster之间资源隔离,单个SQL只会影响其所在的Cluster,不影响其余Cluster中SQL的运行,避免了单个大SQL对其它小SQL的干扰,进而影响资源组内查询的整体性能。根据实验结果,随着Cluster个数的增多,查询并发数呈线性增长趋势。与Min-Max弹性模型相比,Multi-Cluster弹性模型下在同等计算资源下,查询并发度可提升高达28%。
成本
贴合用户负载,动态选择最优Cluster个数,应对业务的波峰波谷。为了更直观地展示Multi-Cluster弹性模型和Min-Max弹性模型在成本上的收益,我们这里举个实际应用的案例:
- 0-7点:某客户在晚上0-7点的时候,处于业务低峰期,用户采用定时弹性,将计算资源缩小至48ACU;
- 7-24点:客户业务处于间歇性高峰期,用户采用定时弹性将计算资源保持在192ACU,以应对随时可能到来的波峰;
- 全天使用的总资源量为3600ACU。
注:ACU(AnalyticDB Compute Unit)是AnalyticDB MySQL湖仓版资源分配的最小单位。一个ACU约等于1核4GB。
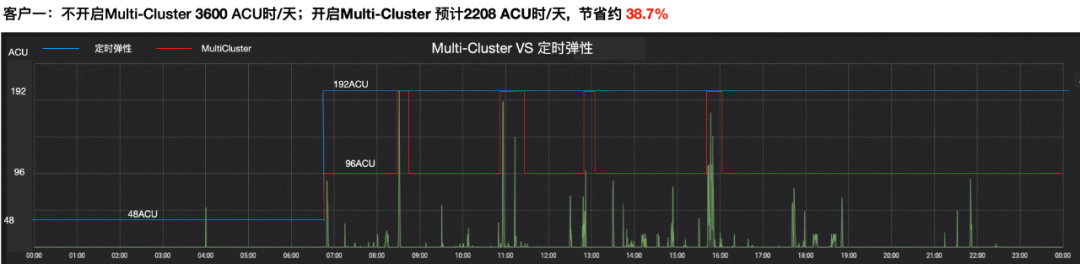
应用Multi-Cluster弹性模型之后:
- 0-7点:用户将Cluster大小缩小为48ACU,保持和定时弹性的资源使用量一直;
- 7-24点:用户将Cluster大小变为96ACU,并设置最小Cluster个数为1,最大Cluster为2;
- 全天使用的总资源量为2208ACU,相比定时弹性节省资源约38.7%。
可以看到相对定时弹性,Multi-Cluster弹性模型可以在业务两个高峰之间的波谷,为用户减少Cluster个数,节省成本,当用户的业务波峰到来后,Cluster个数随之弹升,满足业务负载。
