本文主要是介绍数据可视化平台的下一站 | 来自国产开源数据可视化 datart「超级铁粉」的馈赠,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
自2021年10月datart 1.0 alpha上线,至上周 beta.4 版发布,datart开发团队始终以匠心持续更新,以至诚优化不停,在与大家共处共进的时光中,满是收获,满是欣喜。
初遇:数据可视化平台的下一站
让我们先回顾一下2017年在github上正式开源的davinci,datart的前身。davinci 致力于支持企业完成“大数据的最后十公里”,可视化报表,数据大屏、支持移动端、支持轻数据处理、支持被整合到其他系统中、支持不同团队协同工作等等,在被成百上千家企业投入生产使用,或二开为其客户提供了产品和服务,取得了巨大成功之后,团队也在规划数据可视化平台的下一站,于是,2021年下半年,datart 应运而生。

团队将原本的产品从设计到内核代码全部进行重塑,以一个全新的认知抽象,承载新的产品使命,因此 datart 是开放化的,可插拔的,并且在数据可视化平台的智能力方面做了很大的升级,用户在使用时明显感受到datart 更灵活易用,以及可塑性更强。
相知:一直保持“心动”的感觉
对很多用户和贡献者来说,datart 的标签不仅仅是“易用”、“敏捷”,还有让人一直保持“心动”的“魔力”。从 davinci 到 datart,一路走来,我们收获了一众支持者和关注者,他们一直在以 datart 的“超级铁粉”的身份,以踊跃、积极提issue、pr的行动,在群里积极提供帮助和指导,原创二开教程为 datart 疯狂打“call”......的方式,在国产开源数据可视化这场“盛会”上“通宵达旦的狂欢”。
狂欢的背后,是彼此间的相识相知。一直保持着“心动”的背后,是团队与用户,都以最大的热情对待数据产品。
不论是 datart 开发团队,还是开源社群里面的所有用户、贡献者,都可以被称作是数据艺术的“超级铁粉”,国产开源数据可视化产品的“艺术家”。写到这里,此刻小编按捺不住颤抖的手,特别激动地要给大家介绍 datart -“数据艺术家”群体中的一位-来自敏捷大数据开源社群的Snail同学,他现任职Lenovo SSG(Advisory Engineer, Data Architecture)。
“其实,社群里有不少用户是从 davinci 开始,就一路跟着团队过来的”,“超级铁粉” Snail同学这样说,“我从第一年就关注并用上davinci了,同时也参与到了贡献当中,不论是 datart 的创新,还是在数据可视化这块引领和代表着强大的先进性,每次新版本发布,我都有一种“心动”和“朝圣”的感觉”。
正因为保持着这种“心动”,同时也本着开源的精神,Snail同学将自己学习使用davinci、datart 的经验,均录制成了视频,从初学者的体验,到数据图表、控制器等等操作都很详尽,视频内容细致、专业,无论是数据可视化的初学者,还是同等程度的使用者、贡献者,都很友好。此外,视频中涉及到的所有资料和软件包,Snail同学也都上传到网盘中了,真的非常nice。
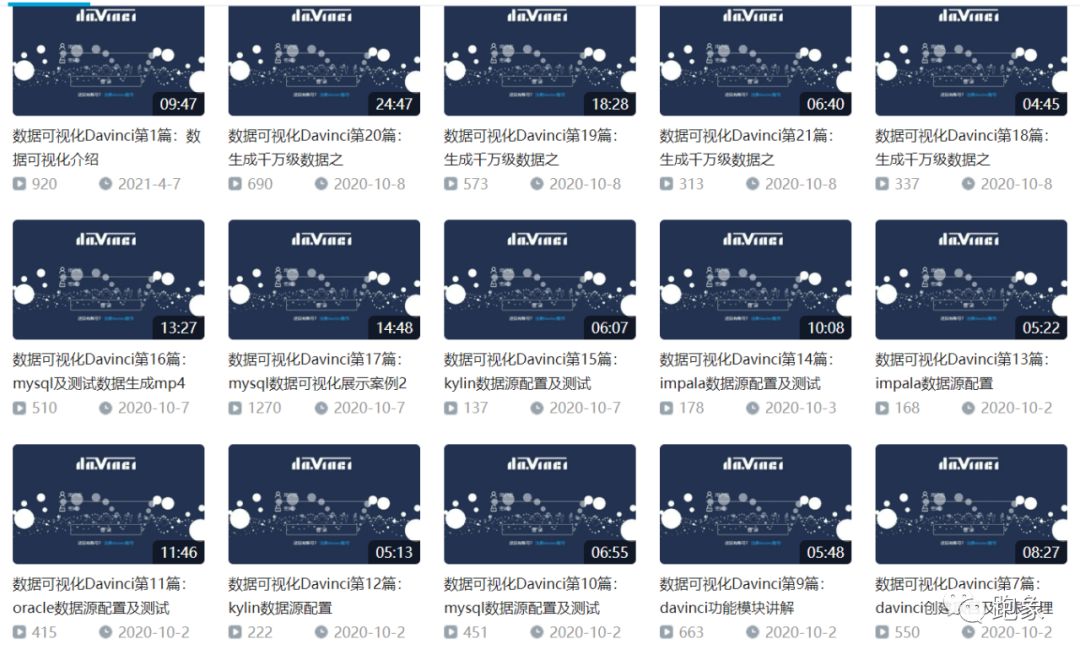
共21期视频-davinci

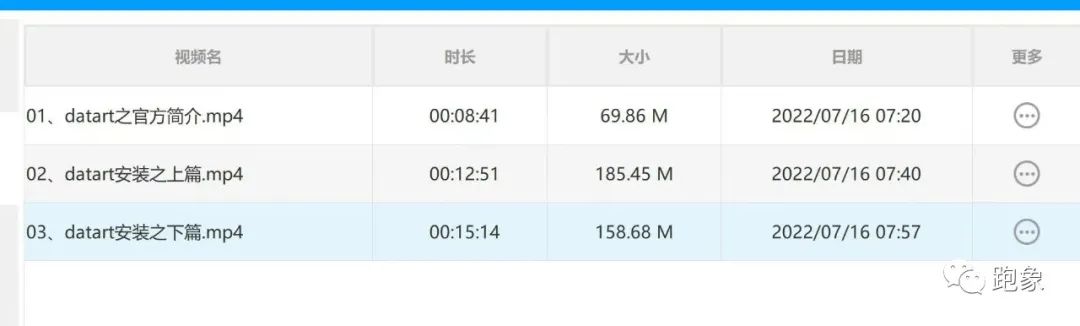
目前更新了15期视频-datart
目前Snail同学录到了15集,后续还会继续更新,大家可以多多关注。在B站中搜索《数据可视化datart》,或通过链接:https://space.bilibili.com/251277098/video ,均可观看。另外,需要学习和使用 datart 开源数据可视化的同学,可以微信搜edpstack,申请加入国产开源数据可视化社群。
