本文主要是介绍(七) yolov5s自己数据集训练 锥桶检测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0、配置环境
配置yolov5s所需的环境:
框架:pytorch
环境管理:anaconda(推荐)
IDE:pycharm(推荐)
前边系列有讲过,这里先跳过了
数据集准备
数据集,就是针对于自己任务的图片和标签,以自己的应用场景为例需要检测锥桶,数据打标签的方法在上一篇这里https://blog.csdn.net/qq_53086461/article/details/129210323,可以自己手动打标签,或者通过半自动标注,或者别人训练好的模型你拿过来把输出当成是标签。采用的是yolo标签格式,类别,归一化的中心和长宽。
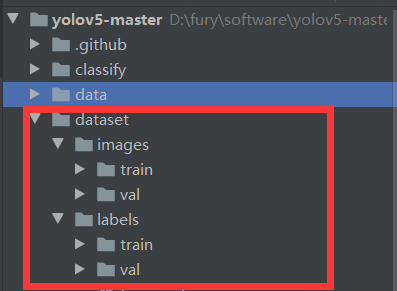
文件关系如下,yolov5-master文件夹内新建dataset,下边包含images和labels:images放是train和val的图片,我这里用了202张训练,110张评估。labels是放着标签文件txt,需要和train和val的图片对应起来。
2、配置yaml文件
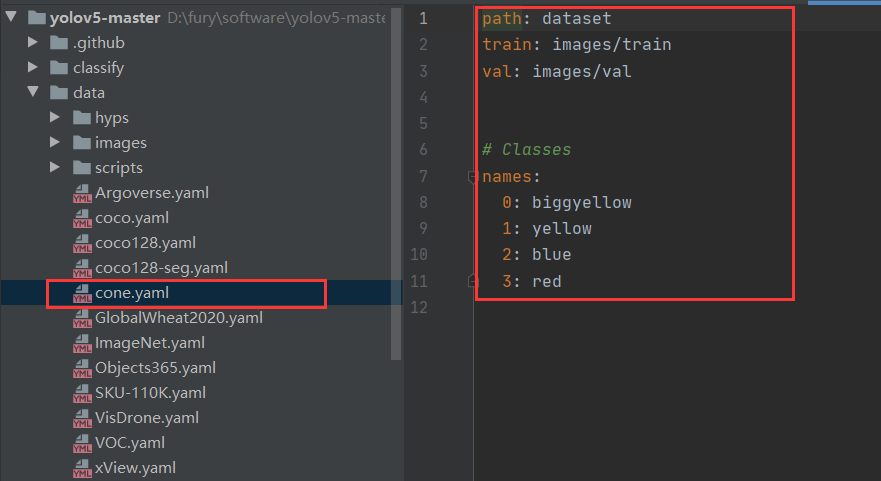
在yolov5-master/data下新建自己的yaml文件
path:dataset位置
train:训练集位置
val:评估集位置
names:就是你自定义的数据中类别名字,因为标签是yolo格式的类别只有数字,所以要做个映射写在这里,以我的数据集为例,就是4个类别,分别是大锥桶、黄色、蓝色、红色。
path: dataset
train: images/train
val: images/val# Classes
names:0: biggyellow1: yellow2: blue3: red3、开始训练
提前配置pycharm
文件位置,你要执行的文件