总的来说,相比Min-Max弹性模型,Multi-Cluster弹性模型更适合高并发实时分析场景,体现在易用性、性能和成本等维度。下面我们将深入地了解Multi-Cluster的技术架构,以及如何实现“弹得准、弹得快、弹得好”的目标。
Multi-Cluster技术架构
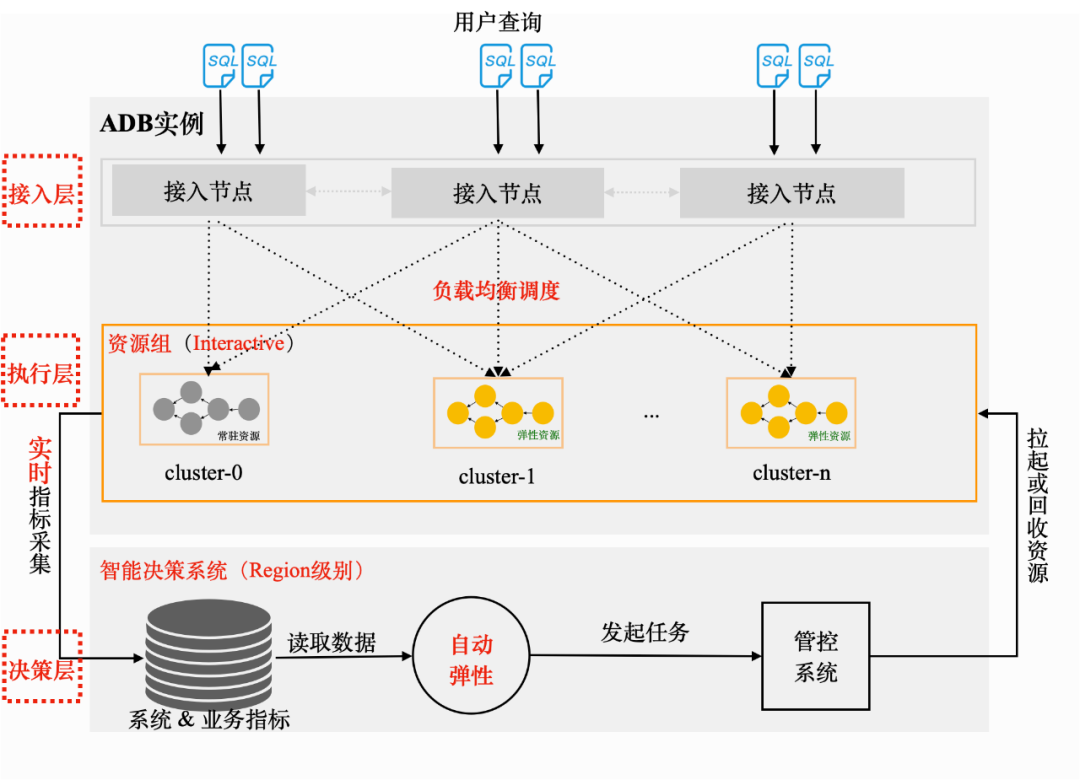
在设计Multi-Cluster技术架构的时候,我们的核心目标有三个:弹得准、弹得快、弹得好。下图是AnalyticDB MySQL Multi-Cluster的整体架构图,从上至下可分为三层:
- 接入层:负责将用户的查询投递到特定的资源组,再根据Cluster的负载情况分配到具体的Cluster上去执行;
- 执行层:资源组内部划分为相同大小的多个Cluster,每个query只在其中一个Cluster上执行;
- 决策层:通过实时读取AnalyticDB MySQL资源的负载情况,进行Multi-Cluster资源组的扩缩容决策。
弹得快:实时数据链路
为了保障扩容的时效性,快速应对用户查询的到来,AnalyticDB MySQL建立了Region级别的指标采集系统。AnalyticDB MySQL实例也进行了改造,能实时地更新内部的业务指标(如Query排队数、CPU使用等),并被指标采集进程采集到中心的存储端。目前整个数据链路的延迟在10s左右。
弹得准:稳定的扩缩容策略
AnalyticDB MySQL实例是由接入层节点、计算节点、存储节点共同构成的复杂系统,在对计算资源进行扩缩容决策的时候面临如下挑战:
- 多组件交互的系统,如何识别外部组件瓶颈;
- 实例指标繁多,基于什么指标来进行扩缩容决策;
