本文主要是介绍【openGauss/MogDB使用mog_xlogdump解析 xlog文件内容】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
openGauss/MogDB的mog_xlogdump工具类似于PostgreSQL的pg_xlogdump/pg_waldump,可以解析xlog日志,获取xlog里的相关记录。可以通过MogDB的官网下载对应的版本使用,
https://www.mogdb.io/downloads/mogdb
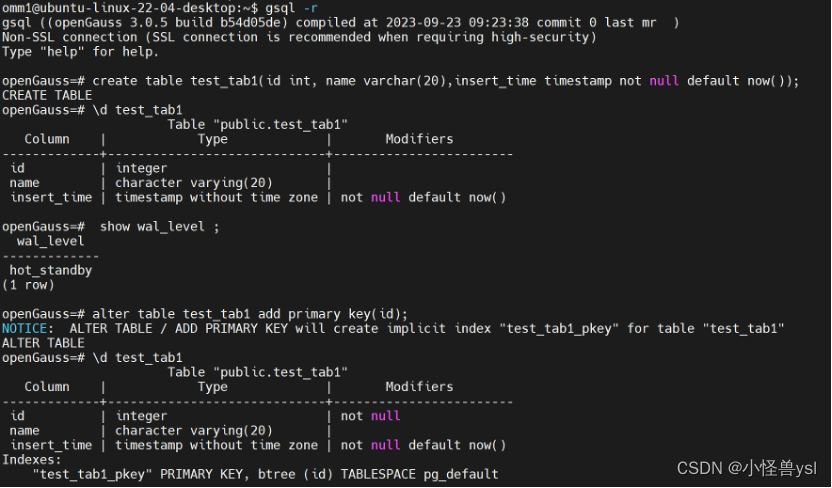
一、 创建表并增加主键(模拟数据)
omm1@ubuntu-linux-22-04-desktop:~$ gsql -r
gsql ((openGauss 3.0.5 build b54d05de) compiled at 2023-09-23 09:23:38 commit 0 last mr )
Non-SSL connection (SSL connection is recommended when requiring high-security)
Type "help" for help.openGauss=# create table test_tab1(id int, name varchar(20),insert_time timestamp not null default now());
CREATE TABLE
openGauss=# \d test_tab1
Table "public.test_tab1"Column | Type | Modifiers
-------------+-----------------------------+------------------------id | integer |name | character varying(20) |insert_time | timestamp without time zone | not null default now()openGauss=# show wal_level ;wal_level
-------------hot_standby
(1 row)openGauss=# alter table test_tab1 add primary key(id);
NOTICE: ALTER TABLE / ADD PRIMARY KEY will create implicit index "test_tab1_pkey" for table "test_tab1"
ALTER TABLE
openGauss=# \d test_tab1
Table "public.test_tab1"Column | Type | Modifiers
-------------+-----------------------------+------------------------id | integer | not nullname | character varying(20) |insert_time | timestamp without time zone | not null default now()
Indexes:"test_tab1_pkey" PRIMARY KEY, btree (id) TABLESPACE pg_default
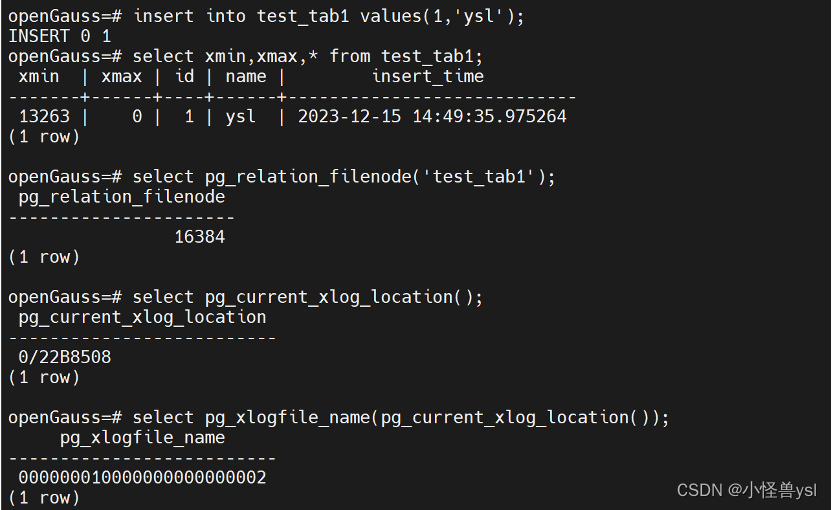
二、插入数据(模拟数据)
openGauss=# insert into test_tab1 values(1,'ysl');
INSERT 0 1//查看数据的xmin,xmax,通过xmin可以看到这条数据属于事务13263openGauss=# select xmin,xmax,* from test_tab1;xmin | xmax | id | name | insert_time
-------+------+----+------+----------------------------13263 | 0 | 1 | ysl | 2023-12-15 14:49:35.975264
(1 row)//查看表的filenodeopenGauss=# select pg_relation_filenode('test_tab1');pg_relation_filenode