参数,--weights 写一个预训练模型yolov5s,--data 换成刚才自己的写的yaml文件,根据自己显卡设置--batch-size,因为我是windows做的实验,加上了--worksers 0
切换环境
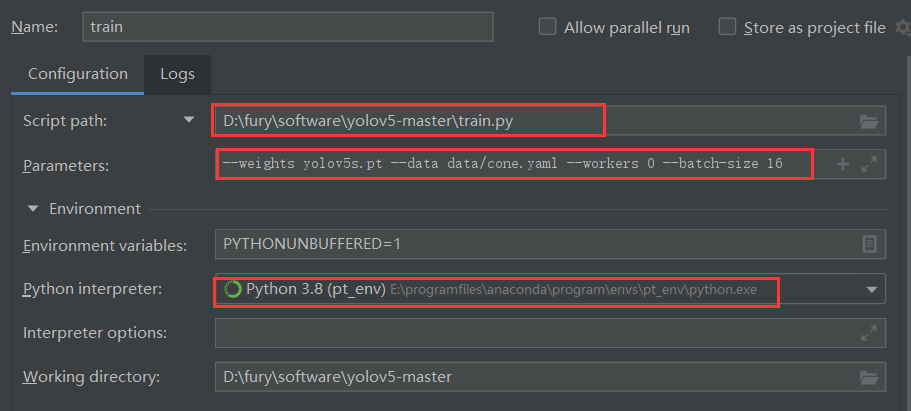
--weights yolov5s.pt --data data/cone.yaml --workers 0 --batch-size 16如果是linux服务器
conda activate 你的环境
cd 你的yolo文件夹
python train.py --weights yolov5s.pt --data data/cone.yaml --workers 0 --batch-size 83.1查看打屏信息
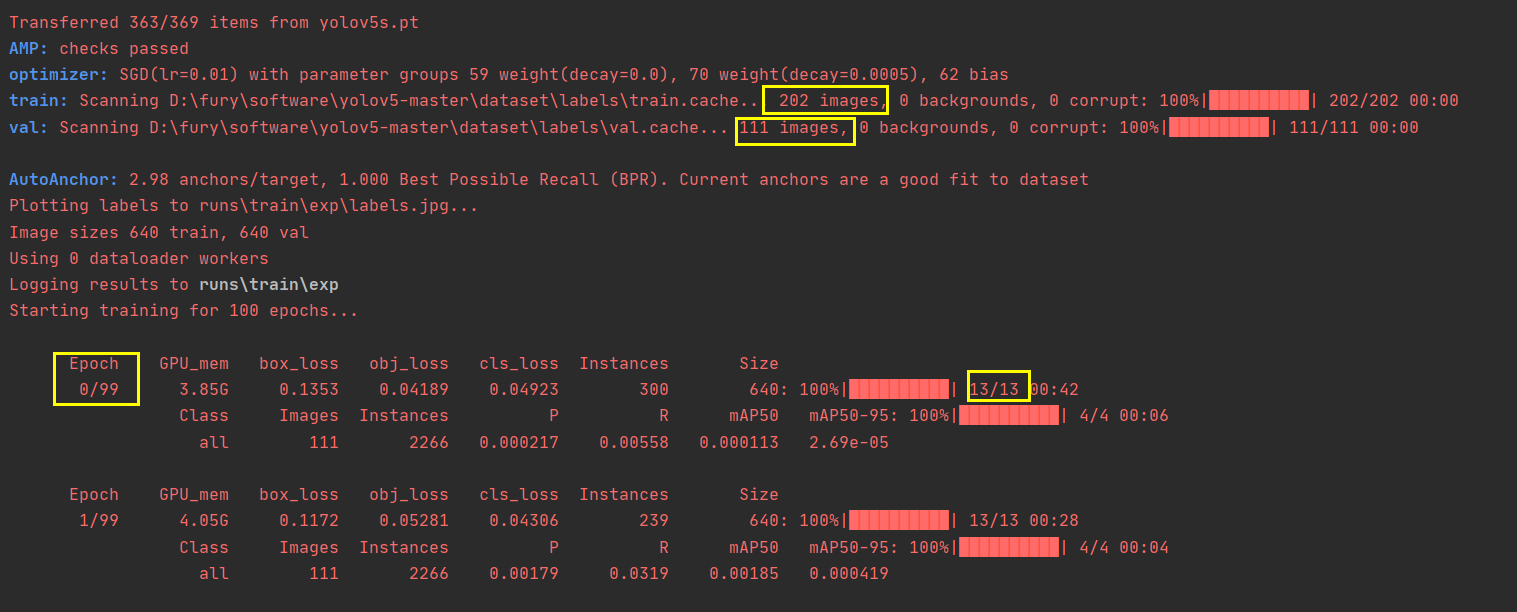
训练202张,评估111张,一共是100个epoch,而每个epoch是13次(202/bachsize),每个epoch大概是30s。设备是笔记本3060 6G,所以自己算一下一个小时左右就可以训练结束。
