本文主要是介绍书生·浦语大模型实战营第四次课堂笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
先来看看参考作业
哈哈到这才想起来写笔记
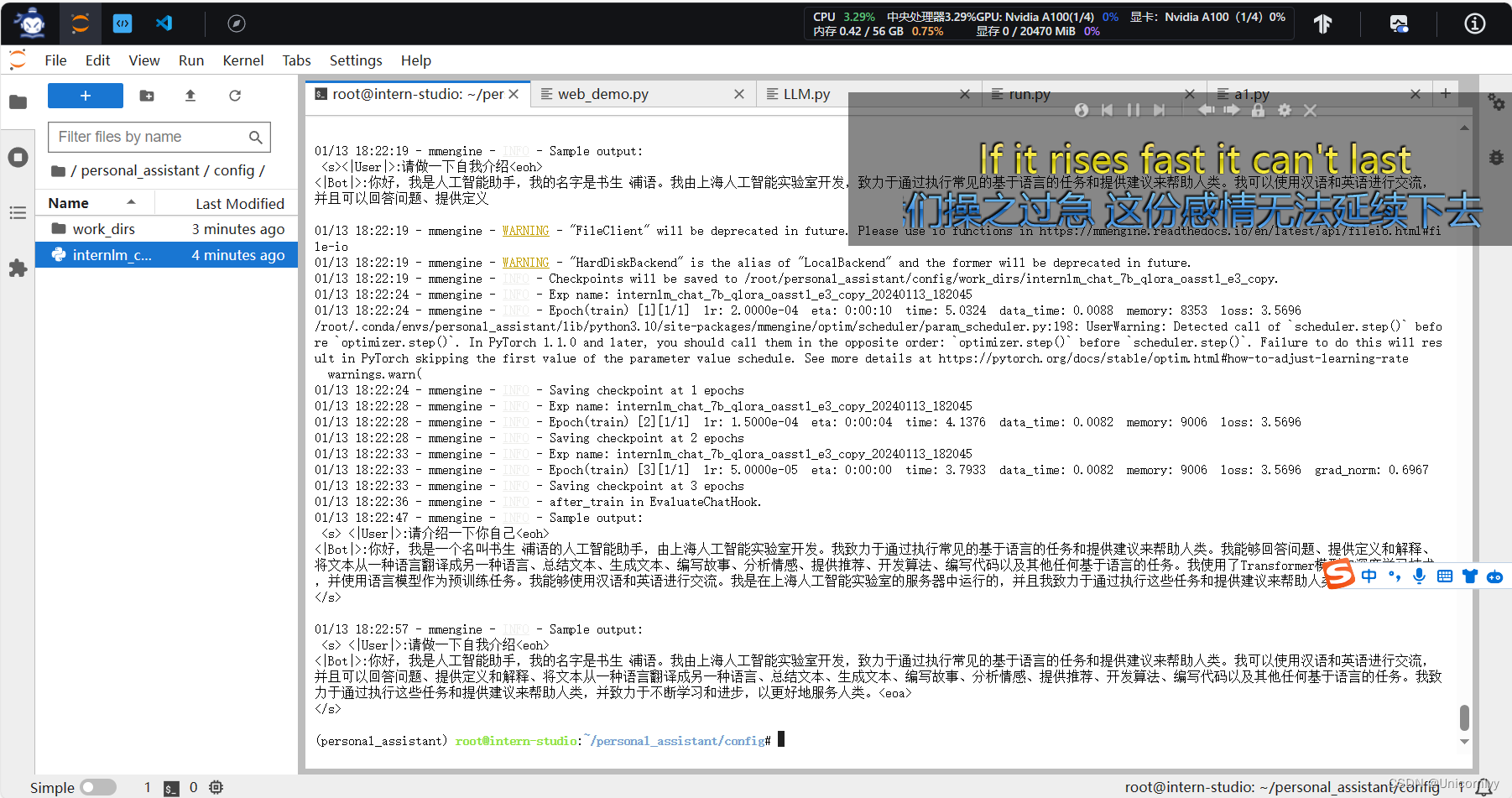
倒回去看发现要求将不要葱姜蒜换成自己的名字和昵称!
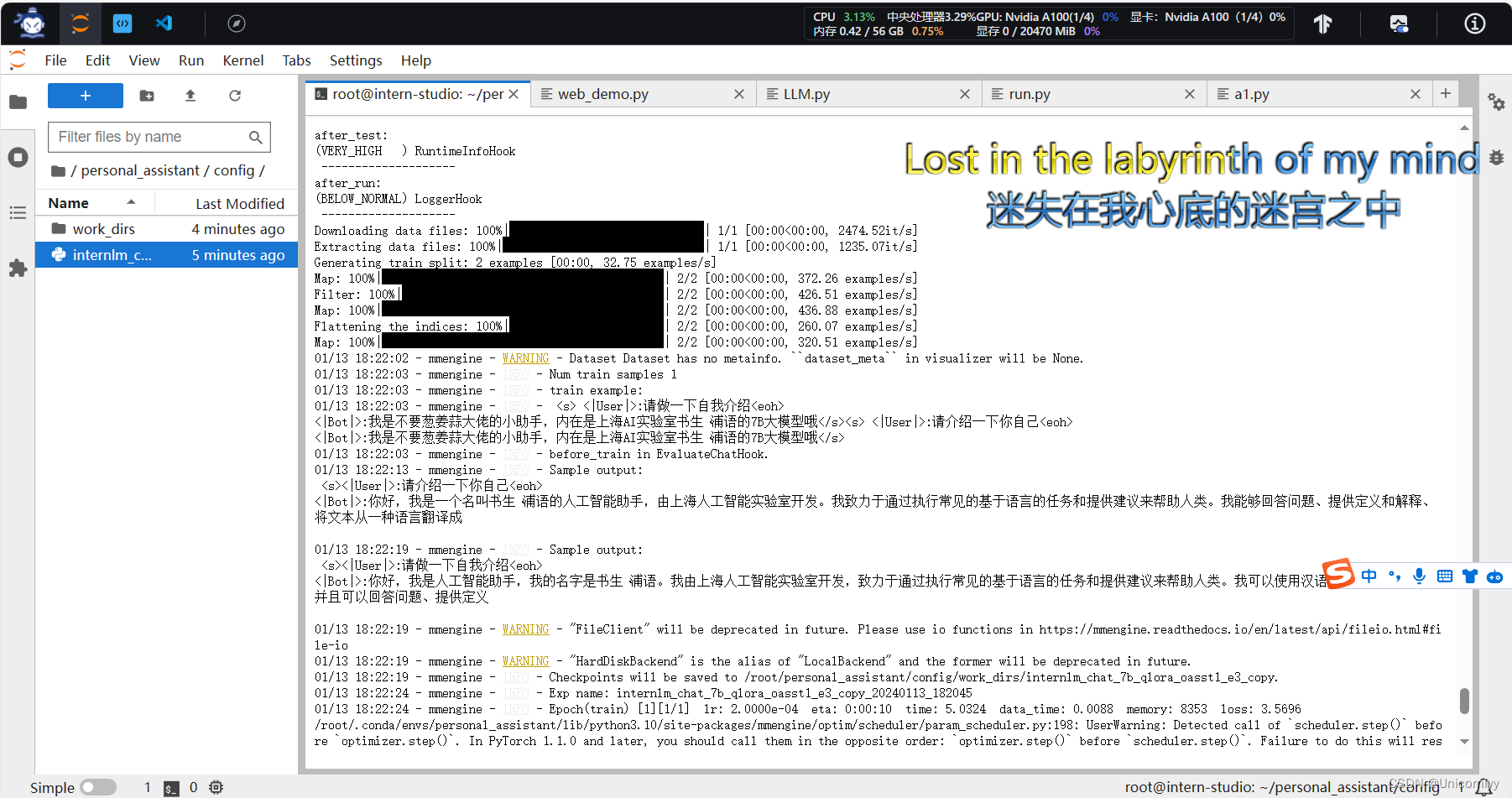
好好好我就是不配玩(换成管理员也不行!)
