本文主要是介绍oracle SCN问题详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一:SCN问题产生的背景
11月15日ORACLE数据库出现故障后,对数据库进行了重新启动,发现alter.log日志告警,详细信息如下:

![]()
说明:首先出现此问题就是我们所说的天花板问题,此处的27并不是说数据库只能用27天了,该值是不断变化的,而且该告警也只有重启数据库后才会出现,因此发现此问题不要扩大声势的向领导反馈说数据库急需打SCN补丁,不然会搞的自己很被动,因为在实际生产库中往往各库之间存在dblink,而此问题可以通过dblink同步传播。
二:Headroom的值如何理解?
查看数据库Headroom历史变化值发现,Headroom由最小的8天变为33天,有时甚至值是45天,既然scn增长是不可逆向的Headroom应该越来越小才对,为什么变大了?
注意:SCN距离当前的最大SCN限制还有大约27天*24小时*60分*60秒*16384。注意这个当前最大SCN限制是变化的。它每一秒钟增大16384。因此,这个告警并不是说27日之后就不可用了。比如,如果您的数据库SCN每秒前进少于16384,那您可能观察到这个27天变成28天,29天...,换句话说,因此scn问题导致数据库宕机等待一段时间重启,数据库有可能恢复,只不过等待时间长短不好确定,但不是网上流传的必须重建数据库,数据库scn和Headroom的值都随着时间在增长,如果查询Headroom的历史值在不断增大,说明数据库在逐渐走向健康状态,
三:如何查询Headroom历史值的变化
1、通过如下脚本检查当前 SCN 距离 Headroom上限的剩余天数
SELECT VERSION,
TO_CHAR(SYSDATE, 'YYYY/MM/DD HH24:MI:SS') DATE_TIME,
((((((TO_NUMBER(TO_CHAR(SYSDATE, 'YYYY')) - 1988) * 12 * 31 * 24 * 60 * 60) +
((TO_NUMBER(TO_CHAR(SYSDATE, 'MM')) - 1) * 31 * 24 * 60 * 60) +
(((TO_NUMBER(TO_CHAR(SYSDATE, 'DD')) - 1)) * 24 * 60 * 60) +
(TO_NUMBER(TO_CHAR(SYSDATE, 'HH24')) * 60 * 60) +
(TO_NUMBER(TO_CHAR(SYSDATE, 'MI')) * 60) +
(TO_NUMBER(TO_CHAR(SYSDATE, 'SS')))) * (16 * 1024)) -
DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER) /
(16 * 1024 * 60 * 60 * 24)) INDICATOR
FROM V$INSTANCE;
四:该问题的影响:
Oracle SCN的合理生成频率大约为16K/秒,如果该SCN超过合理值范围的话,数据库将会cancel该事务并伴随报错信息。当下一秒,应用再连接的时候,由于SCN的值已经处于合理范围内,业务可以继续执行,对前端应用来看,就好像有个短暂停顿。但是在极端情况下,数据库可能需要需要不得已关闭来保证数据的完整性,所以会引起数据库宕机的情况。
五:该问题产生的原因:
数据库之间可以通过dblink来进行数据访问,当通过dblink进行业务提交的时候,由于数据库之间存在不同的SCN,因此,为了让事务一致,Oracle将会以两者之间较大的SCN来进行同步,更新dblink两端的数据库SCN。但是,如果源数据库出现SCN生成率过高的问题,随着业务的不断运行,SCN的异常就会通过dblink传染到其他相关的数据库,而dblink使用的频率越大,这种传染的速度也就越快。如果企业内部存在网状的dblink结构,那么这将很容易将SCN的问题扩大到全网,极端情况下会引起大范围的宕机。
六:该问题涉及到的补丁
