本文主要是介绍Python爬虫---scrapy框架---当当网管道封装,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目结构:
dang.py文件:自己创建,实现爬虫核心功能的文件
import scrapy
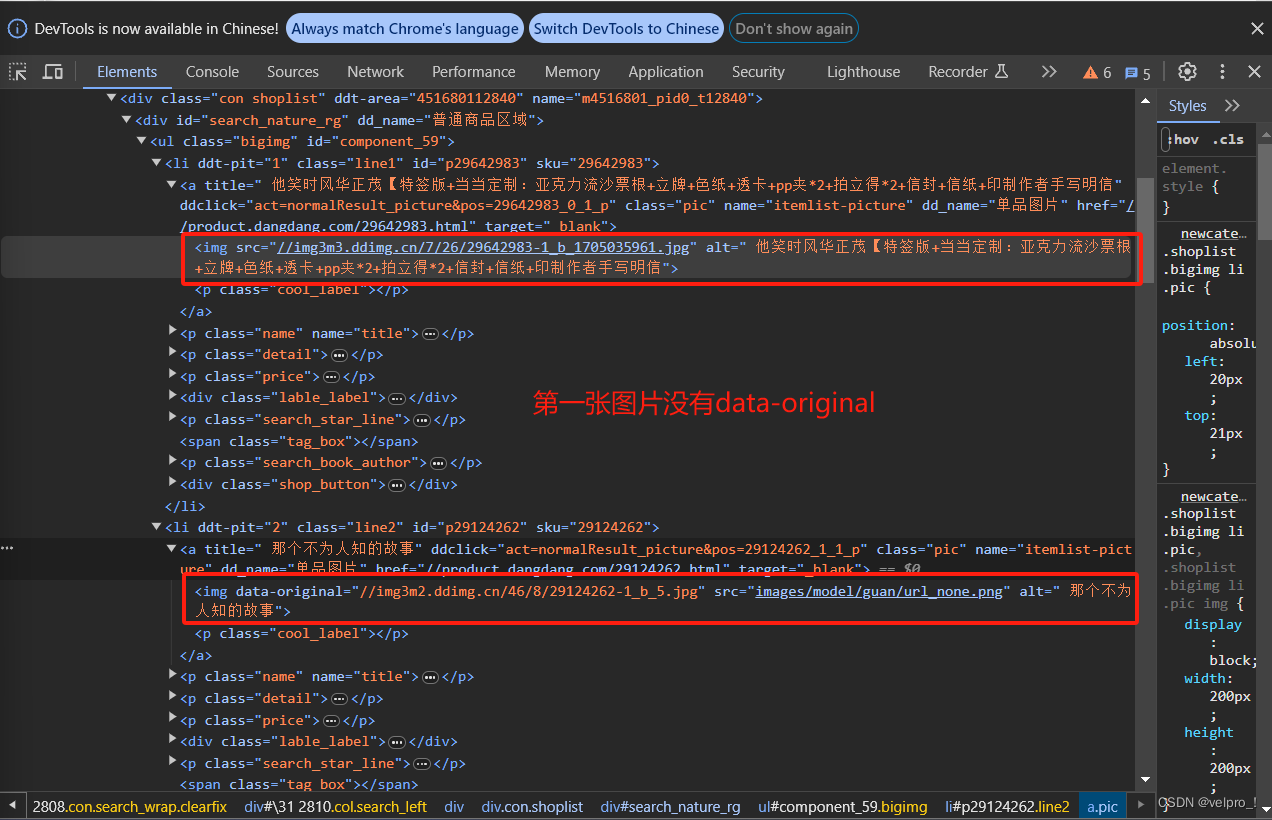
from scrapy_dangdang_20240113.items import ScrapyDangdang20240113Itemclass DangSpider(scrapy.Spider):name = "dang" # 名字# 如果是多页下载的话, 那么必须要调整的是allowed_domains的范围 一般情况下只写城名# allowed_domains = ["https://category.dangdang.com/cp01.01.00.00.00.00.html"]allowed_domains = ["category.dangdang.com"]start_urls = ["https://category.dangdang.com/cp01.01.00.00.00.00.html"]# 第1页:"https://category.dangdang.com/cp01.01.00.00.00.00.html"# 第2页: "https://category.dangdang.com/pg2-cp01.01.00.00.00.00.html"# 第3页: "https://category.dangdang.com/pg3-cp01.01.00.00.00.00.html"base_url = "https://category.dangdang.com/pg"page = 1def parse(self, response):print("========================================================================")# pipelines: 下载数据# items: 定义数据结构# xpath语法# src = //ul[@id='component_59']/li/a/img/@src# 除了第一张,其他做了懒加载 所以不能使用src,要使用这个data-original# src = //ul[@id='component_59']/li/a/img/@data-original# alt = //ul[@id='component_59']/li/a/img/@alt# price = //ul[@id='component_59']/li/p[@class='price']/span[1]/text()# 所有的seletor的对象都可以再次调用xpath语法li_list = response.xpath("//ul[@id='component_59']/li")for li in li_list:src = li.xpath(".//img/@data-original").extract_first()if src:src = srcelse:src = li.xpath(".//img/@src").extract_first()name = li.xpath(".//img/@alt").extract_first()price = li.xpath(".//p[@class='price']/span[1]/text()").extract_first()print(src, name, price)# 将爬取的数据放在对象里book = ScrapyDangdang20240113Item(src=src, name=name, price=price)# 获取一个book将book交给pipelines,将对象放在管道里yield book# 每一页的爬取业务的逻辑全都是一样的,所以我们只需要将执行的那个页的请求再次调用if self.page < 100:self.page = self.page + 1url = self.base_url + str(self.page) + "-cp01.01.00.00.00.00.html"# 调用parse万法# scrapy.Request就是scrpay的get请求 url就是请求地址# callback是你要执行的那个函数注意不需要加()yield scrapy.Request(url=url, callback=self.parse)items文件:定义数据结构的地方
