本文主要是介绍Kafka-消费者-KafkaConsumer分析-Heartbeat,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在前面分析Rebalance操作的原理时介绍到,消费者定期向服务端的GroupCoordinator发送HeartbeatRequest来确定彼此在线。
下面就来详细分析KafkaConsumer中Heartbeat的相关实现。
首先了解一下心跳请求和响应的格式。HeartbeatRequest的消息体格式比较简单,依次包含group_id(String)、group_generation_id(int)、member_id(String)三个字段。HeartbeatResponse消息体只包含一个short类型的error_code。
HeartbeatTask是一个实现DelayedTask接口的定时任务,负责定时发送HeartbeatRequest并处理其响应,此逻辑在其run方法中实现,下面就来分析HeartbeatTask.run()方法的具体流程,如图所示。
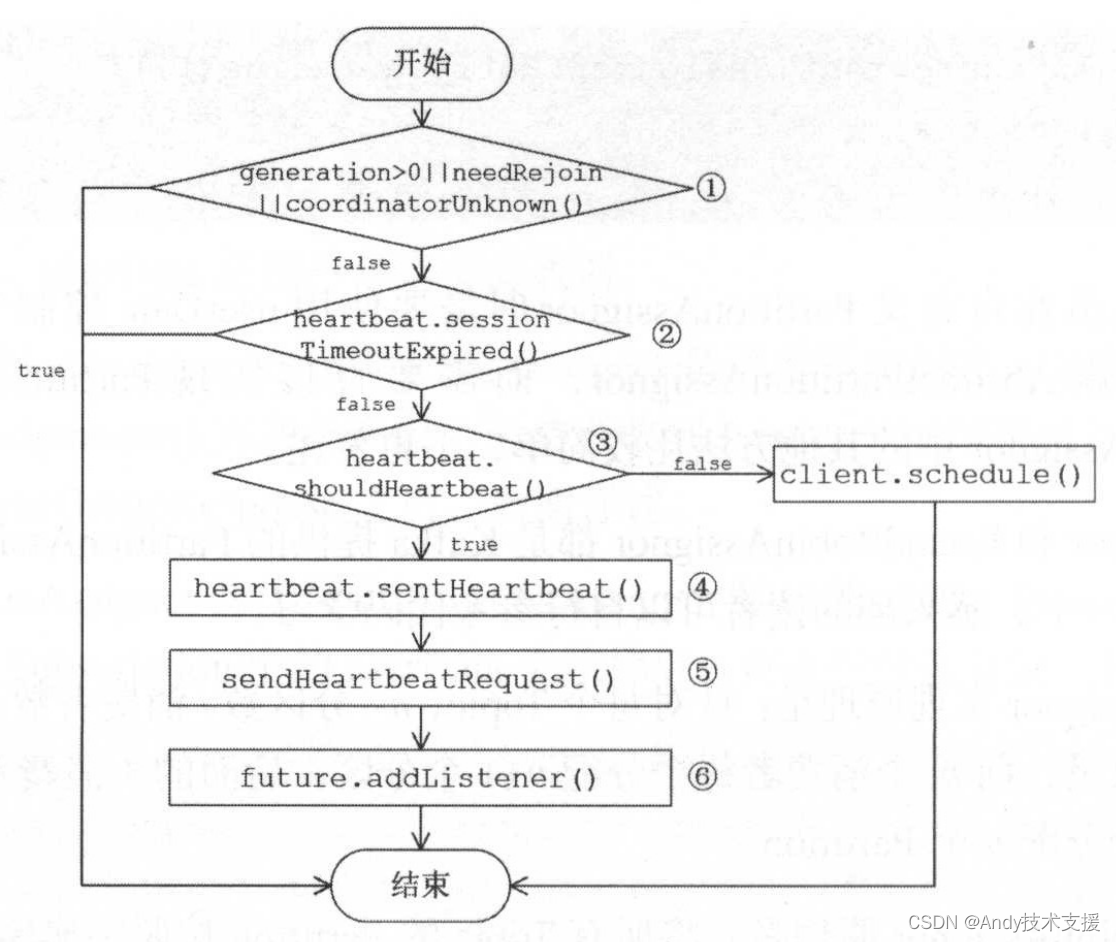
- 首先检查是否需要发送HeartbeatRequest,条件有多个:
- GroupCoordinator已确定且已连接;
- 不处于正在等待Partition分配结果的状态;
- 之前的HeartbeatRequest请求正常收到响应且没有过期。
如果不符合条件,则不再执行HeartbeatTask,等待后续调用reset方法重启HeartbeatTask任务。
-
调用Heartbeat.sessionTimeoutExpired方法,检测HeartbeatResponse是否超时。若超时,则认为GroupCoordinator宕机,调用coordinatorDead方法清空其unsent集合中对应的请求队列并将这些请求标记为异常后结束,将coordinator字段设置为null,表示将重新选择GroupCoordinator。同时还会停止HeartbeatTask的执行。