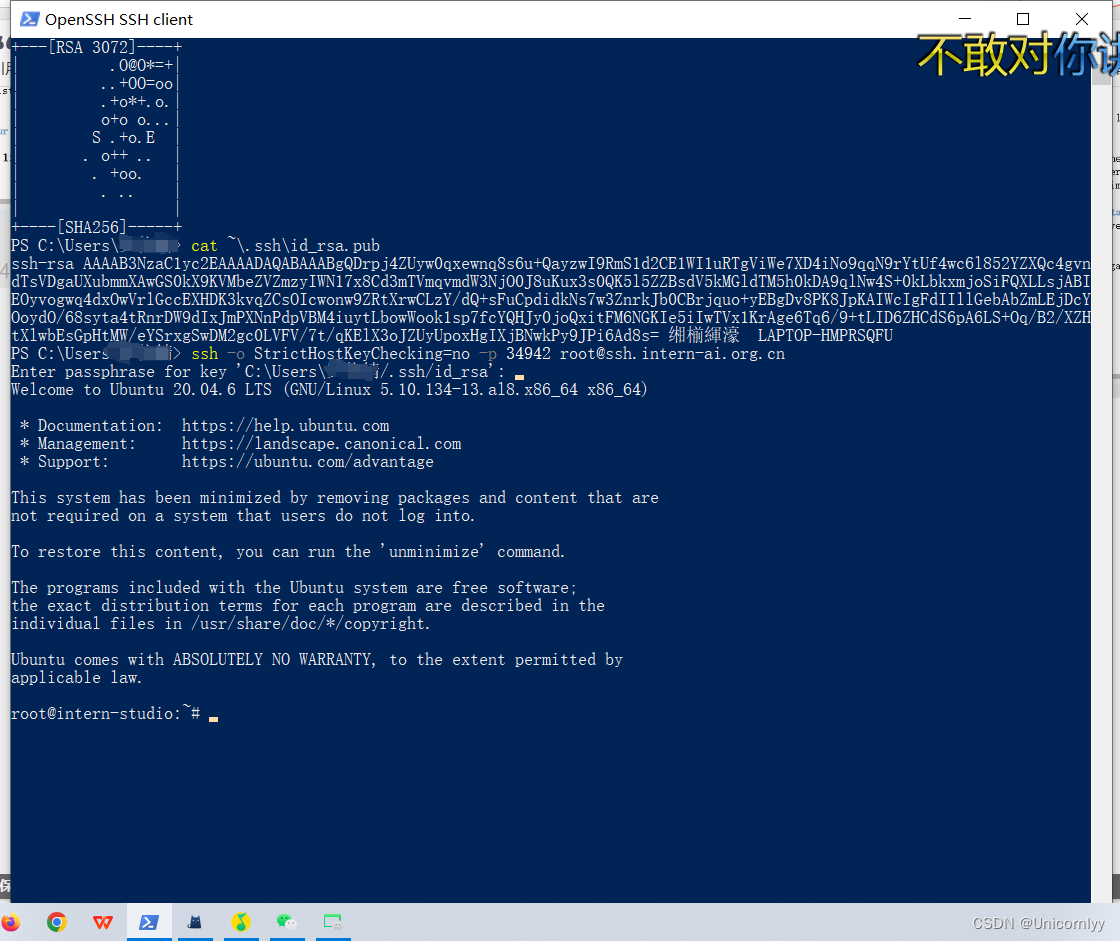
诶怎么能进这个环境?要进双系统ubuntu?
现在看视频发现原来是我进入成功了,可以接着往下做omygod!!!!