- 如何防止指标短时间的抖动,导致扩缩容策略不准;
- 如何判断扩缩容决策是否合理。
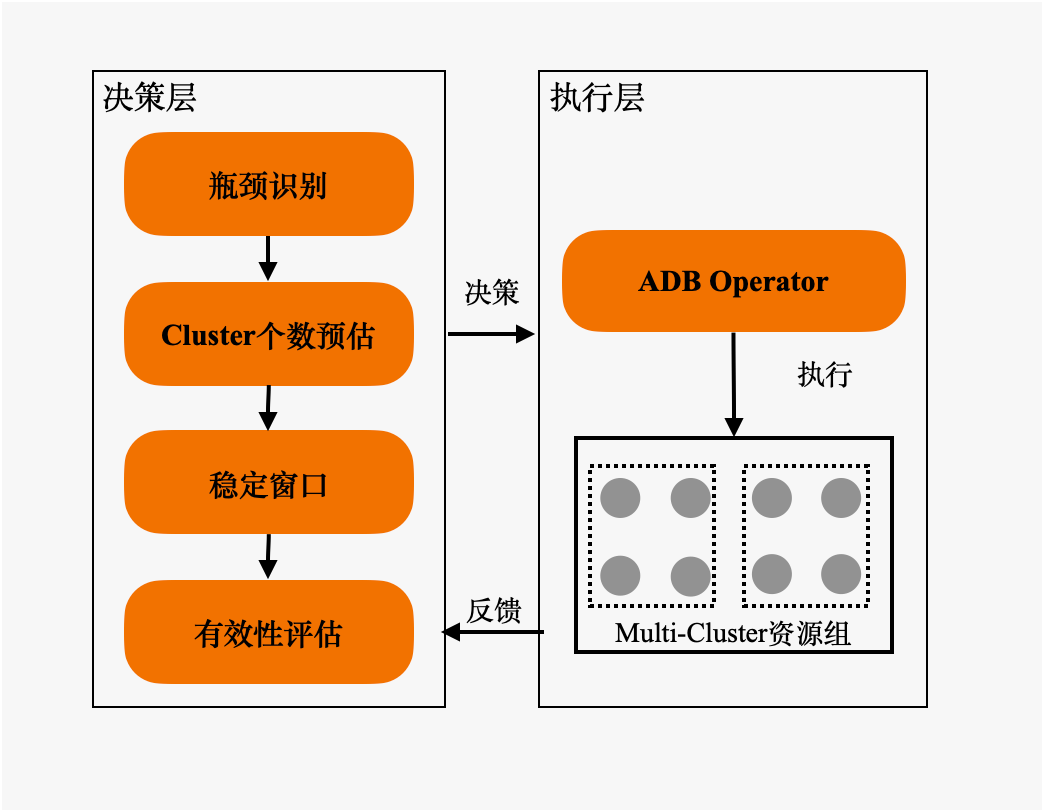
为此,我们将整个Cluster个数计算分为三个阶段:决策、执行、反馈。
决策
▶︎ 瓶颈识别
我们在决策系统中,将指标分为两类:
正向指标:反馈要扩容目标的负载情况,决定扩容目标的扩缩容。
负向指标:反馈除扩容目标外的其余组件的负载情况,用于判断外部瓶颈。
当负向指标达到设定的阈值时,我们认为计算节点扩容对于AnalyticDB MySQL实例整体而言已经无法起到加速查询,提升并发数的作用。对于这种情况,决策系统将会报警直至瓶颈解除。
▶︎ Cluster个数预估
对AnalyticDB MySQL实例的负载分析后,我们发现对于扩缩容的决策并不能由单个指标决定,随着用户负载类型不同,决定扩缩容的指标也不一样。主要用到的指标有:用户CPU使用率,用户内存使用率,用户查询排队数等。
因此在扩缩容的预估的过程中,我们会先根据每个指标计算得出一个候选Cluster数,最后再选择所有指标中最大的Cluster数作为最终候选项。
- 对于和Cluster挂钩的指标(如CPU利用率)我们采用如下计算公式:

- 对于和资源组挂钩、但不和Cluster挂钩的指标(如查询排队数和并发数)我们采用如下公式计算:
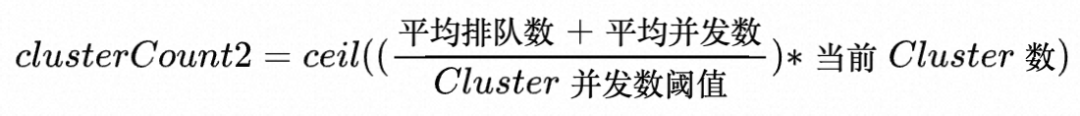
- 最终我们取所有算出来的目标Cluster数的较大值:
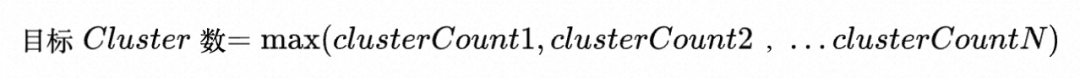
▶︎ 稳定窗口
为避免因为实例负载抖动等因素造成的metric抖动,我们采用了稳定窗口的算法来避免抖动