在10.2.0.5版本的数据库中,scn问题涉及到补丁如下四个
PSE1 (12780098)
PSE2 (12748240)
PSE3 RAC only (Originally 13437573, superceded by 13632140) <<<
--注意,PSE3只在某些平台存在补丁
PSE4 (13916709)
SCN问题ORACLE公司前后发布两次补丁,第一次是2012年1月,PSU为:13343471,但是此次补丁并没有修复SCN全部部题,ORACLE公司于2012年7月发布PSU或CPU中修复,因此可以这么说,如果您的数据库打了2012年7月份或之后的PSU或者CPU就解决了绝大部分SCN问题。
关于数据库PSU或CPU对应的发布时间可参考metalink文档:1454618.1
七:如何查看本库PSU版本信息
cd $ORACLE_HOME/OPatch
./opatch lsinventory -bugs_fixed|grep -i 'DATABASE PSU'
9952230 13632743 Sat Aug 18 10:36:35 GMT+08:00 2012DATABASE PSU 10.2.0.5.1 (INCLUDES CPUOCT2010)
10248542 13632743 Sat Aug 18 10:36:35 GMT+08:00 2012DATABASE PSU 10.2.0.5.2 (INCLUDES CPUJAN2011)
11724962 13632743 Sat Aug 18 10:36:35 GMT+08:00 2012DATABASE PSU 10.2.0.5.3 (INCLUDES CPUAPR2011)
12419392 13632743 Sat Aug 18 10:36:35 GMT+08:00 2012DATABASE PSU 10.2.0.5.4 (INCLUDES CPUJUL2011)
12827745 13632743 Sat Aug 18 10:36:35 GMT+08:00 2012DATABASE PSU 10.2.0.5.5 (INCLUDES CPUOCT2011)
13343471 13632743 Sat Aug 18 10:36:35 GMT+08:00 2012DATABASE PSU 10.2.0.5.6 (INCLUDES CPUJAN2012)
第一列加粗部分就是我们所说的PSU,跟据PSU号码查询metalink文档:1454618.1时间即可,跟据输出,我生产库最新PSU为13343471该PSU是2012年4月份的,因此PSE4尚未修复
八:如何查询本库是否安装某个patchORACLE
cd $ORACLE_HOME/OPatch
./opatch lsinventory
该命令最终会输出很多patch或bug号,查询你所安装的patch号是否存在,如果存在,说明已经打过此patch
九:SCN问题解决方法
方法一:打ORACLE官方推存的补丁
说明:该方法有两个难点,如果该库和其它库有dblink连接,那么其它库也要同时做补丁升级,牵涉多少套系统未知,再说其它库是否采取升级你也是无法控制的,如果你只升级本库,那么如果异常同步scn至本库本库会拒绝dblink连接,导致业务失败,也是一种风险,退一万步讲,就算所有数据库补丁升级,升级后会不会出现新的bug也无法预料,因此风险和不可控因素太多
方法二:找查SCN传染源,进行隔离处理
说明:该方法简单而且处理起来难度最低,找到scn异常问题传染源以后进行补丁升级或将dblink用其它方式代替,可避免此类隐患导致故障(个人认为最优方法)
方法三:通过调整隐含参数值最大限度保障业务运行
说明:该方法前提是数据库打了2012年1月份的补丁后,会引入一个新的参数,该参数是控制headroom剩余天数,_EXTERNAL_SCN_REJECTION_THRESHOLD_HOURS该参数默认值是24,建议故障发生后重启再次宕机将该参数设置成1,最大限度紧急恢复业务,然后进行补丁升级,注意,该方法有前提并且仅供应急时使用,ORACLE官方不建议修改此参数值
