本文主要是介绍Pandas实战案例 | 冷空气活动寒潮级别分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
大家好,今天介绍如何把基础函数groupby和diff方法通过复杂而清晰逻辑去解决令人头大的需求,优雅~
目录:
- 需求分析
- 读取数据
- 拿一个分组进行测试
- 获取满足寒潮定义条件的对应数据id
- 分组编号生成器
- 测试对所有站计算寒潮
- 测试所有寒潮级别
- 完整代码
需求分析
寒潮的定义:

数据的输入和输出格式:
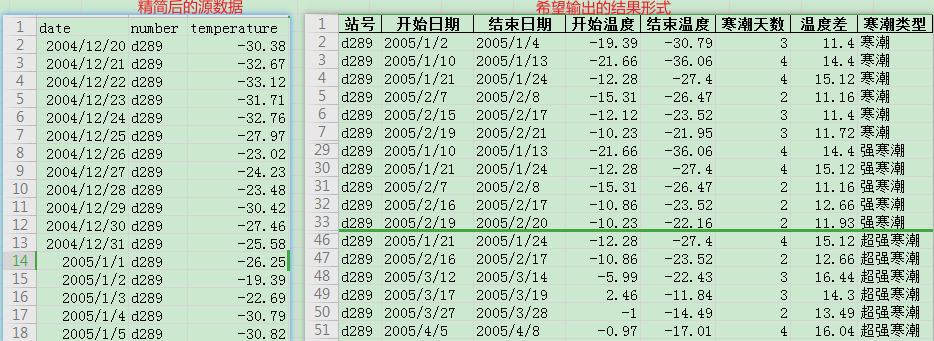
统计口径确认:
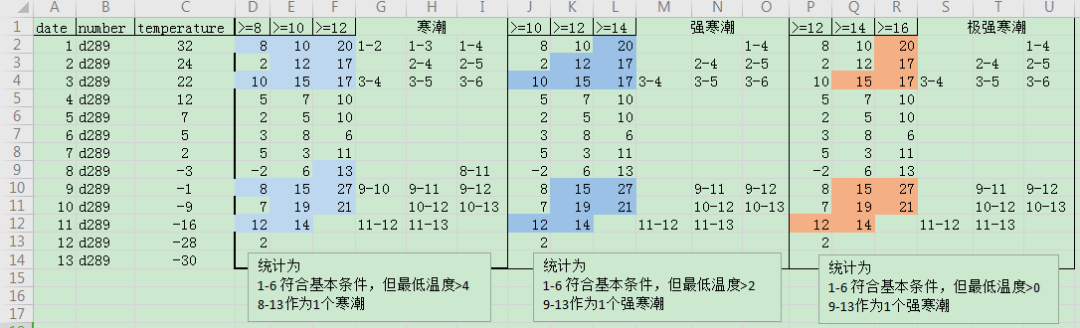
我一开始不理解,24小时内降温幅度大于8度如何计算,与需求方确认后,可以通过2日温度之差来计算。同样48小时内降温幅度可以用3日温度之差来代表,72小时内降温幅度可以用4日温度之差来代表,需求方的解释:

好了,理解清楚了需求,咱们就可以开始干活了:
读取数据
首先读取数据:
import pandas as pd
import numpy as npdf = pd.read_csv("data.csv")
df
结果:
拿一个分组进行测试
取出某个分组,用于测试:
tmp = df.groupby('number').get_group('e332')
tmp
结果:
获取满足寒潮定义条件的对应数据id
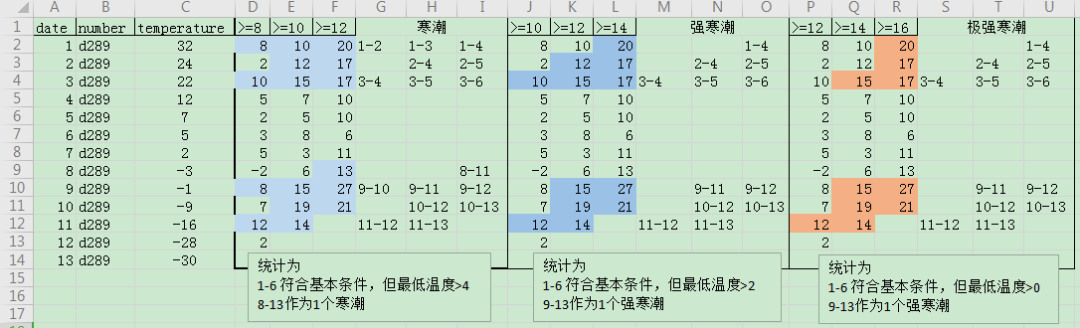
上图的极端情况显示,三大满足条件的id可能出现重复的情况,所以我使用了set这个无序不重复集合来保存id:
cold_wave_idxs = set()
# 获取2天内降温幅度超过8对应的数据id
ids = tmp.index[tmp.temperature.diff(-1) >= 8].values
cold_wave_idxs.update(ids)
cold_wave_idxs.update(ids+1)
# 获取3天内降温幅度超过10对应的数据id
ids = tmp.index[tmp.temperature.diff(-2) >= 10].values
cold_wave_idxs.update(ids)
cold_wave_idxs.update(ids+1)
cold_wave_idxs.update(ids+2)
# 获取4天内降温幅度超过12对应的数据id
ids = tmp.index[tmp.temperature.diff(-3) >= 12].values
cold_wave_idxs.update(ids)
cold_wave_idxs.update(ids+1)
cold_wave_idxs.update(ids+2)
cold_wave_idxs.update(ids+3)
# 排序并转换成列表
cold_wave_idxs = sorted(cold_wave_idxs)
print(cold_wave_idxs)
结果:
[11928, 11929, 11930, 11931, 11939, 11940, 11949, 11950, 11951, 11952, 11955, 11956, 11957, 11958, 12007, 12008, 12154, 12155, 12192, 12193, 12201, 12202, 12203, 12223, 12224, 12225, 12228, 12229, 12230]
上述代码中cold_wave_idxs.update(ids+1)表示,把ids列表里每个id的后一个id也添加到最终列表里,利用了numpy数组广播变量的特性,+2和+3也是同理。
上述结果就是从站码为'e332'的分组中计算出满足寒潮定义的对应数据id。
从结果可以看出,凡是连续的id都可以看作一个寒潮的过程,所以现在我们需要将每个寒潮过程都分为一组,为了作这样的分组,我发明了一种分组编号生成器的写法,下面已经封装成了一个方法:
分组编号生成器
def generate_group_num(values, diff=1):group_ids = []group_id = 0last_v = 0for value in values:if value-last_v > diff:group_id += 1group_ids.append(group_id)last_v = valuereturn group_ids