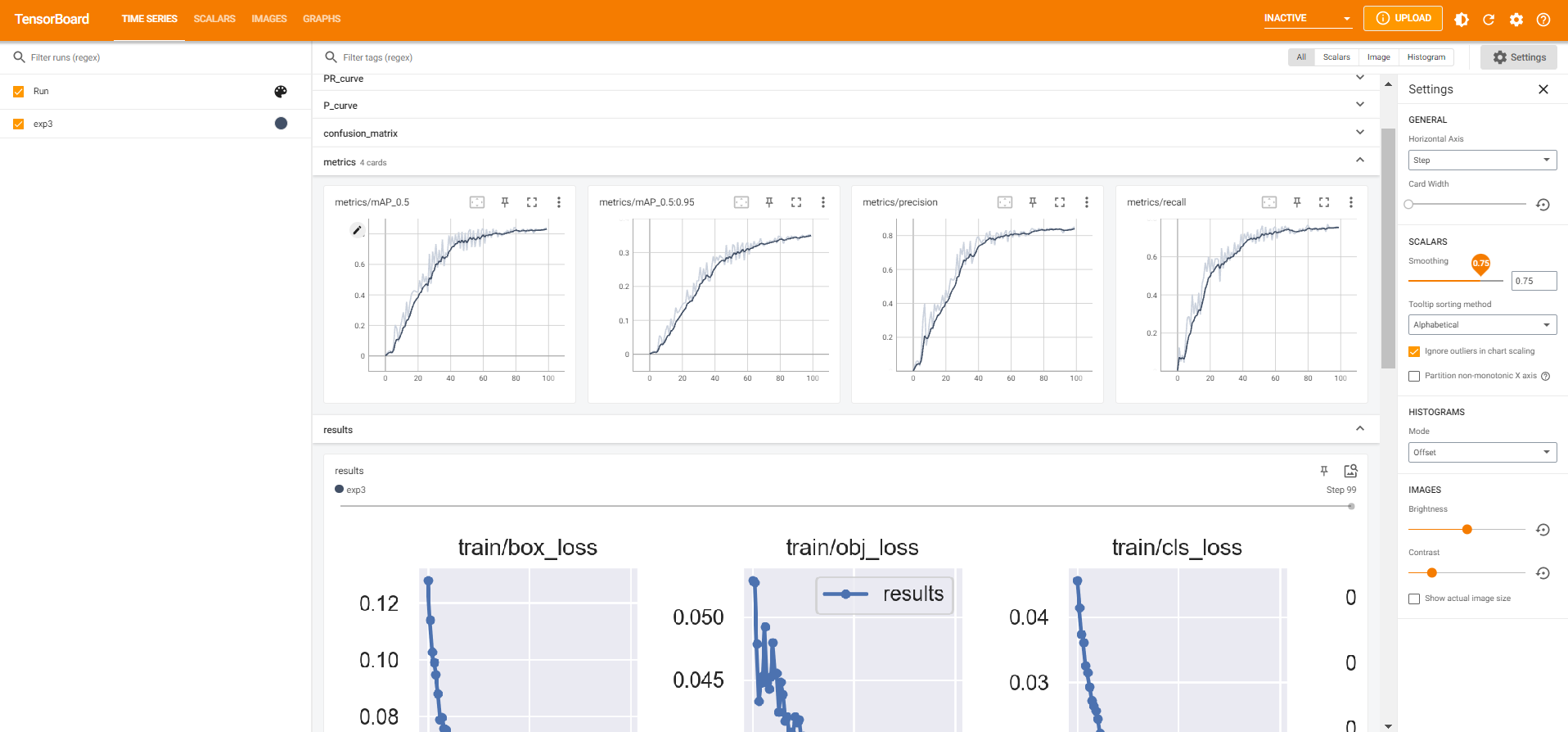
3.2tensorboard查看信息

打开一个anaconda powershell终端,cd到你的文件夹
tensorboard --logdir runs\train会出现一个网址,locolhost:6006,浏览器输入即可,这里会有一些训练的信息,并且通过曲线就可以看到。一些指标,和loss曲线,如果你发现loss不下降那基本训练也没啥用了,或者训练集下降评估集不咋变,就过拟合了,就可以及时停掉省电费。
3.3 查看runs/train/exp

这里也有一些训练过程中结果展示,weights中存放了权重文件,自动保存效果最好的权重文件。
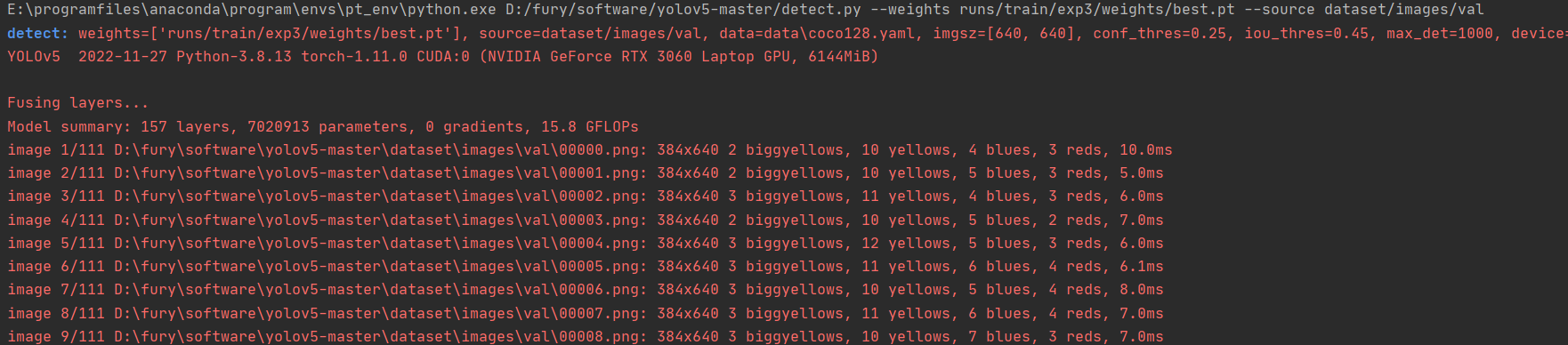
4、测试
训练结束后,会自动测试,并给出一定结果,我们想可视化的看到训练出的结果,可以将刚才训练中pt文件导出来,自己测试。