十:如何查询headroom隐含参数值
select name
,value
,decode(isdefault, 'TRUE','Y','N') as "Default"
,decode(ISEM,'TRUE','Y','N') as SesMod
,decode(ISYM,'IMMEDIATE', 'I',
'DEFERRED', 'D',
'FALSE', 'N') as SysMod
,decode(IMOD,'MODIFIED','U',
'SYS_MODIFIED','S','N') as Modified
,decode(IADJ,'TRUE','Y','N') as Adjusted
,description
from ( --GV$SYSTEM_PARAMETER
select x.inst_id as instance
,x.indx+1
,ksppinm as name
,ksppity
,ksppstvl as value
,ksppstdf as isdefault
,decode(bitand(ksppiflg/256,1),1,'TRUE','FALSE') as ISEM
,decode(bitand(ksppiflg/65536,3),
1,'IMMEDIATE',2,'DEFERRED','FALSE') as ISYM
,decode(bitand(ksppstvf,7),1,'MODIFIED','FALSE') as IMOD
,decode(bitand(ksppstvf,2),2,'TRUE','FALSE') as IADJ
,ksppdesc as description
from x$ksppi x
,x$ksppsv y
where x.indx = y.indx
and substr(ksppinm,1,1) = '_'
and x.inst_id = USERENV('Instance')
)
where name like '%&par%'
order by name
/
Enter value for par: _external_scn_rejection_threshold_hours
ORACLE SCN问题详解(2)--传染源定位

ORACLE SCN增长异常定位传染源将其隔离处理是处理SCN问题最有效的方法,具体定位过程如下:
一:查看alter日志找查传染源

从数据库alter日志中可以看出,系统scn增长过快是因为通过dblink被远端数据库ORCL传染所致,信息详细显示了远端数据库名、用户名、触发机器名等信息,但是该提示是安装2012年1月ORACLE发布的补丁才会有的提示,因此该方法有很大的局限性
二:通过定位传染源方法
1、查询SCN距离Headroom 上限的剩余天数的历史变化
SELECT TIM,
GSCN,
ROUND(RATE),
ROUND((CHK16KSCN - GSCN) / 24 / 3600 / 16 / 1024, 1) "HEADROOM"
FROM (SELECT TIM,
GSCN,
RATE,
((((TO_NUMBER(TO_CHAR(TIM, 'YYYY')) - 1988) * 12 * 31 * 24 * 60 * 60) +
((TO_NUMBER(TO_CHAR(TIM, 'MM')) - 1) * 31 * 24 * 60 * 60) +
(((TO_NUMBER(TO_CHAR(TIM, 'DD')) - 1)) * 24 * 60 * 60) +
(TO_NUMBER(TO_CHAR(TIM, 'HH24')) * 60 * 60) +
(TO_NUMBER(TO_CHAR(TIM, 'MI')) * 60) +
(TO_NUMBER(TO_CHAR(TIM, 'SS')))) * (16 * 1024)) CHK16KSCN
FROM (SELECT FIRST_TIME TIM,
FIRST_CHANGE# GSCN,