上面的方法实现了一个分组编号生成器,对于一段序列凡是连续的数字都会给一个相同的分组编号。
测试一下分组效果:
for i, cold_wave_idx_serial in pd.Series(cold_wave_idxs).groupby(generate_group_num(cold_wave_idxs)):cold_wave_idx_serial = cold_wave_idx_serial.valuesprint(cold_wave_idx_serial)
结果:
[11928 11929 11930 11931]
[11939 11940]
[11949 11950 11951 11952]
[11955 11956 11957 11958]
[12007 12008]
[12154 12155]
[12192 12193]
[12201 12202 12203]
[12223 12224 12225]
[12228 12229 12230]
从结果可以看到,凡是连续的序列都分到了一组,不是连续的序列就没有分到一组。
测试对所有站计算寒潮
首先将前面的测试好的用于获取满足寒潮定义的id的过程封装成方法:
def get_cold_wave_idxs(df, cold_wave_level=(8, 10, 12)):cold_wave_idxs = set()ids = df.index[df.temperature.diff(-1) >= cold_wave_level[0]].valuescold_wave_idxs.update(ids)cold_wave_idxs.update(ids+1)ids = df.index[df.temperature.diff(-2) >= cold_wave_level[1]].valuescold_wave_idxs.update(ids)cold_wave_idxs.update(ids+1)cold_wave_idxs.update(ids+2)ids = df.index[df.temperature.diff(-3) >= cold_wave_level[2]].valuescold_wave_idxs.update(ids)cold_wave_idxs.update(ids+1)cold_wave_idxs.update(ids+2)cold_wave_idxs.update(ids+3)return sorted(cold_wave_idxs)
然后运行:
cold_wave_result = []for number, tmp in df.groupby('number'):cold_wave_idxs = get_cold_wave_idxs(tmp, (8, 10, 12))for i, cold_wave_idx_serial in pd.Series(cold_wave_idxs).groupby(generate_group_num(cold_wave_idxs)):cold_wave_idx_serial = cold_wave_idx_serial.valuesstart_id, end_id = cold_wave_idx_serial[0], cold_wave_idx_serial[-1]# 假如最低温度小于4度,则说明满足全部条件if tmp.loc[end_id, 'temperature'] <= 4:cold_wave_result.append((number, tmp.loc[start_id, 'date'], tmp.loc[end_id, 'date'],tmp.loc[start_id, 'temperature'], tmp.loc[end_id, 'temperature'],end_id-start_id+1,tmp.loc[start_id, 'temperature'] -tmp.loc[end_id, 'temperature'],'寒潮'))