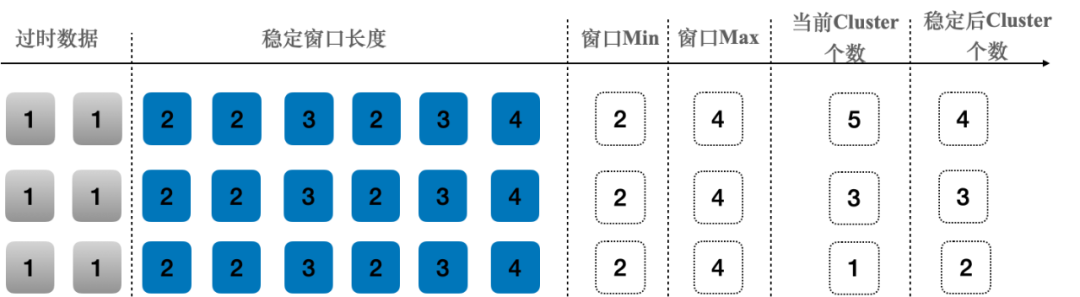
在稳定窗口期间,每次预估的Cluster个数都会记录下来,并使用当前的Cluster个数和稳定窗口中推荐的个数进行对比。
a) 若窗口Min ≤ 当前Cluster个数 ≤ 窗口Max,则当前Cluster个数保持不变;
b) 若当前Cluster个数 < 窗口Min,则说明应当将当前Cluster个数应当扩容至窗口Min;
c) 若当前Cluster个数 > 窗口Max,说明当前Cluster个数应当缩到稳定窗口Max。
执行
资源组内部的Cluster,在AnalyticDB MySQL内部对应的K8s的自定义资源(Custom Resource),由自研的Operator进行管理,这些自定义资源实现了K8s的Scale SubResource。当决策系统作出决策后,会通过K8s的Scale API,将目标Cluster个数下发给自定义Operator进行扩缩容。
反馈:有效性评估
在执行完扩(缩)容后,决策系统会记录扩容之前的metric指标的值,并在扩(缩)容完成后持续观察用户负载的指标。
- 扩容评估: 决策系统持续观察扩容后用户查询的qps是否按照Cluster的比例增长了,或者用户查询的rt是否按照Cluster的比例降低了,如果没有明显增长,则认为扩容无效,决策将Cluster个数恢复成扩容前的个数,停止扩容决策运行,并预警。
- 缩容评估:决策系统持续观察缩容后用户查询的qps和rt是否均有明显变化,如果变化超过了一定的阈值,则将Cluster恢复成缩容前的个数,决策系统将Cluster个数恢复成缩容前的个数,停止缩容决策,并预警。
弹得好:负载均衡路由策略