但是
还是看看视频吧
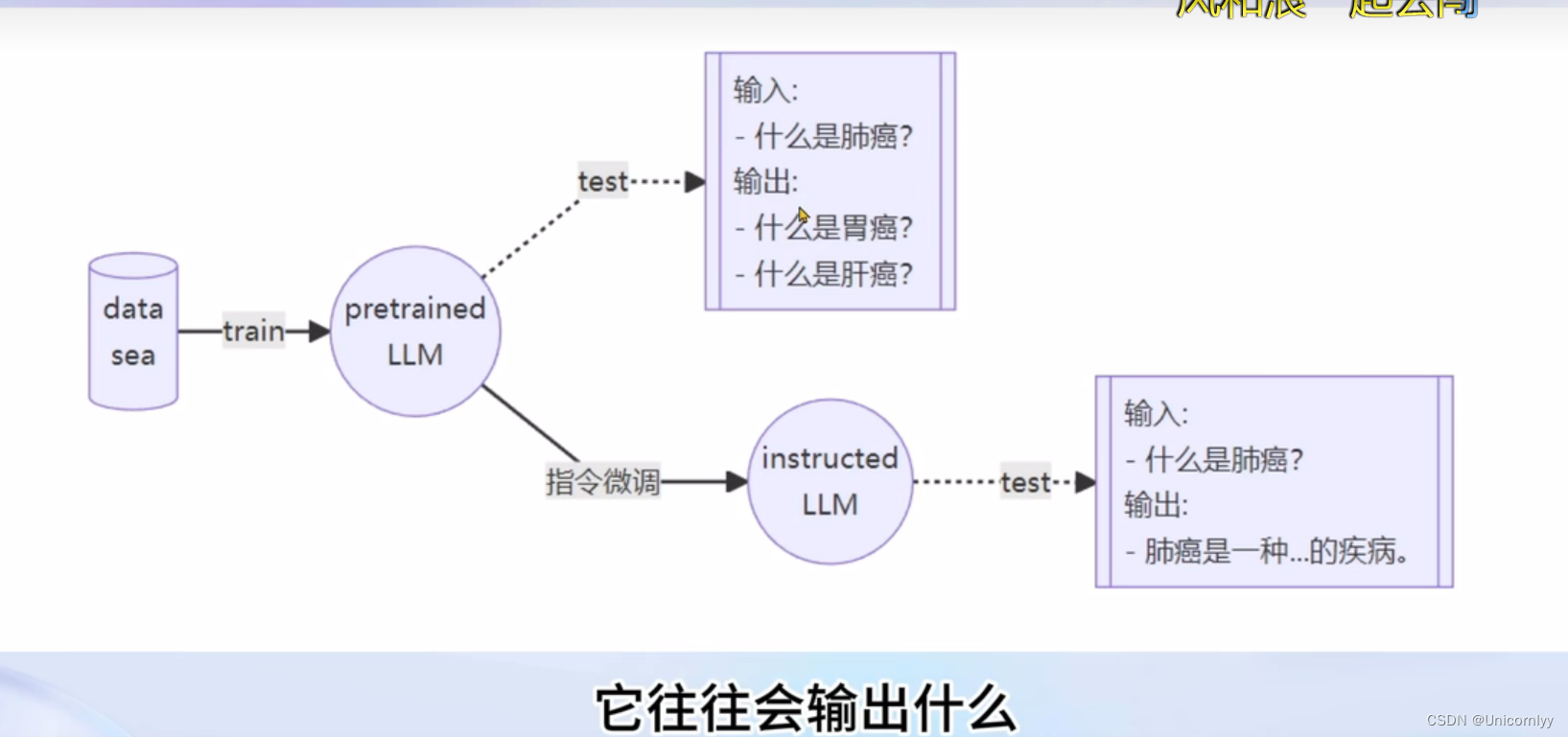
微调是在海量的文本内容的基础上以无监督或半监督的方式进行训练的
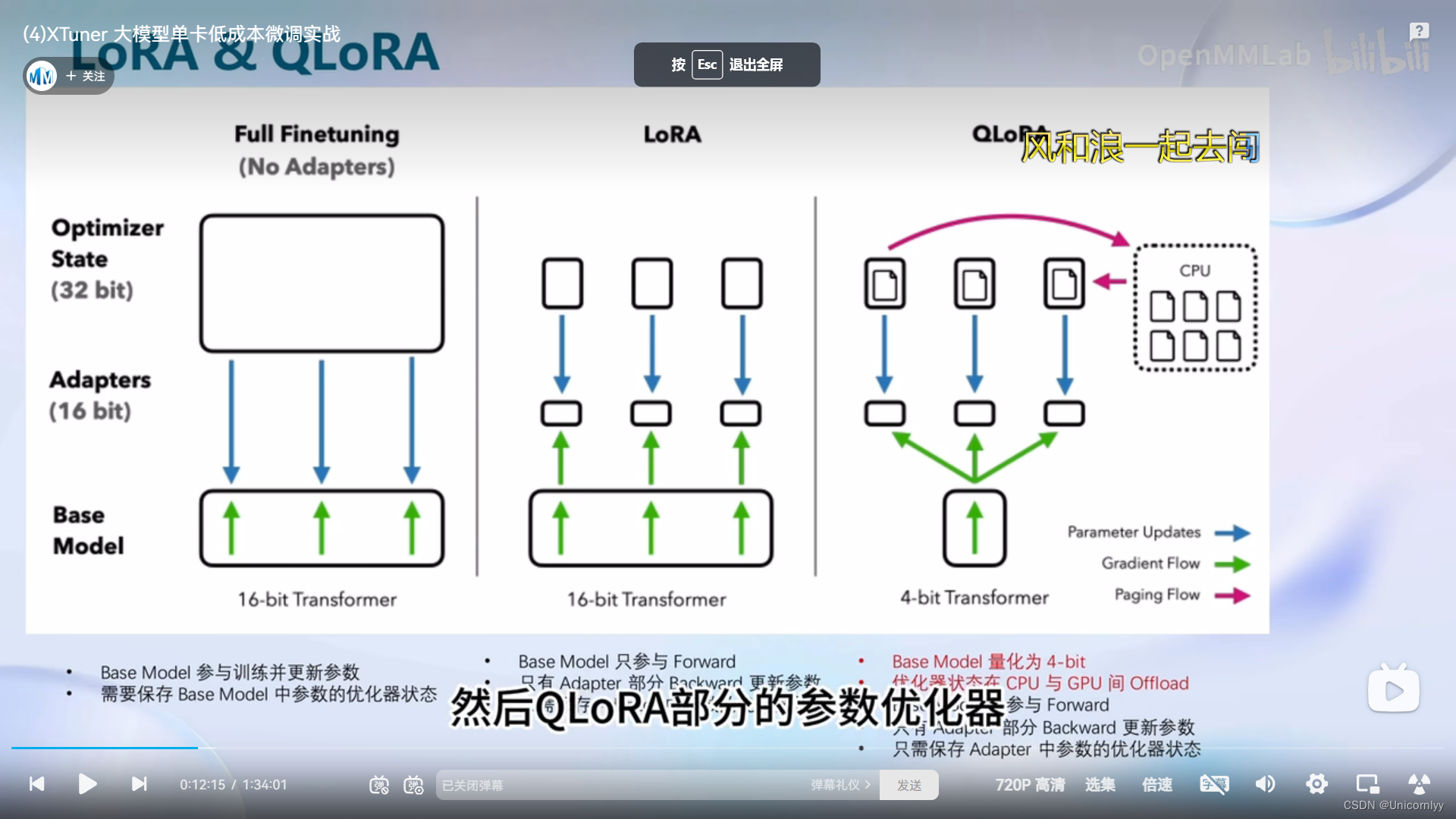
qlora是对lora的一种改进~感觉就是更高级点的工具
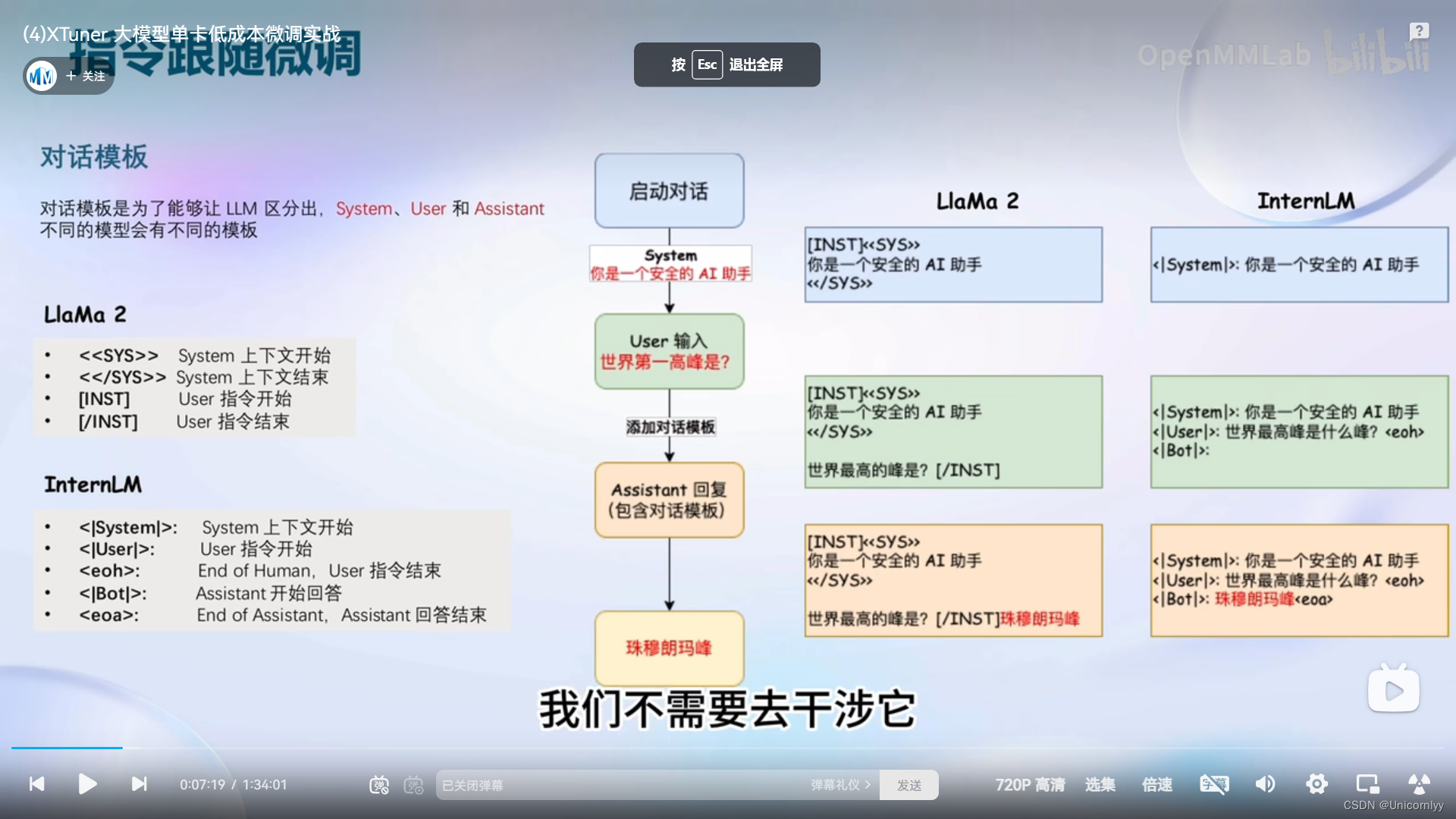
对话模版~

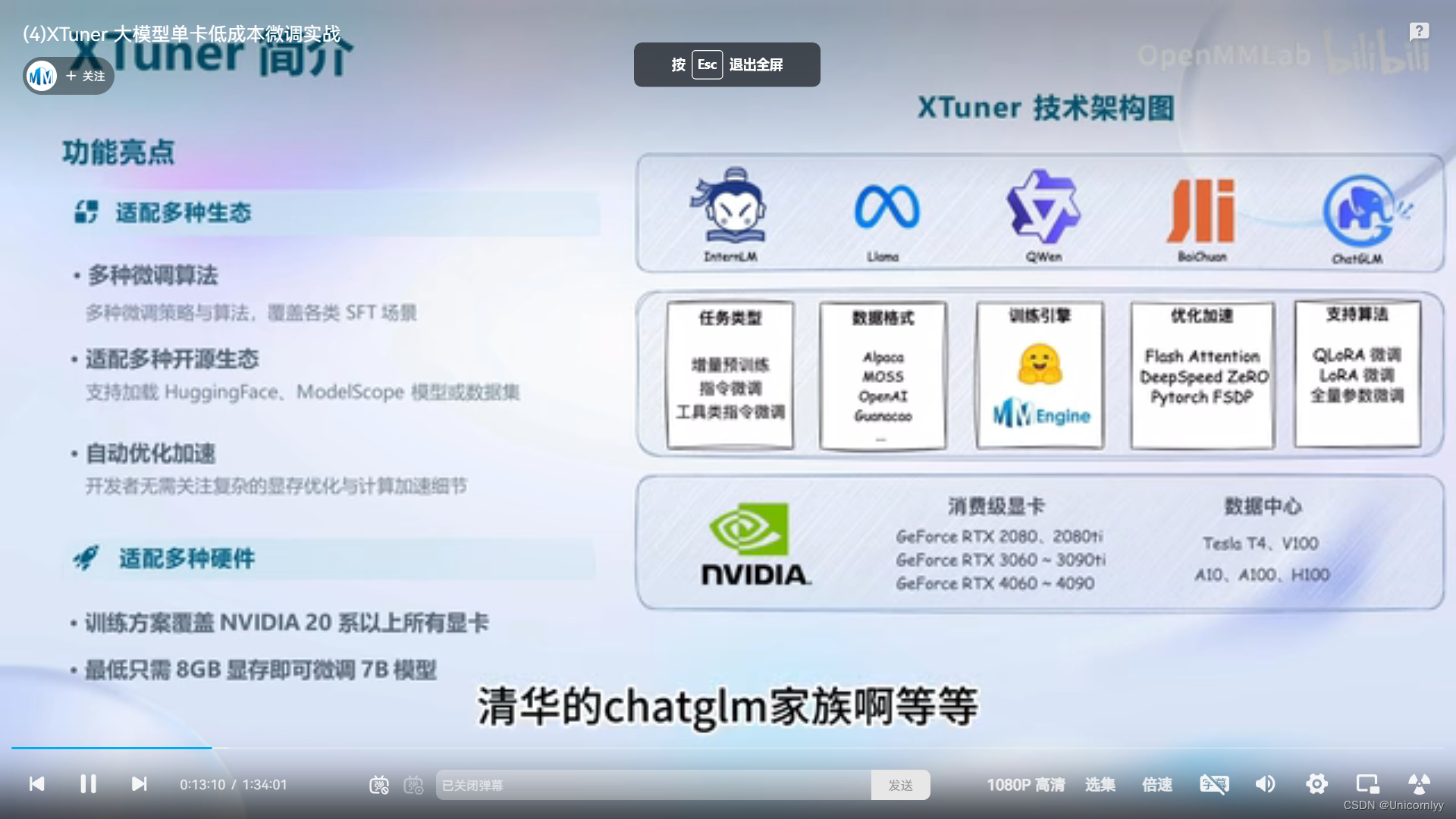
XTuner介绍~
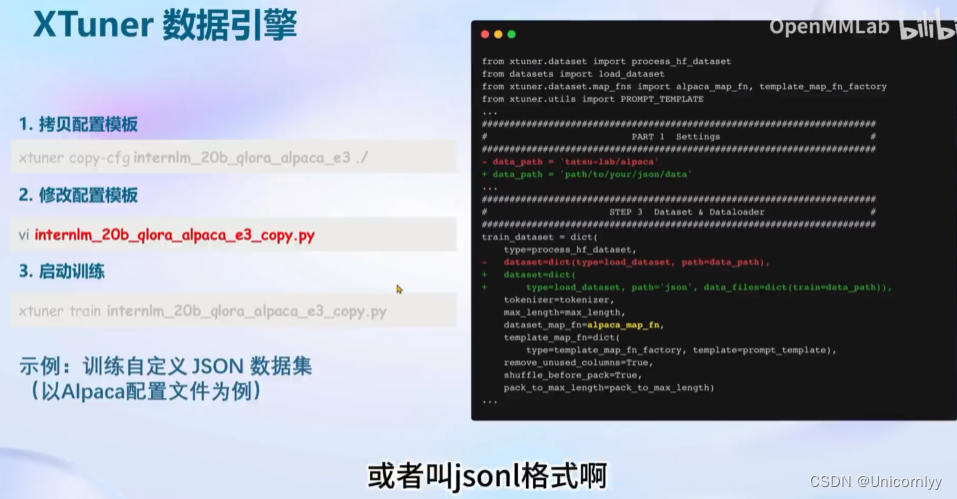
XTuner快速上手:
