本文主要是介绍机器学习:holdout法(Python),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder, StandardScaler # 类别标签编码,标准化处理
from sklearn.decomposition import PCA # 主成分分析
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, accuracy_score # 分类报告,正确率wdbc = pd.read_csv("breast+cancer+wisconsin+diagnostic/wdbc.data", header=None)
X, y = wdbc.loc[:, 2:].values, wdbc.loc[:, 1] # 提取特征数据和样本标签集
X = StandardScaler().fit_transform(X) # 对样本特征数据进行标准化
lab_en = LabelEncoder() # 对目标值进行编码,创建对象
y = lab_en.fit_transform(y) # 拟合和转换
lab_en.classes_, lab_en.transform(["B", "M"])
# 降噪,降维,可视化
pca = PCA(n_components=6).fit(X) # 选取6个主成分, 30维-->6维,信息损失了约11%
evr = pca.explained_variance_ratio_ # 解释方差比,即各个主成分的贡献率
print("各主成分贡献率", evr, "\n累计贡献率", np.cumsum(evr))
X_pca = pca.transform(X)
# print(X_pca[:5, :])plt.figure(figsize=(21, 5))
X_b, X_m = X_pca[y == 0], X_pca[y == 1] # 把降维后的数据按类别分别提取
for i in range(3):plt.subplot(131 + i)plt.plot(X_b[:, i * 2], X_b[:, i * 2 + 1], "ro", markersize=3, label="benign")plt.plot(X_m[:, i * 2], X_m[:, i * 2 + 1], "bx", markersize=5, label="maligant")plt.legend(frameon=False)plt.grid(ls=":")plt.xlabel(str(2 * i + 1) + "th principal component", fontsize=12)plt.ylabel(str(2 * i + 2) + "th principal component", fontsize=12)plt.title("Each category of data dim reduction by PCA", fontsize=12)
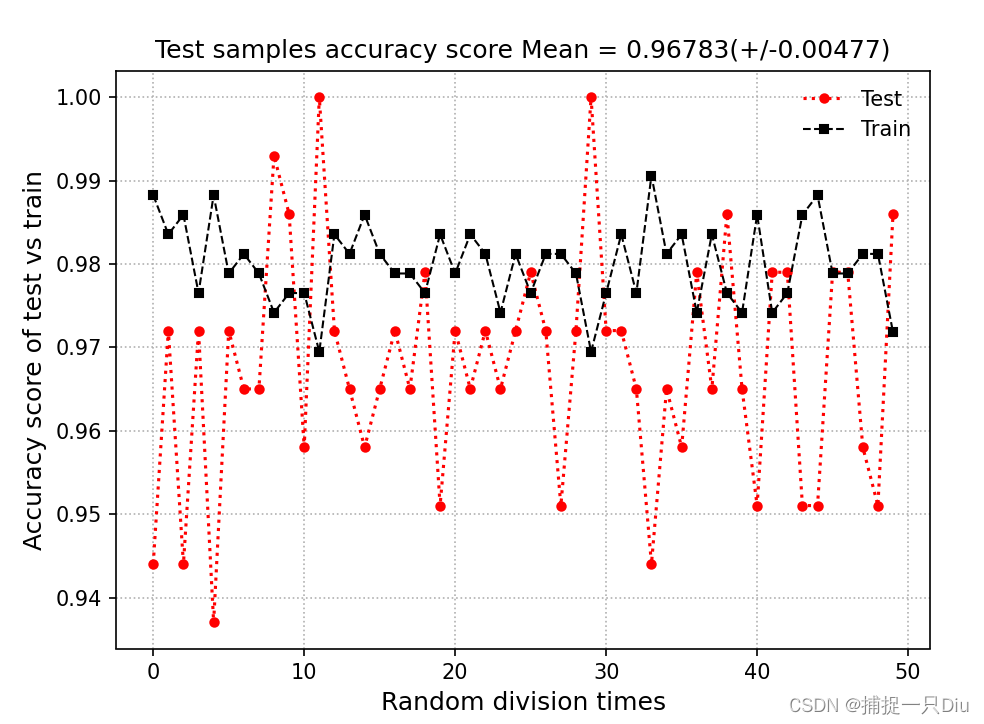
plt.show()acc_test_score, acc_train_score = [], [] # 每次随机划分训练和测试评分
for i in range(50):X_train, X_test, y_train, y_test = train_test_split(X_pca, y, test_size=0.25, random_state=i, shuffle=True, stratify=y)log_reg = LogisticRegression()log_reg.fit(X_train, y_train) # 采用训练集训练模型y_test_pred = log_reg.predict(X_test) # 模型训练完毕后,对测试样本进行预测acc_test_score.append(accuracy_score(y_test, y_test_pred))acc_train_score.append(accuracy_score(y_train, log_reg.predict(X_train)))plt.figure(figsize=(7, 5))
plt.plot(acc_test_score, "ro:", lw=1.5, markersize=4, label="Test")
plt.plot(acc_train_score, "ks--", lw=1, markersize=4, label="Train")
plt.legend(frameon=False)
plt.grid(ls=":")
plt.xlabel("Random division times", fontsize=12)
plt.ylabel("Accuracy score of test vs train", fontsize=12)
plt.title("Test samples accuracy score Mean = %.5f(+/-%.5f)" % (np.mean(acc_test_score), np.std(acc_train_score)), fontsize=12)
plt.show()

这篇关于机器学习:holdout法(Python)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