在Cluster个数提升之后,用户无需指定查询路由到的Cluster,AnalyticDB MySQL自动根据负载均衡算法将查询路由到负载最小的Cluster中。
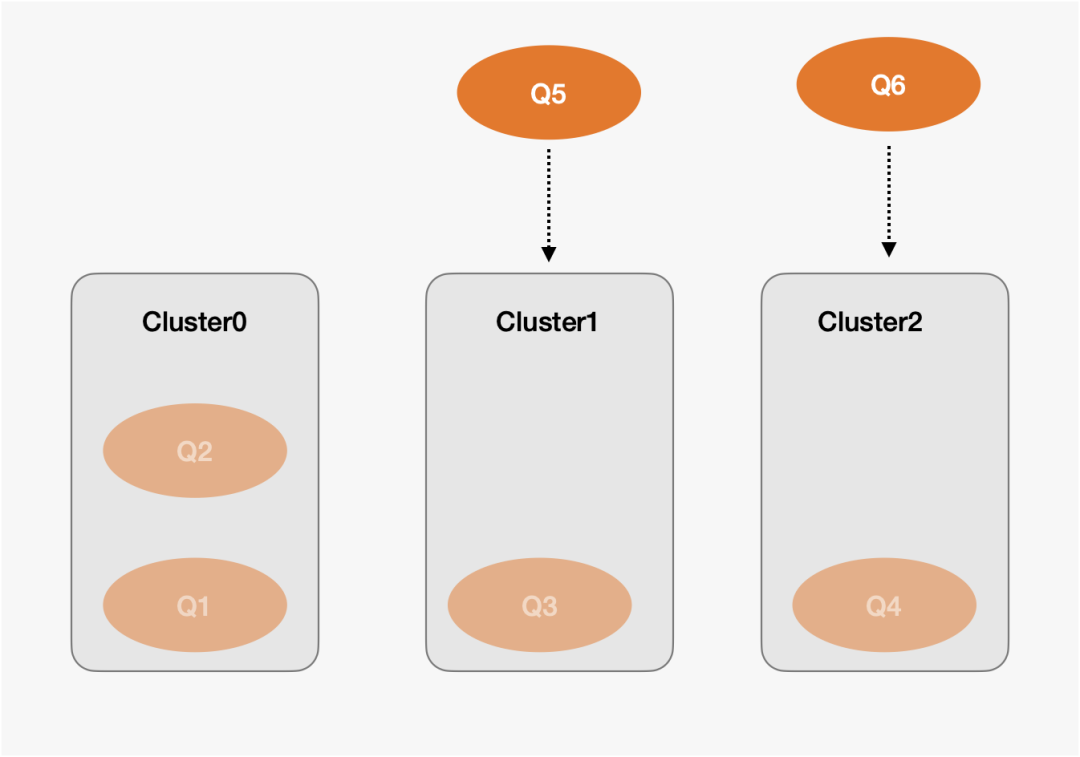
下图是一个根据Cluster负载均衡路由的示意图。
1. 当Q5到来时,由于Cluster0的负载是2,Cluster1的负载是1,Cluster2的负载是1。Q5会优先分配给Cluster1执行。
2. 当Q6到来时,由于Cluster0的负载是2,Cluster1的负载是2,Q6会分配给Cluster2执行。
总结及未来规划
为了更好地贴合业务负载,充分利用资源,实现效益最大化,我们推出了AnalyticDB MySQL Multi-Cluster弹性模型,完成了自动化、智能化扩缩容。AnalyticDB MySQL Multi-Cluster形态有如下特点:
1. 成本:贴合业务负载自动扩缩容,相比单Cluster资源组固定资源,可以节省更多的成本;
2. 查询性能:线性增加,查询的隔离性相比Min-Max模型资源组要更优越;
3. 自动弹性:避免了用户手动调整资源组大小。
未来,我们还将在以下几个方面继续打磨和增强:
- 主动弹性:基于预测的主动弹性,查询延迟最小化;
- 负载解耦:基于WorkLoadManager,大query自动投递到离线资源组减少对在线资源组的资源抢占;
- 弹性效率:资源Pod热池加速弹性效率;
- 效果展示:性能优化及成本节省可视化。
这篇关于自动弹性,QPS线性提升|一文读懂云原生数仓AnalyticDB弹性技术原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