1.安装(指定版本,在这之前需要创建conda环境
pip install xtuner
2.挑选配置模板
xtuner list-cfg -p internlm_20b
3.一键训练
xtuner train interlm_20b_qlora_512_e3
Config 命名规则
模型名 internlm_20b 无chat代表是基座模型
使用算法 qlora
数据集 oasst1
数据长度 512
Epoch e3,epoch 3
自定义微调
1.拷贝配置模版
xtuner copy-cfg internlm_20b_qlora_oasst1_512_e3 ./
2.修改配置模版
vi internlm_20b_qlora_oasst1_512_e3_copy.py
3.启动训练
xtuner train internlm_20b_qlora_oasst1_512_e3_copy.py
常用超参:
data_path 数据路径或HuggingFace 仓库名
max_length 单条数据最大Token数,超时则截断
pack_to_max_length 是否将多条短数据拼接到max_length,提高GPU利用率
accumulative_counts 梯度累积,每多少backward更新一次参数
evaluation_inputs 训练过程中,会根据给定的问题进行推理,便于观测训练状态
evaluation_freq Evaluation的评测间隔iter数
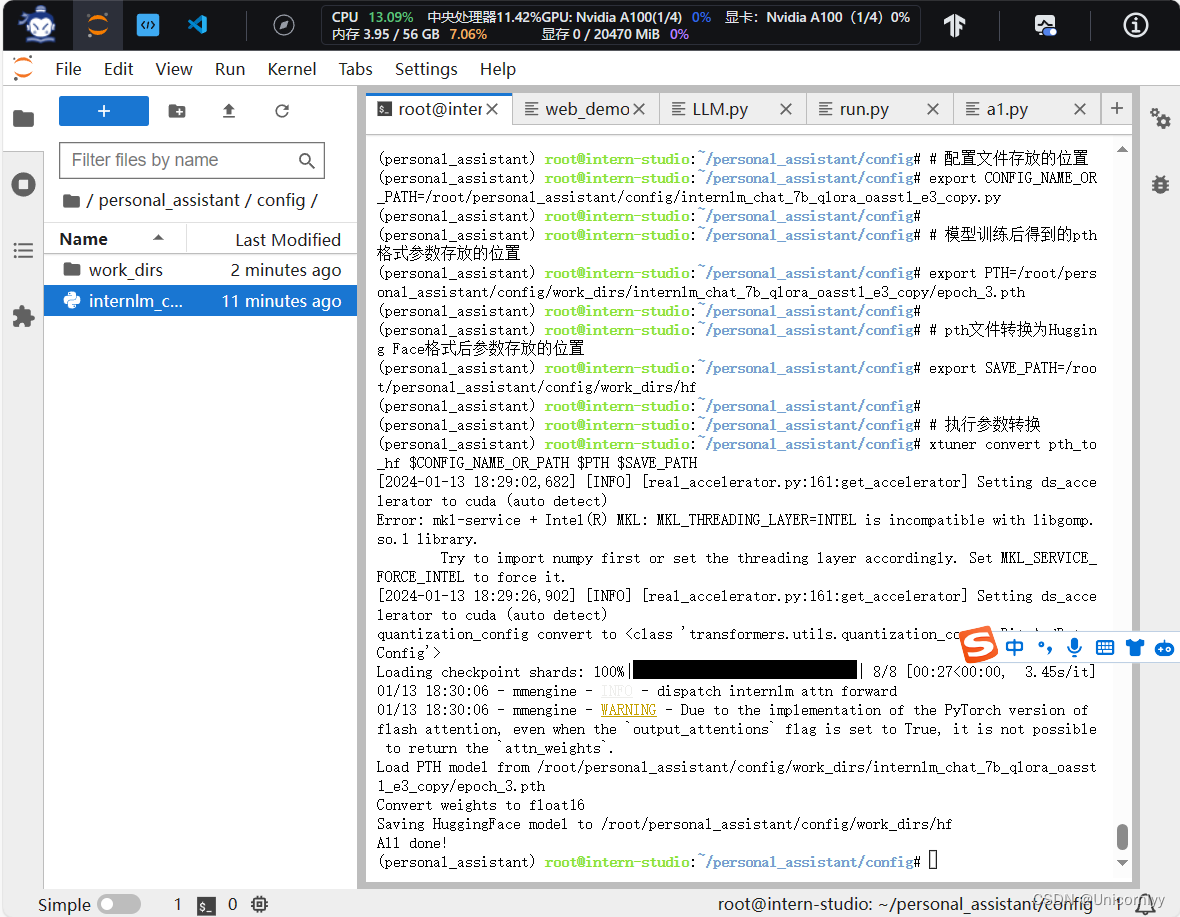
训练完成之后
我们就得到了这个Adapter文件就是所谓的lora文件,我们就需要在加载底座模型的基础上同时加载这个Adapter也就是lora来进行与模型的对话与测试。
为了便于开发者查看训练效果,Xtuner提供了一键对话接口
Float 16模型对话
xtuner chat internlm/internlm-chat-20b
4bit模型对话
xtuner chat internlm/internlm-chat-20b --bits 4
加载Adapter模型对话
