本文主要是介绍ClickHouse学习笔记(六):ClickHouse物化视图使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1、ClickHouse 物化视图
- 2、物化视图 vs 普通视图
- 3、物化视图的优缺点
- 4、物化视图的用法
- 4.1、基本语法
- 4.2、准备表结构
- 4.3、准备数据
- 4.3、查询结果
1、ClickHouse 物化视图
ClickHouse 的物化视图是一种查询结果的持久化,它的存在是为了带来查询效率的提升。用户使用物化视图时跟普通的表没有太大区别,其实它就是一张逻辑表,也像是一张时刻在预计算的表,创建的过程它是用了一个特殊引擎,加上后来 as select,就是 create 一个 table as select 的写法。
2、物化视图 vs 普通视图
普通视图:普通视图不保存数据,保存的仅是查询语句,查询的时候还是从原表读取数据,可以将普通视图理解为是个子查询。
物化视图:物化视图是把查询的结果根据相应的引擎存入到了磁盘或内存中,对数据重新进行了组织,你可以理解物化视图是完全的一张新表。
3、物化视图的优缺点
- 优点
- 查询速度快,要是把物化视图这些规则全部写好,它比原数据查询快了很多,总的行数少了,因为都预计算好了。
- 缺点
- 本质是一个流式数据的使用场景,是累加式的技术,所以要用历史数据做去重、去核这样的分析,在物化视图里面是不太好用的;
- 如果一张表加了好多物化视图,在写这张表的时候,就会消耗很多机器的资源,比如数据带宽占满、存储一下子增加了很多;
- 使用场景受限,并不适用于所有的场景;
4、物化视图的用法
4.1、基本语法
CREATE [MATERIALIZED] VIEW [IF NOT EXISTS] [db.]table_name [TO[db.]name]
[ENGINE = engine] [POPULATE] AS SELECT ...
使用create 创建一个物化视图,会创建一个隐藏的目标表来保存视图数据,也可以 TO 表名,保存到 一 张显式的表。没有加 TO 表名,表名默认就是 .inner.物化视图名;
4.2、准备表结构
-
创建 pm 性能数据表
性能表以 start_time 和 ne_name 为组合主键,day_id 为分区,ReplacingMergeTree 为合并引擎
CREATE TABLE default.test_01_pm ( `insert_time` DateTime COMMENT '插入时间', `start_time` String COMMENT '数据时间', `ne_name` String COMMENT '网元名称', `pm_01` String COMMENT 'pm_01', `pm_02` String COMMENT 'pm_02', `day_id` String COMMENT '天分区' ) ENGINE = ReplacingMergeTree() PARTITION BY (day_id) PRIMARY KEY (start_time,ne_name) ORDER BY (start_time,ne_name) -
创建 cm 配置数据表
同上,但是 cm 配置数据主键是 ne_nameCREATE TABLE default.test_01_cm ( `insert_time` DateTime COMMENT '插入时间', `ne_name` String COMMENT '网元名称', `cm_01` String COMMENT 'cm_01', `cm_02` String COMMENT 'cm_02', `day_id` String COMMENT '天分区' ) ENGINE = ReplacingMergeTree() PARTITION BY (day_id) PRIMARY KEY ne_name ORDER BY ne_name;
4.3、准备数据
- pm 性能数据
-- pm 性能数据
INSERT INTO table default.test_01_pm values(now(),'20240117080000','NE_01','100','200','2024-01-17');
INSERT INTO table default.test_01_pm values(now(),'20240117080000','NE_02','100','200','2024-01-17');
INSERT INTO table default.test_01_pm values(now(),'20240117080000','NE_03','100','200','2024-01-17');
INSERT INTO table default.test_01_pm values(now(),'20240117080000','NE_04','100','200','2024-01-17');
-- 模拟重复数据
INSERT INTO table default.test_01_pm values(now(),'20240117080000','NE_01','200','300','2024-01-17');
INSERT INTO table default.test_01_pm values(now(),'20240117080000','NE_01','500','600','2024-01-17');
- cm 配置数据
-- cm 配置数据
INSERT INTO table default.test_01_cm values(now(),'NE_01','10','20','2024-01-17');
INSERT INTO table default.test_01_cm values(now(),'NE_02','10','20','2024-01-17');
INSERT INTO table default.test_01_cm values(now(),'NE_03','10','20','2024-01-17');
INSERT INTO table default.test_01_cm values(now(),'NE_04','10','20','2024-01-17');
4.3、查询结果
-
pm 数据查询
select * from default.test_01_pm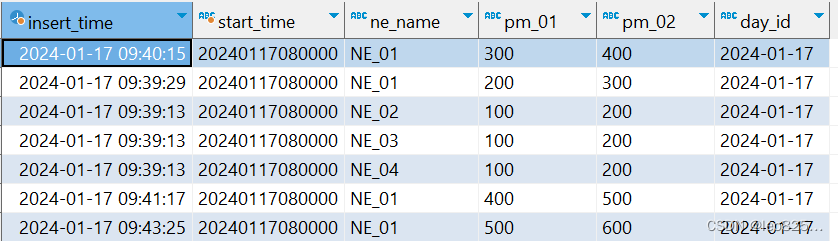
-
cm 数据查询
select * from default.test_01_cm
-
创建物化视图将两个表关联起来
通过 ne_name 将 cm 配置表中的数据关联到 pm性能表中,达到扩充表字段目的create materialized view test_mv engine ReplacingMergeTree() partition by (day_id) primary key(start_time,ne_name) order by (start_time,ne_name)populate as selecta.insert_time,a.start_time,a.ne_name,a.pm_01,a.pm_02,b.cm_01,b.cm_02,a.day_id from`default`.test_01_pm a left join test_01_cm b on a.ne_name = b.ne_name -
物化视图数据查询
select * from default.test_mv

注意: populate 参数不建议添加,这个参数会导致历史数据的计算,如果不添加此参数则物化视图创建之后,只对新增数据进行物化视图的计算。
这篇关于ClickHouse学习笔记(六):ClickHouse物化视图使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