----------------------
16384
(1 row)//看到当前使用的wal文件对应的xlog_location
openGauss=# select pg_current_xlog_location();pg_current_xlog_location
-------------------------0/22B8508
(1 row)//可以用如下直接转成使用的xlog文件openGauss=# select pg_xlogfile_name(pg_current_xlog_location());pg_xlogfile_name
--------------------------000000010000000000000002
(1 row)
三、使用mog_xlogdump解析xlog文件
//指定事物id,表应的filenode
mog_xlogdump -x 13263 -o 16384 -R int,varchar,timestamp 000000010000000000000002'insert','tuple':{'int':'1','varchar':'ysl','timestamp':'2023-12-15 14:49:35.975264'}mog_xlogdump: FATAL: error in WAL record at 0/22B8B28: invalid record length at 0/22B8BC8: wanted 32, got 0

//或者不指定事物id,只指定表对应的filenode
mog_xlogdump -o 16384 -R int,varchar,timestamp 000000010000000000000002'insert','tuple':{'int':'1','varchar':'ysl','timestamp':'2023-12-15 14:49:35.975264'}mog_xlogdump: FATAL: error in WAL record at 0/22B8C48: invalid record length at 0/22B8CE8: wanted 32, got 0

四、关于REPLICA IDENTITY和解码数据对比
REPLICA IDENTITY {DEFAULT | USING INDEX index_name | FULL | NOTHING} 调整逻辑复制时写入WAL日志中的信息量,该选项仅在wal_level配置为logical时才有效。
当原数据表发生更新时,默认的逻辑复制流只包含主键的历史记录,如果需要输出所需字段更新或删除的历史记录,可修改本参数。
- DEFAULT(非系统表的默认值): 会记录主键字段的旧值。
- USING INDEX : 会记录名为index_name索引包含的字段的旧值,索引的所有列必须NOT NULL。
- FULL : 记录了所有列的旧值。
- NOTHING(系统表默认值): 不记录旧值的信息。
在REPLICA IDENTITY默认未修改的情况下,update的解码数据对比如下
数据更新:未设置wal_level=logical,未修改replica identity
‘update’,‘new_tuple’:{‘(null)’:‘2’,‘(null)’:‘tt’,‘(null)’:‘2022-04-25 20:05:28.159008’}
数据更新:设置wal_level=logical,未修改replica identity
‘update’,‘new_tuple’:{‘(null)’:‘2’,‘(null)’:‘ttt’,‘(null)’:‘2022-04-25 20:05:28.159008’}
更新非主键列
‘update’,‘new_tuple’:{‘(null)’:‘2’,‘(null)’:‘tttt’,‘(null)’:‘2022-04-25 20:05:28.159008’}
更新主键列
‘update’,‘old_tuple’:{‘(null)’:‘2’,},‘new_tuple’:{‘(null)’:‘3’,‘(null)’:‘ttttt’,‘(null)’:‘2022-04-25 20:05:28.159008’}
这篇关于【openGauss/MogDB使用mog_xlogdump解析 xlog文件内容】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