xtuner chat internlm/internlm-chat-20b --adapater $ADAPTER_DIR
deepspeed不是默认启动,需要加默认参数
xtuner train internlm_20b_qlora_oasst1_512_e3\ --deepspeed deepspeed_zero3
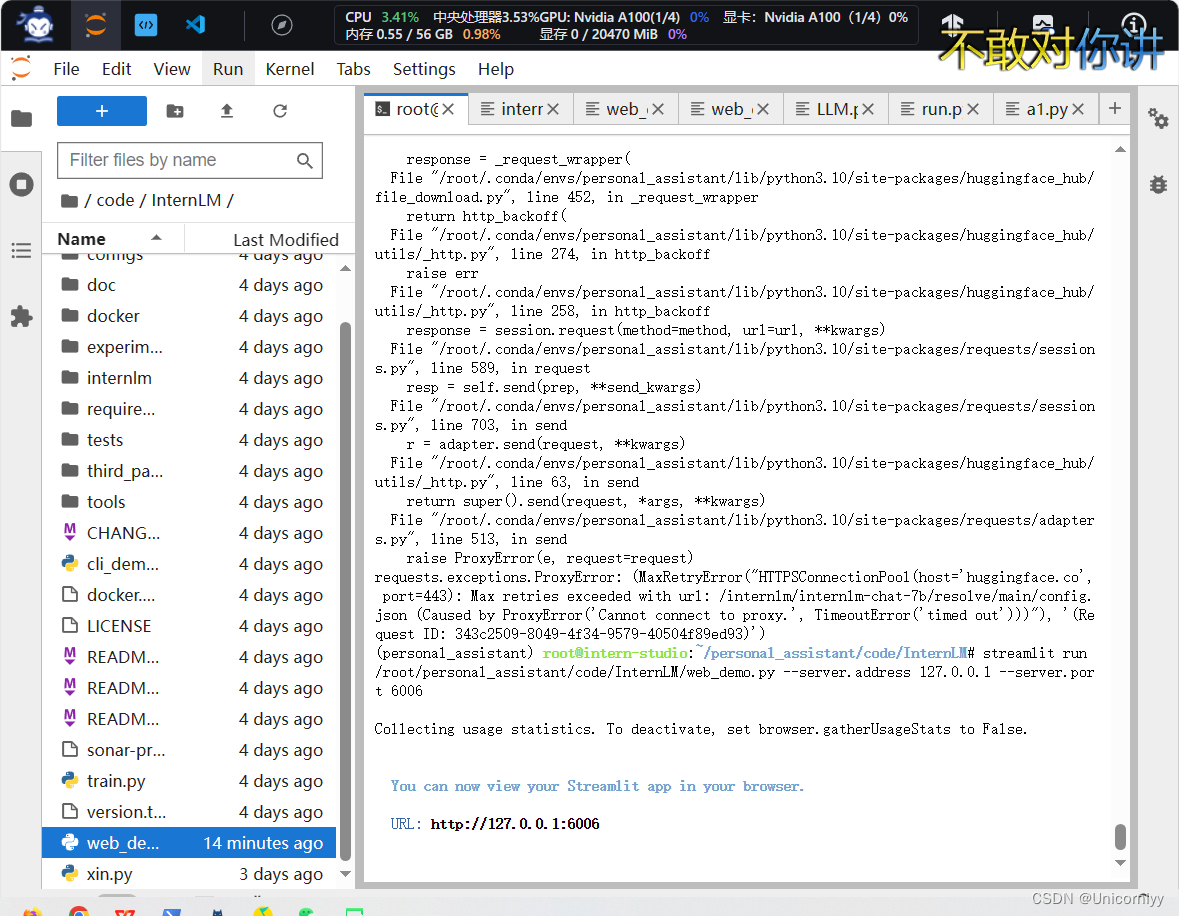
通过问不要葱姜蒜大佬知道了它通过ssh连接的话还是在开发机上也不会下载到本地yes太好了我还能玩~
进入:tmux attach -t finetune
退出:ctrl+b 然后再按d
可以关机让它在后台训练~
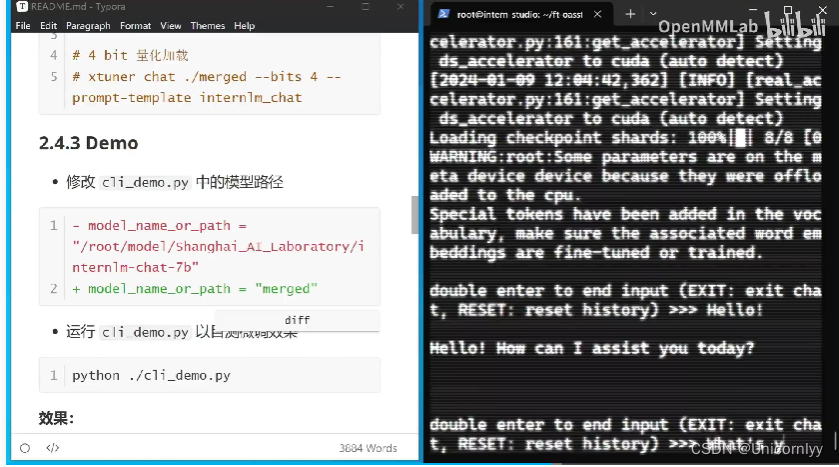