--weights runs/train/exp3/weights/best.pt --source dataset/images/val运行detect.py,在runs/detect文件夹生成exp

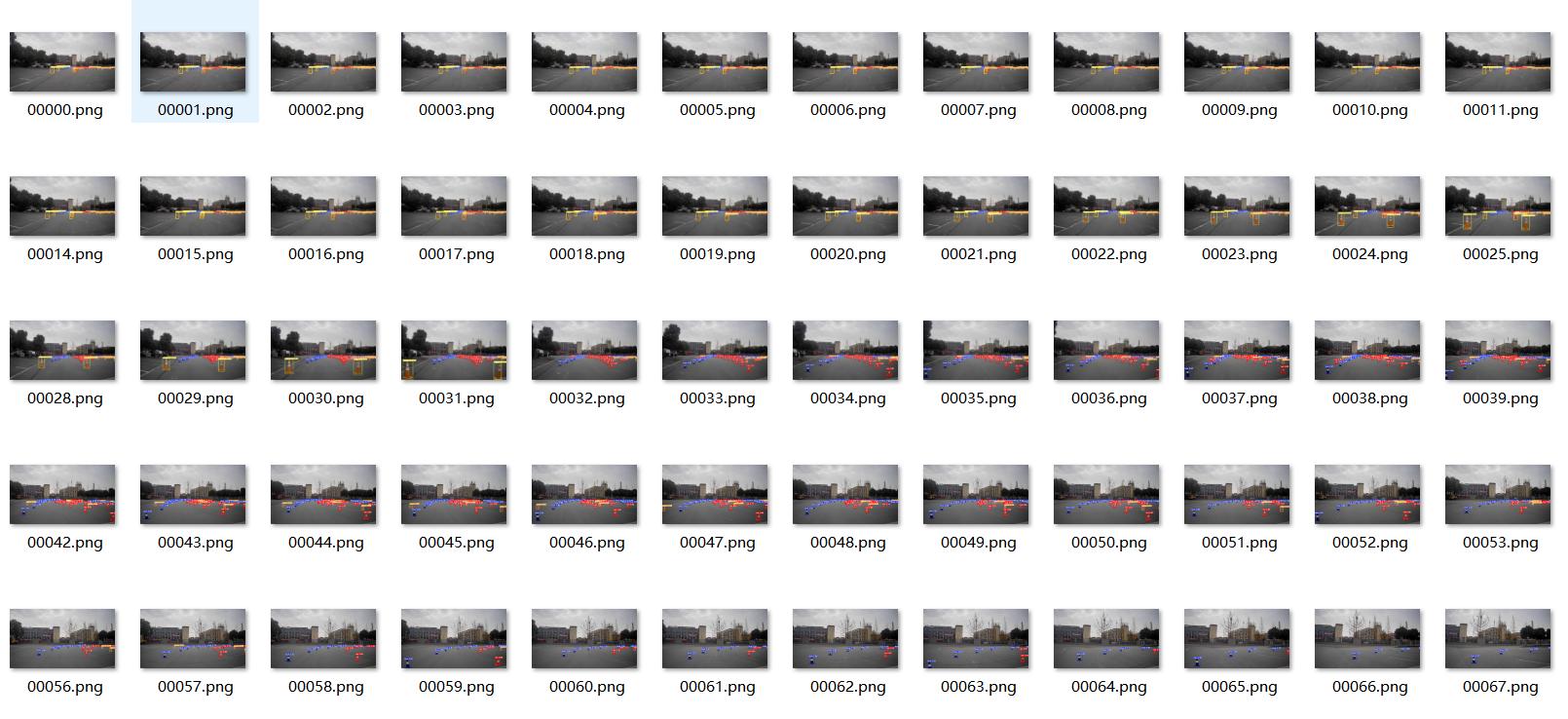
5、其他
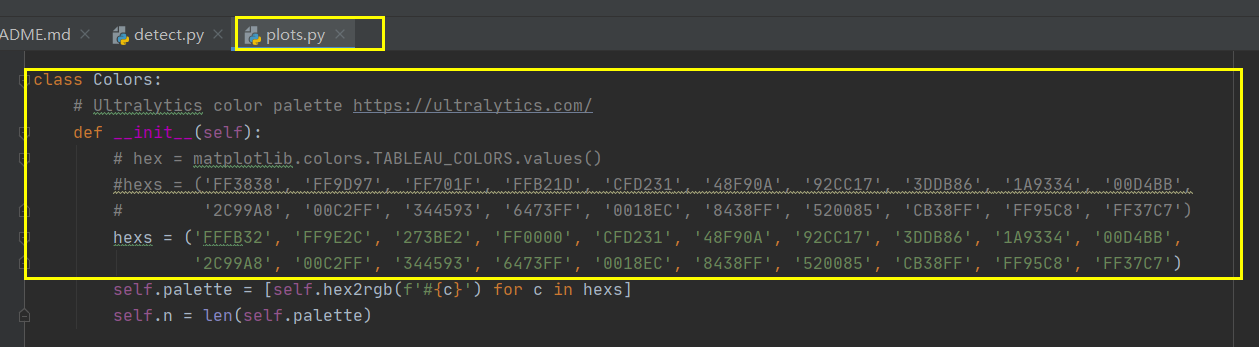
detect 时候 添加--save-txt可以保存标签,这些标签可以用作训练,当数据集不多的时候
--weights runs/train/exp3/weights/best.pt --source dataset/images/val --save-txt2、找到colors,这里我修改了前四个颜色,所以刚好和我的标签颜色对应起来
完结~~~
这篇关于(七) yolov5s自己数据集训练 锥桶检测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