接下来 datart 将进入到rc阶段,官方团队表示:“从 davinci 到 datart,马上要迎来了我们国产开源数据可视化的5周年,此前已经完成了beta版的功能完善和细节优化,接下来在rc阶段,我们将会在数据可视化方面,聚合更多的应用并开源出去,相互分享更多的想法,一起产出更多的可视化创意,展现出“数据艺术”的魅力。
蜕变:从不间断的开放与创新
datart 的开放不仅体现在实际应用上可扩展、可插拔,也体现在团队设计和打磨产品的过程中,秉承用户思维,用户体验感至上的方式来进行“蜕变”,也正因为这样,这场“盛会”才吸引了如此之多的用户和贡献者。
“datart的每个功能点都是由用户需求进行驱动的,将用户的意愿转化为切实可用的产品,在这个前提下,将需求进行提炼和创新,构建和重塑出全面的可视化产品”,官方团队提到,例如,在最近发布的datart beta.4版本中,支持、新增、重构和修复了不少功能点,支持了资源迁移功能,仪表版新增了“成组”与“取消成组”功能,重构了图表和仪表板的“交互行为”功能,以及修复了多个异常问题。
在众多开源社群里与用户进行沟通交流,官方团队除了收到了很多积极的反馈,还在产品迭代更新的过程中,与用户一起讨论出需要改进的地方,与此同时,贡献团队的规模也在不断扩大,像Snail同学这样优秀的贡献者也是数不胜数,如白菜、白玉川、天河、小包、nil......,神仙打架,卧虎藏龙,在社群内同官方团队一起辅助图表创新应用、二开、内嵌系统等等,datart 在成长的途中,开放、倾听用户的声音,从不间断创新的脚步,力求给用户带来更好的使用体验。
绽放:datart—数据艺术
重塑、开放、蜕变与不断创新,成就了今天的 datart,在与 “超级铁粉”交流中,明显感觉到:“数据可视化应用不仅改变了数据展现的方式,更加速了数据价值创造的过程”。
在云时代,创新、开放是向前不断发展的“加速剂”,回顾过去这9个月,datart 数据可视化应用的发展与开源社区是密不可分的。谈到 datart 未来的发展,团队负责人徐翔说:“datart 会一直保持自己的特色,保持开源的属性,每次新版的发布,不仅感受到开源社群里热烈交流的气氛,还收获了不少来自海外的忠实用户和贡献者,市场需求的旺盛程度,以及datart 的用户反馈,都远超过了我们的预估。”
未来,如何在维护开源社群用户的基础上,再提供一些商业化、定制化的服务,针对这一问题,团队负责人徐翔表示:“我们有三个维度可以解决:一,通过 datart 本身解决客户数据可视化的本质需求,因为很多时候以为需要一套定制的服务,其实透过表象,深挖内里需求,datart目前已经趋于成熟,客户数据可视化应用方面的需求都能够覆盖到。二,在 datart 上进行二开、或者内嵌企业其他系统,打通系统间应用,以api接口的形式等,都是比较灵活开放的。三,datart 与国内BI工具相比,走的路线完全不一样,打通了低代码,甚至是无代码,完全可以满足客户的定制化开发需求。
目前,据不完全统计,datart 已经有数千家企业用户,链接了各个行业的多端数据参与者,激发了应用开发端和需求端多方互动,正在形成效能明显的庞大数据可视化网络,我们看好敏捷BI行业的升级浪潮,更看好这个由「超级铁粉」和「数据艺术家」共同搭建的数据艺术生态。
这篇关于数据可视化平台的下一站 | 来自国产开源数据可视化 datart「超级铁粉」的馈赠的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