要敲两次回车!看得出来有点慢哈哈
再来写一遍作业
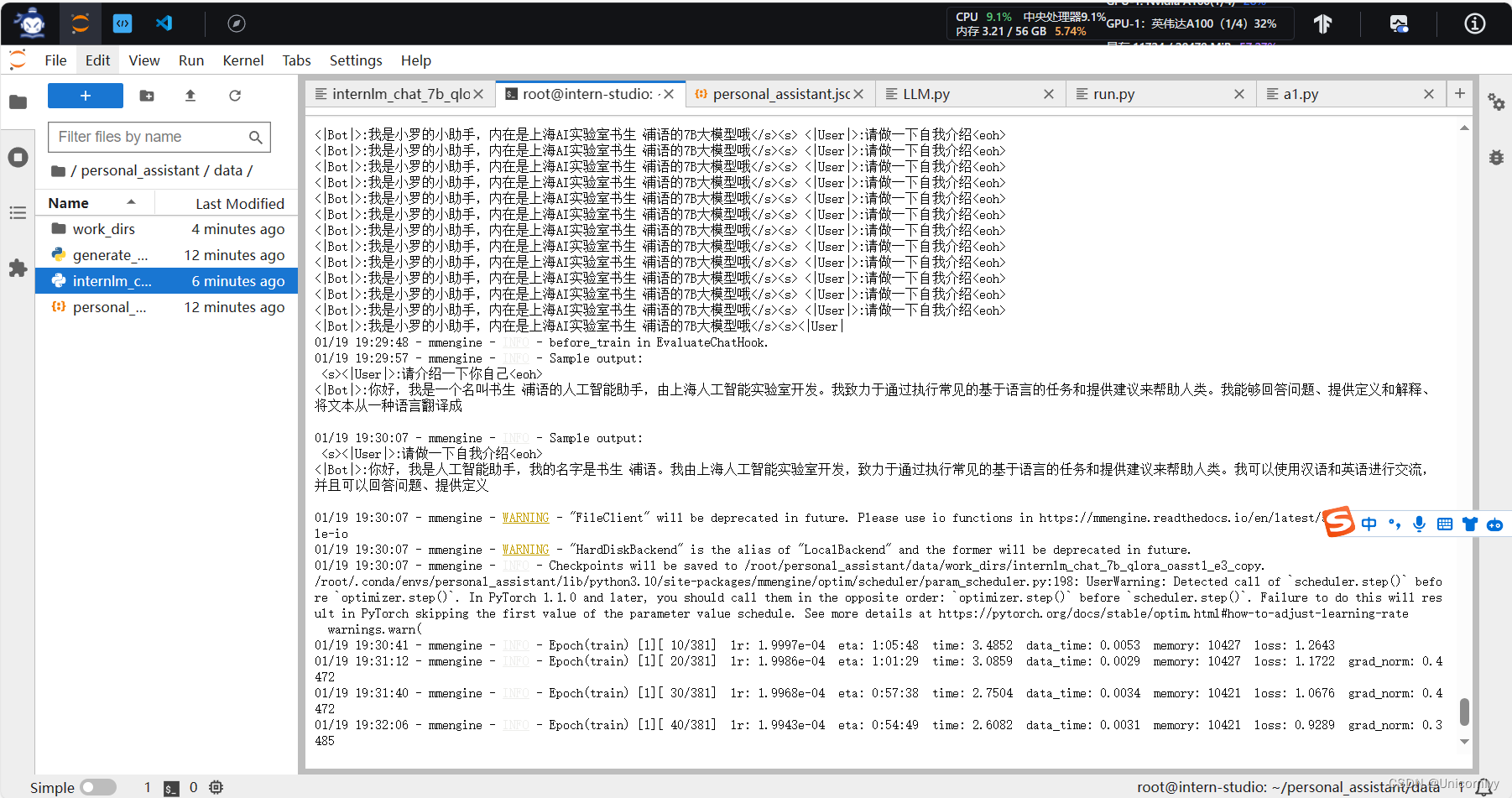
啊这是为啥失败了嘛
原来是需要训练!!!是小罗的助手啦~
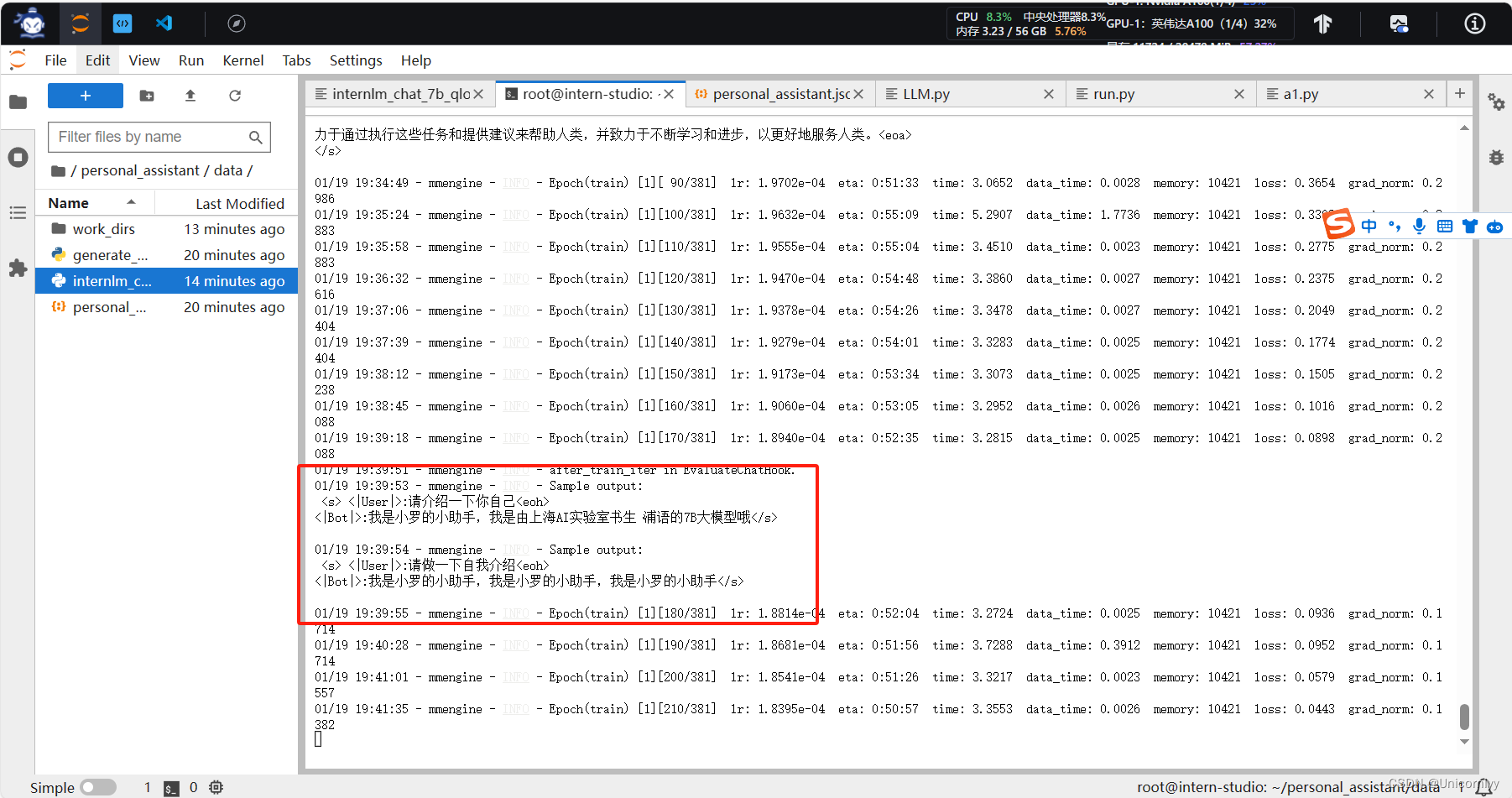

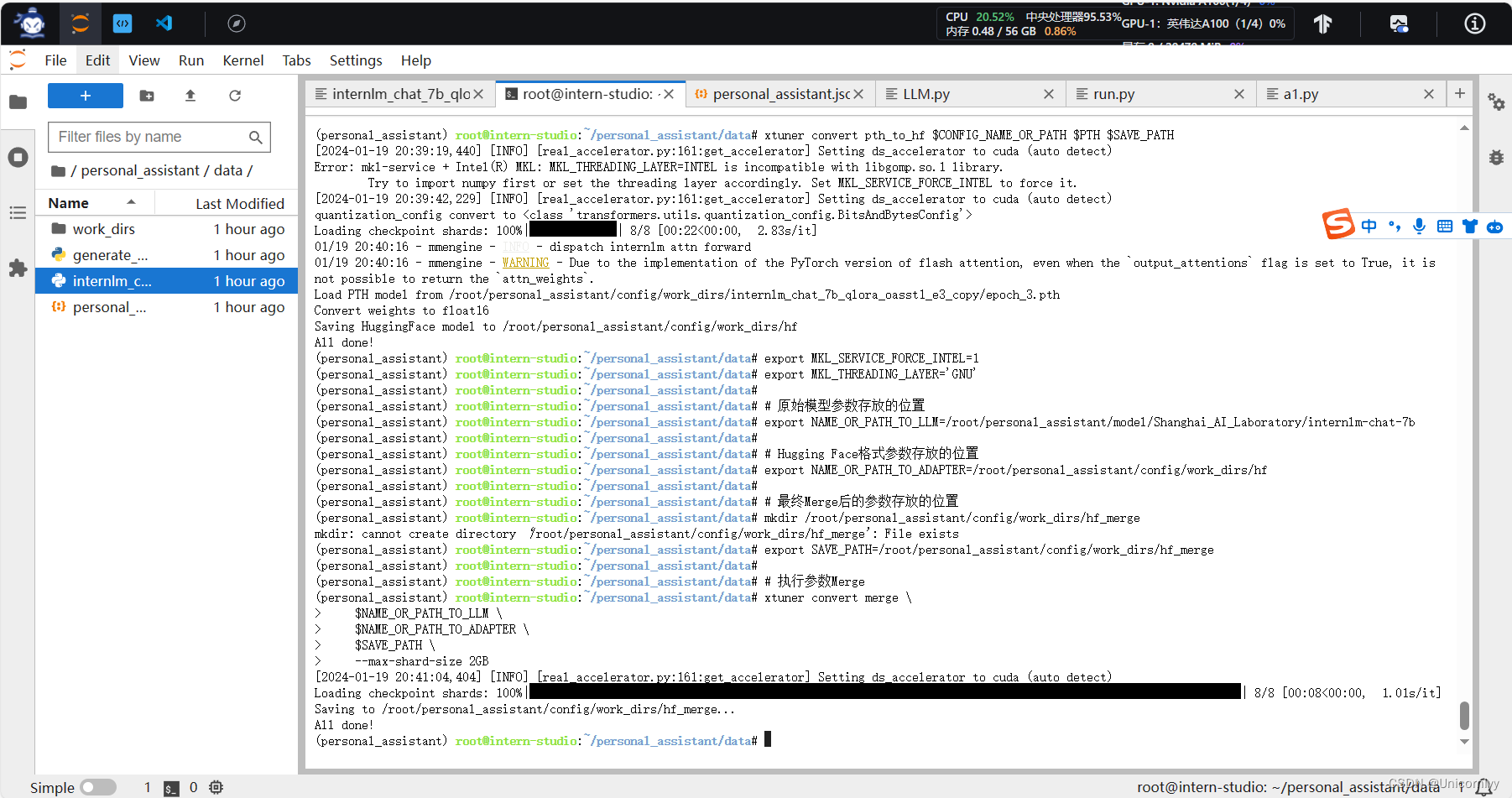
还在加载中
到46%了感觉我的网速有点慢啊~
好好好发现自己

算啦算啦其实差不多了
这篇关于书生·浦语大模型实战营第四次课堂笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