cold_wave_result = pd.DataFrame(cold_wave_result, columns=['站号', '开始日期', '结束日期', '开始温度', '结束温度', '寒潮天数', '温度差', '寒潮类型'])
cold_wave_result
结果:
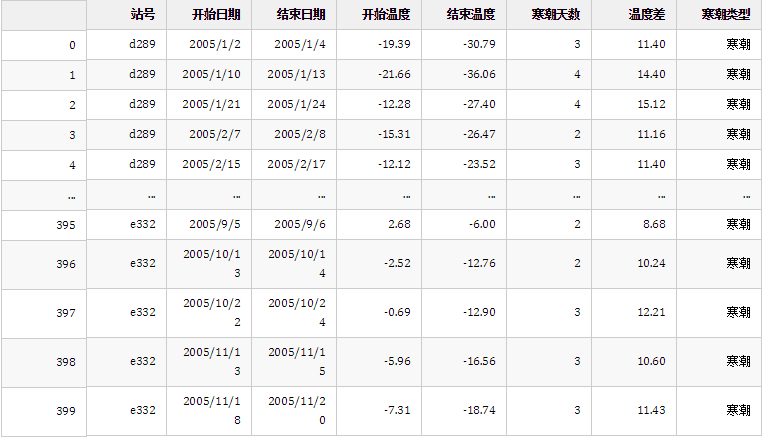
感觉没啥问题。
所有寒潮级别都测试一下:
测试所有寒潮级别
cold_wave_all = [{'cold_wave_temperature_diffs': (8, 10, 12),'min_temperature_limit': 4,'cold_wave_type': '寒潮'},{'cold_wave_temperature_diffs': (10, 12, 14),'min_temperature_limit': 2,'cold_wave_type': '强寒潮'},{'cold_wave_temperature_diffs': (12, 14, 16),'min_temperature_limit': 0,'cold_wave_type': '超强寒潮'}
]
cold_wave_result = []for number, tmp in df.groupby('number'):for cold_wave_dict in cold_wave_all:cold_wave_idxs = get_cold_wave_idxs(tmp, cold_wave_dict['cold_wave_temperature_diffs'])if len(cold_wave_idxs) < 2:continuefor i, cold_wave_idx_serial in pd.Series(cold_wave_idxs).groupby(generate_group_num(cold_wave_idxs)):cold_wave_idx_serial = cold_wave_idx_serial.valuesstart_id, end_id = cold_wave_idx_serial[0], cold_wave_idx_serial[-1]# 假如最低温度小于指定度数,则说明满足全部条件if tmp.loc[end_id, 'temperature'] <= cold_wave_dict['min_temperature_limit']:cold_wave_result.append((number, tmp.loc[start_id, 'date'], tmp.loc[end_id, 'date'],tmp.loc[start_id, 'temperature'], tmp.loc[end_id, 'temperature'],end_id-start_id+1,tmp.loc[start_id, 'temperature'] - tmp.loc[end_id, 'temperature'],cold_wave_dict['cold_wave_type']))
cold_wave_result = pd.DataFrame(cold_wave_result, columns=['站号', '开始日期', '结束日期', '开始温度', '结束温度', '寒潮天数', '温度差', '寒潮类型'])
cold_wave_result
结果:
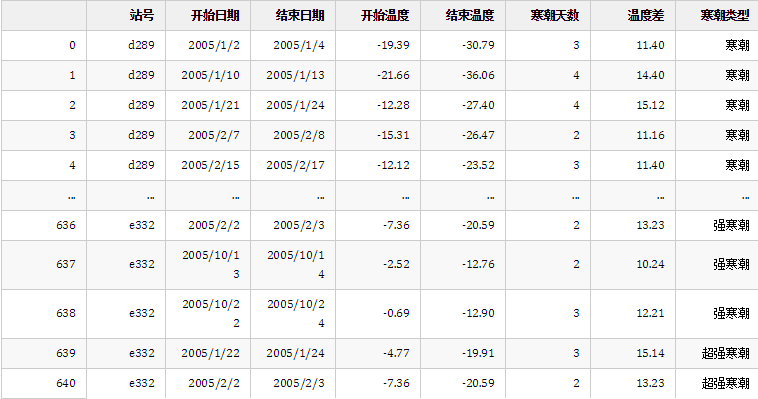
暂时也未发现错误。那么整理一下最终代码吧:
完整代码
import pandas as pd
import numpy as npdef generate_group_num(values, diff=1):group_ids = []group_id = 0last_v = 0for value in values:if value-last_v > diff:group_id += 1group_ids.append(group_id)last_v = valuereturn group_idsdef get_cold_wave_idxs(df, cold_wave_level=(8, 10, 12)):cold_wave_idxs = set()ids = df.index[df.temperature.diff(-1) >= cold_wave_level[0]].valuescold_wave_idxs.update(ids)cold_wave_idxs.update(ids+1)ids = df.index[df.temperature.diff(-2) >= cold_wave_level[1]].valuescold_wave_idxs.update(ids)cold_wave_idxs.update(ids+1)cold_wave_idxs.update(ids+2)ids = df.index[df.temperature.diff(-3) >= cold_wave_level[2]].valuescold_wave_idxs.update(ids)cold_wave_idxs.update(ids+1)cold_wave_idxs.update(ids+2)cold_wave_idxs.update(ids+3)return sorted(cold_wave_idxs)df = pd.read_csv("data.csv")
cold_wave_all = [{'cold_wave_temperature_diffs': (8, 10, 12),'min_temperature_limit': 4,'cold_wave_type': '寒潮'},{'cold_wave_temperature_diffs': (10, 12, 14),'min_temperature_limit': 2,'cold_wave_type': '强寒潮'},{'cold_wave_temperature_diffs': (12, 14, 16),'min_temperature_limit': 0,'cold_wave_type': '超强寒潮'}
]
cold_wave_result = []for number, tmp in df.groupby('number'):for cold_wave_dict in cold_wave_all:cold_wave_idxs = get_cold_wave_idxs(tmp, cold_wave_dict['cold_wave_temperature_diffs'])if len(cold_wave_idxs) < 2:continuefor i, cold_wave_idx_serial in pd.Series(cold_wave_idxs).groupby(generate_group_num(cold_wave_idxs)):cold_wave_idx_serial = cold_wave_idx_serial.valuesstart_id, end_id = cold_wave_idx_serial[0], cold_wave_idx_serial[-1]# 假如最低温度小于指定度数,则说明满足全部条件if tmp.loc[end_id, 'temperature'] <= cold_wave_dict['min_temperature_limit']:cold_wave_result.append((number, tmp.loc[start_id, 'date'], tmp.loc[end_id, 'date'],tmp.loc[start_id, 'temperature'], tmp.loc[end_id, 'temperature'],end_id-start_id+1,tmp.loc[start_id, 'temperature'] - tmp.loc[end_id, 'temperature'],cold_wave_dict['cold_wave_type']))
cold_wave_result = pd.DataFrame(cold_wave_result, columns=['站号', '开始日期', '结束日期', '开始温度', '结束温度', '寒潮天数', '温度差', '寒潮类型'])
cold_wave_result.to_excel("cold_wave.xlsx", index=False)
最终得到的结果:
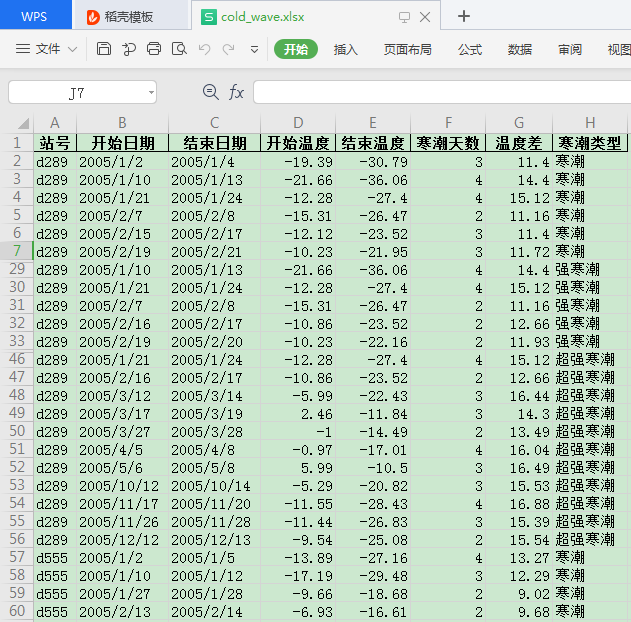
这篇关于Pandas实战案例 | 冷空气活动寒潮级别分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