-
检测HeartbeatTask是否到期,如果不到期则更新其到期时间,将HeartbeatTask对象重新添加到DelayedTaskQueue中,等待其到期后执行;如果已到期则继续后面的步骤,发送HeartbeatRequest请求。
-
更新最近一次发送HeartbeatRequest请求的时间,将requestinFlight设置为true,表示有未响应的HeartbeatRequest请求,防止重复发送。
-
创建HeartbeatRequest请求,并调用ConsumerNetworkClient.send方法,将请求放入unsent集合中缓存并返回RequestFuture。在后面的ConsumerNetworkClient.poll()操作中会将其发送给GroupCoordinator。
-
在RequestFuture对象上添加RequestFutureListener。
下面介绍一下HeartbeatResponse相关的处理。首先需要注意上面介绍的sendHeartbeatRequest()方法,它使用HeartbeatCompletionHandler将client.send方法返回的RequestFuture适配成RequestFuture后返回。:
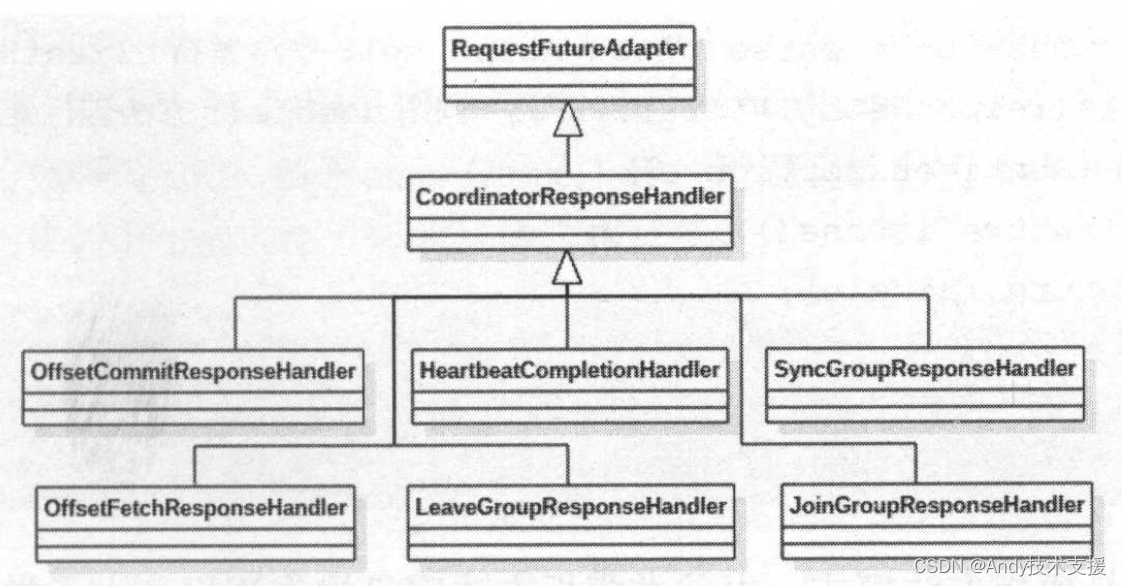
CoordinatorResponseHandler是一个抽象类,其中有pasre和handle()两个抽象方法,parse()方法对ClientResponse进行解析,得到指定类型的响应;handle()方法对解析后的响应进行处理。
CoordinatorResponseHandler实现了RequestFuture抽象类的onSuccess方法和onFailure方法。
处理HeartbeatResponse的相关处理流程如图所示。
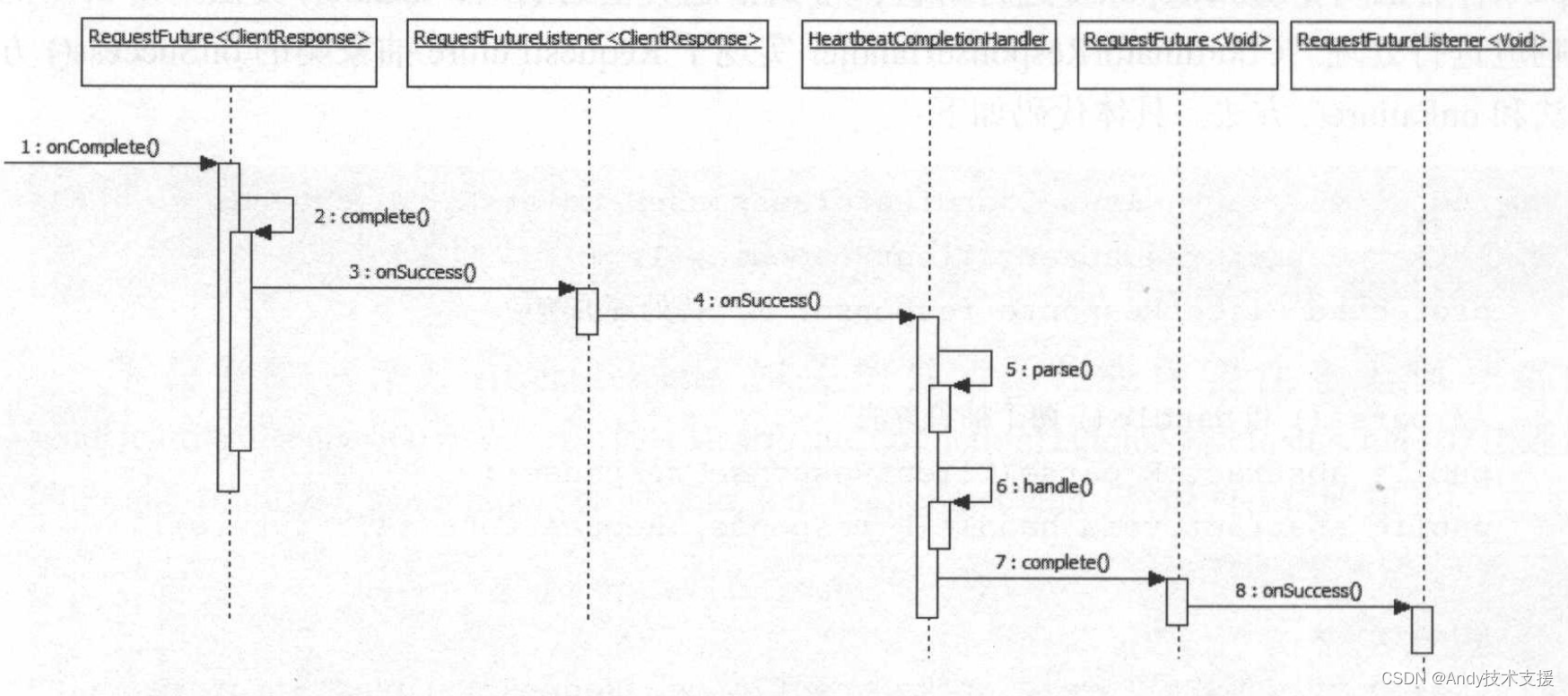
RequestFuture和RequestFutureListener只是为了实现适配器的功能,并没有实际处理逻辑。