import scrapyclass ScrapyDangdang20240113Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 通俗的说就是你要下载的数据都有什么src = scrapy.Field()name = scrapy.Field()price = scrapy.Field()settings文件:配置文件,例如开启管道
# 开启管道
ITEM_PIPELINES = {# 管道可以有很多个,那么管道是有优先级的,优先级的范围是1到1000,值越小优先级越高"scrapy_dangdang_20240113.pipelines.ScrapyDangdang20240113Pipeline": 300,"scrapy_dangdang_20240113.pipelines.DangdangDownloadPipeline": 301,
}pipelines.py文件:管道文件,里面只有一个类,用于处理下载数据的,值越小优先级越高
# 下载数据# 如果想使用管道的话 那么就必须在settings中开启管道
class ScrapyDangdang20240113Pipeline:# item就是yield后面的book对象# 方式一:# 以下这种模式不推荐,因为每传递过来一个对象,那么就打开一次文件,对文件的作过于频繁# def process_item(self, item, spider):# (1)write万法必须要写一个字符串,而不能是其他的对象,使用str()强转# (2)w模式 会每一个对象都打开一次文件 覆盖之前的内容# with open("book.json","a",encoding="utf-8")as fp:# fp.write(str(item))# return item# 方式二:# 在爬虫文件开始之前就执行的方法def open_spider(self, spider):print("++++++++++++++++++++++++++++++++++++++++++++++++++")self.fp = open("book.json", "w", encoding="utf-8")def process_item(self, item, spider):self.fp.write(str(item))return item# 在爬虫文件开始之后就执行的方法def close_spider(self, spider):print("----------------------------------------------------")self.fp.close()# 多条管道同时开启
# (1)定义管道类
# (2)在settings中开启管道
import urllib.request
class DangdangDownloadPipeline:def process_item(self, item, spider):# 下载图片url = "https:" + item.get("src")filename = "./books/" + item.get("name")[0:6] + ".jpg"urllib.request.urlretrieve(url=url, filename=filename)return item这篇关于Python爬虫---scrapy框架---当当网管道封装的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