((NEXT_CHANGE# - FIRST_CHANGE#) /
((NEXT_TIME - FIRST_TIME) * 24 * 60 * 60)) RATE
FROM V$ARCHIVED_LOG
WHERE (NEXT_TIME > FIRST_TIME)))
ORDER BY 1, 2;
将结果导出EXECEL生成图形:
1、如果是传染源headroom趋势图如下:
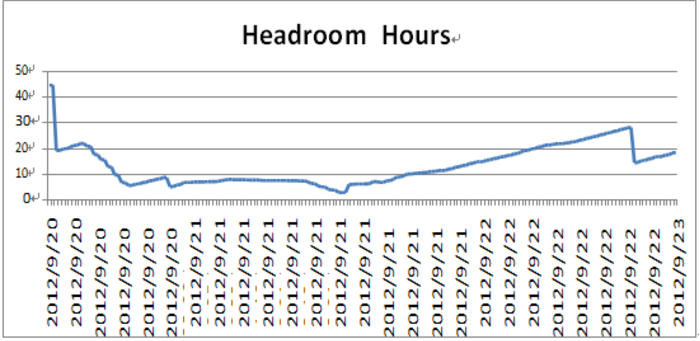
说明:如果 SCN Headroom 的剩余天数的历史变化是相对平滑的趋向于变小,那么就说明内部数据库有应用触发了 Bug,导致 SCN 异常增长,如图上图所示
2、被传染headroom趋势图如下:
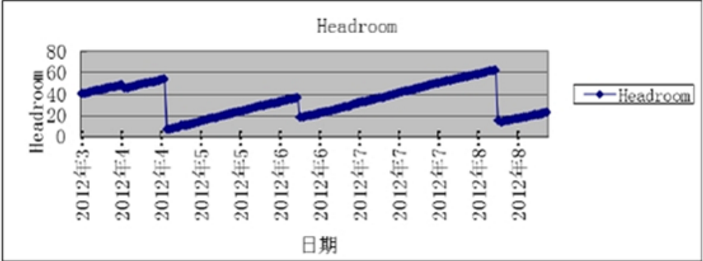
![]()
说明:如果 SCN Headroom 的剩余天数的历史变化很突然,那么就说明数据库主要被外部通过DBLINK 传染,导致 SCN 异常增长;
看一下我管理系统生产库SCN历史变化图:
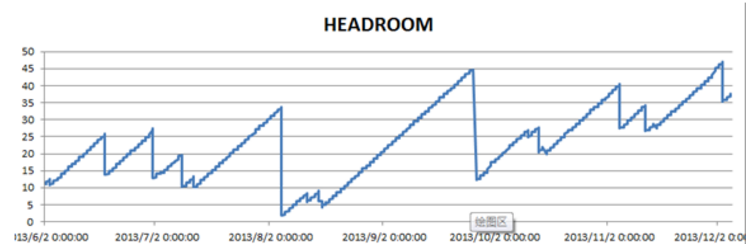
![]()
变化很突然,说明是被传染所致,因此问题的重点是查找传染源(这种方法不太准确)
2、也可以跟据如下脚本判断数据库是否为传染源
SELECT SS.SNAP_ID AS SNAP_ID,
TO_CHAR(SN.BEGIN_INTERVAL_TIME, 'YYYY-MM-DD HH24:MI:SS') AS "SNAP_DATE",
SUM(DECODE(STAT_NAME, 'calls to kcmgas', VALUE, 0)) -
LAG(SUM(DECODE(STAT_NAME, 'calls to kcmgas', VALUE, 0)), 1) OVER(ORDER BY SS.SNAP_ID) "KCMGAS",
TRUNC((SUM(DECODE(STAT_NAME, 'calls to kcmgas', VALUE, 0)) -
LAG(SUM(DECODE(STAT_NAME, 'calls to kcmgas', VALUE, 0)), 1)
OVER(ORDER BY SS.SNAP_ID)) /
TRUNC((CAST(SN.END_INTERVAL_TIME AS DATE) -
CAST(SN.BEGIN_INTERVAL_TIME AS DATE)) * 86400)) "KCMGAS PER SEC"
FROM SYS.DBA_HIST_SYSSTAT SS, SYS.DBA_HIST_SNAPSHOT SN
WHERE SS.SNAP_ID = SN.SNAP_ID
AND SS.STAT_NAME IN ('calls to kcmgas')
AND SS.DBID = SN.DBID
AND SS.INSTANCE_NUMBER = SN.INSTANCE_NUMBER
AND SN.INSTANCE_NUMBER = 1 --替换检查库INSTANCE_NUMBER
AND SN.DBID = 1840233104 --替换检查库DBID
GROUP BY SS.SNAP_ID, SN.BEGIN_INTERVAL_TIME, SN.END_INTERVAL_TIME
ORDER BY SS.SNAP_ID; (此脚本相对而言比较准确)
建议用此脚本进行传染源的定位,这个里面的数据主要是跟据AWR报告保留时间,因此为了能够更好的诊断传染源,最好将AWR报告保留时间设置31天,输出结果第一条值比大(除AWR基线外),不用理会第一条,最点关注除第一条以外的部分结果是否很大!
转自------------------------http://blog.sina.com.cn/s/blog_61cd89f60102eeri.html
这篇关于oracle SCN问题详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