当ClientResponse传递到HeartbeatCompletionHandler处时,会通过parse方法解析成HeartbeatResponse,然后进入handle方法处理。
在HeartbeatCompletionHandler.handle方法中,判断HeartbeatResponse中是否包含错误码,如果不包含,则调用RequestFuture的complete(null)方法,将HeartbeatResponse成功的事件传播下去;
反之,针对不同类型错误码分类处理,并调用raise()方法设置对应异常。
例如,错误码是ILLEGAL_GENERATION,表示HeartbeatRequest中携带的generationld过期,GroupCoordinator已经开始新的一轮Rebalance操作,则将rejoinNeeded设置为true,这会重新发送JoinGroupRequest请求尝试加入Consumer Group,也会导致HeartbeatTask任务停止。
如果错误码是UNKNOWN_MEMBER_ID,表示GroupCoordinator识别不了此Consumer,则清空memberld,尝试重新加入Consumer Group。

HeartbeatCompletionHandler.handle()方法中会调用RequestFuture的complete方法或raise方法,这两个方法中没有处理逻辑,但是会触发其上的RequestFutureListener(在HeartbeatTaskrun)方法的步骤6中注册),此监听器会将requestlnFlight设置为false,表示所有HeartbeatRequest都已经完成,并将HeartbeatTask重新放入定时任务队列,等待下一次到期执行。
这篇关于Kafka-消费者-KafkaConsumer分析-Heartbeat的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







