本文主要是介绍Kafka-消费者-KafkaConsumer分析-SubscriptionState,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
KafkaConsumer从Kafka拉取消息时发送的请求是FetchRequest(具体格式后面介绍),在其中需要指定消费者希望拉取的起始消息的offset。
为了消费者快速获取这个值,KafkaConsumer使用SubscriptionState来追踪TopicPartition与offset对应关系。
图展示了SubscriptionState依赖的类以及其核心字段。
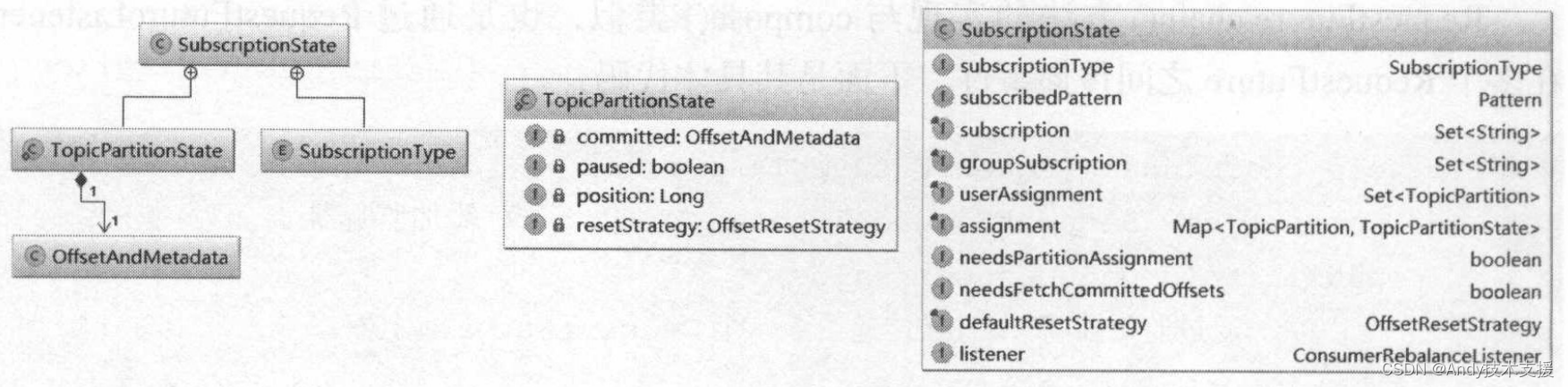
SubscriptionType是SubscriptionState的一个内部枚举类型,表示的是订阅Topic的模式,分为四类。
- NONE:SubscriptionState.subscriptionType的初始值。
- AUTO_TOPICS:按照指定的Topic名字进行订阅,自动分配分区。
- AUTO_PATTERN:按照指定的正则表达式匹配Topic进行订阅,自动分配分区。
- USER_ASSIGNED:用户手动指定消费者消费的Topic以及分区编号。
TopicPartitionState表示的是TopicPartition的消费状态,其关键字段如下所示。
- position:记录了下次要从Kafka服务端获取的消息的offset。
- committed:记录了最近一次提交的offset。
- paused:记录了当前TopicPartition是否处于暂停状态,与Consumer接口的pause方法相关。
- resetStrategy:OffsetResetStrategy枚举类型,重置position的策略。同时,此字段是否为空,也表示了是否需要重置position的值。
TopicPartitionState提供了管理上面四个字段方法,比较简单,不再赘述。
在前面介绍Consumer接口时提到过,subscribe()方法和assign()方法是互斥的。其实上面介绍的三种模式都是互斥的。下面是setSubscriptionType()方法的代码,无论选择哪种模式都会调用此方法进行设置,如图3-10所示。


下面介绍SubscriptionState的核心字段。
- subscriptionType:SubscriptionType枚举类型,表示订阅的模式。
- subscribedPattern:使用AUTO_PATTERN模式时,是按照此字段记录的正则表达式对所有Topic进行匹配,对匹配符合的Topic进行订阅。
- subscription:如果使用AUTO_TOPICS或AUTO_PATTERN模式,则使用此集合记录所有订阅的Topic。向subscription集合中添加数据的方法只有changeSubscription方法,而调用changeSubscription()方法有两处,如图所示。

在图中的①处,使用的是AUTO_TOPICS模式订阅;
图中的②处使用AUTOPATTERN模式订阅。
我们在前面介绍Metadata的时候提到过,可以在其上添加Listener,当Metadata更新时会触发Metadata.Listener.onMetadataUpdate()方法,图中的②处就是在Metadata的Listener中通过subscribedPattern模式过滤Topic,并调用changeSubscription()方法修改subscription集合。
- userAssignment:如果使用USER_ASSIGNED模式,则此集合记录了分配给当前消费者的TopicPartition集合。SubscriptionType模式是互斥的,所以userAssignment集合与subscription集合也是互斥的。
- assignment:Map<TopicPartition,TopicPartitionState>类型,无论使用什么订阅模式,都使用此集合记录每个TopicPartition的消费状态。
- groupSubscription:在前面描述的协议中,Consumer Group中会选举一个Leader,Leader使用该集合记录Consumer Group中所有消费者订阅的Topic,而其他Follower的该集合中只保存了其自身的订阅的Topic。

图中的①处是将消费者自身订阅的Topic添加到groupSubscribe集合;
②处是在Leader收到JoinGroupResponse时调用,在JoinGroupResponse中包含了全部消费者订阅的Topic,在此时将Topic信息添加到groupSubscribe集合。
③处则是将groupSubscribe中其他消费者订阅的Topic删除,只留下自身订阅的Topic(即subscription集合),这是groupSubscription集合收缩的场景。
- needsPartitionAssignment:标记是否需要进行一次分区分配。这里简单了解一下修改needPartitionAssignment的场景和含义,如图所示。

图中的①、⑤处将needsPartitionAssignment设置为true是因为消费者订阅的Topic发生了变化,所以需要进行分区分配;
③处将needsParitionAssignment设置为false是因为使用USER_ASSIGNED订阅模式,所以不需要分区分配操作;
④处是成功得到SyncGroupResponse中的分区分配结果时的操作,此时Rebalance操作结束,将needsPartitionAssignment设置为false;
②处的场景比较复杂,调用②处将needRessignment设置为true,主要是因为在某些请求响应中出现了ILLEGAL_GENERATION等异常,或是订阅的Topic出现了分区数量的变化,调用关系如图所示。

- needsFetchCommittedOffsets:标记是否需要从GroupCoordinator获取最近提交的offset。当出现异步提交offset操作或是Rebalance操作刚完成时会将其置为true,成功获取最近提交offset之后会设置为fasle。
- defaultResetStrategy:默认OffsetResetStrategy策略。
- listener:ConsumerRebalanceListener类型,用于监听分区分配操作。
SubscriptionState中的方法主要是管理上面的几个集合字段,操作比较简单,不再详细介绍。下面简单分析前面示例中使用的subscribe()方法:

这篇关于Kafka-消费者-KafkaConsumer分析-SubscriptionState的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







