本文主要是介绍WRF土地利用数据替换,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
WRF更换土地利用数据
文章目录
- WRF更换土地利用数据
- 前言
- 一、数据下载
- 二、GRID转tiff
- 三、重投影
- 四、重分类
- 五、tiff格式转二进制
- 六、修改GEOGRID.TBL
- 七、修改namelist.wps
- 八、运行geogrid.exe
前言
近期利用WRF进行辐照度模拟,苦于精度提升慢,所以想利用中国土地利用数据(1980-2015)的土地利用数据替换wrf内老旧的土地利用数据,以提高WRF模拟精度。一做记录、二做共享。如有不妥,欢迎大家批评指正!
一、数据下载
打开中国土地利用数据(1980-2015),点下载按钮即可下载1980-2015年土地利用数据。

二、GRID转tiff
下载的lucc2015数据如下图所示

这种格式的数据我不知道怎么用python读取,但是在ArcGIS中可以打开。通过属性表可以看到,坐标为投影坐标系Krasovsky_1940_Albers,数据格式为GRID。为了方便后续操作我们先将数据格式另存为tiff:
右击数据–>Data–>Export Data将数据另存为tiff格式。
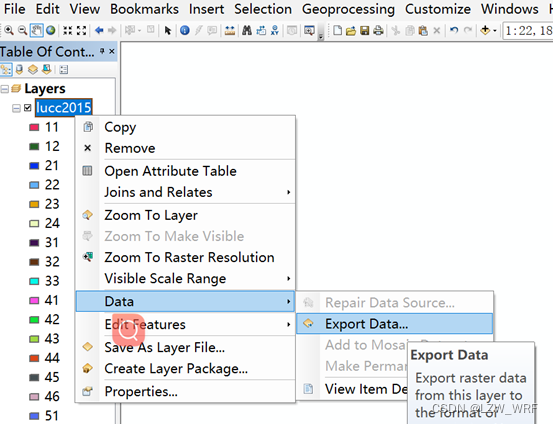

三、重投影
这一步的目的是将数据的投影坐标系Krasovsky_1940_Albers转为地理坐标系WGS84。
打开ArcToolbox–>Projections and Transformations–>Raster–>Project Raster。选中我们刚刚另存的lucc2015栅格数据,并将坐标系统重新定义为地理坐标系WGS 84。转换成功后在属性表中可以看到坐标系统变为WGS 84。

四、重分类
目前WRF只能输入USGS-24分类、IGBP-20分类或IGBP-21分类体系,因此需要对土地利用数据进行重新分类,分类原则参考GISer凌,如下图所示:

重分类python代码如下:
import os
from osgeo import gdal
import numpy as np
def read_tif(tifFile):tif = gdal.Open(tifFile)XSize = tif.RasterXSize # 影像列数YSize = tif.RasterYSizeprojection = tif.GetProjection() # 投影信息geotransform = tif.GetGeoTransform() # 仿射矩阵bandnum=tif.RasterCountdata = tif.GetRasterBand(1)nodata = data.GetNoDataValue()tifdata = data.ReadAsArray(0, 0, XSize, YSize).astype(float)return XSize,YSize,projection,geotransform,bandnum,nodata,tifdata
def reclass(data):# data = np.where(data == nodata, np.nan, data) # 仿射矩阵data = np.where((data == 51) | (data == 53) | (data == 54), 1, data)data = np.where((data == 11) | (data == 12) | (data == 52), 3, data)data = np.where((data == 31) | (data == 32) | (data == 33) | (data == 34), 7, data)data = np.where((data == 23) | (data == 22), 8, data)data = np.where((data == 24) | (data == 25), 9, data)data = np.where((data == 21), 14, data)data = np.where((data == 41) | (data == 42) | (data == 43) | (data == 46) | (data == 99), 16, data)data = np.where((data == 45) | (data == 64), 17, data)data = np.where((data == 61) | (data == 62) | (data == 63) | (data == 65) | (data == 67), 19, data)data = np.where((data == 66), 23, data)data = np.where((data == 44), 24, data)return data
# 输出tif
def creattif(DriverName, out_np, XSize, YSize, Bandnum, datatype, geotransform, projection, nodata, data):driver = gdal.GetDriverByName(DriverName)# dst_ds = driver.Create( dst_filename, 512, 512, 1, gdal.GDT_Byte )这句就创建了一个图像。宽度是512*512,单波段,数据类型是Byte这里要注意,它少了源数据,因为这里用不到源数据。它创建了一个空的数据集。要使它有东西,需要用其他步骤往里头塞东西。new_dataset = driver.Create(out_np, XSize, YSize, Bandnum, datatype) # band[str(i)]new_dataset.SetGeoTransform(geotransform) # 写入仿射变换参数new_dataset.SetProjection(projection)band_out = new_dataset.GetRasterBand(1)# if nodata is None or nodata is np.nan:# nodata = -9999band_out.WriteArray(data) # 写入数组数据band_out.SetNoDataValue(nodata)if DriverName == "GTiff":band_out.ComputeStatistics(True)del new_dataset
def main(intifFile,outpath,outname):XSize,YSize,projection,geotransform,bandnum,nodata,tifdata=read_tif(intifFile)newdata=reclass(tifdata)datatype=gdal.GDT_Int32DriverName = "GTiff"outpn=os.path.join(outpath, outname)creattif(DriverName, outpn, XSize, YSize, bandnum, datatype, geotransform, projection, nodata, newdata)
if '__main__' in __name__:intifFile = r'E:\lucc2015\lucc2015_wgs84.tif' #输入tif数据outpath=r'E:\lucc2015' #输出路径outname='lucc2015_wgs84_reclass.tif'main(intifFile,outpath,outname)
五、tiff格式转二进制
将我们分类好的lucc2015栅格数据转为二进制格式才能在WRF中使用,将分类好的lucc2015拷贝到Ubuntu中的WPS_GEOG文件夹下的lucc2015文件夹下,如下图所示。

使用命令:gdal_translate -of ENVI -co INTERLEAVE=BSQ lucc2015_wgs84_reclass.tif data.bil将tif文件转为二进制文件。其中lucc2015_wgs84_reclass.tif为需要转换的文件,data.bil为转换的目标文件。(需要安装GDAL,如果没有安装,按报错提示安装即可sudo apt install gdal-bin)
。

运行成功后会在文件夹下生成data.bil、data.bil.aux.xml和data.hdr三个文件:

查看data.hdr头文件提供的一些基本信息,其中samples为数据的列数,lines为数据的行数,map info中的0.0117836266203959,0.0117836266203959分别为数据的横向和纵向网格分辨率。
ENVI
description = {
data.bil}
samples = 6157
lines = 3393
bands = 1
header offset = 0
file type = ENVI Standard
data type = 3
interleave = bsq
byte order = 0
map info = {Geographic Lat/Lon, 1, 1, 66.2922997247769, 54.9785484716575, 0.0117836266203959, 0.0117836266203959,WGS-84}
coordinate system string = {GEOGCS["GCS_WGS_1984",DATUM["D_WGS_1984",SPHEROID["WGS_1984",6378137.0,298.257223563]],PRIMEM["Greenwich",0.0],UNIT["Degree",0.0174532925199433]]}
band names = {
Band 1}
在lucc2015中新建index文件。根据data.hdr头文件和数据内容,对index文件进行如下设置:
type=categorical
category_min=1
category_max=24
projection=regular_ll
dx=0.0117836266203959
dy=0.0117836266203959
known_x=1.0
known_y=1.0
known_lat=14.9967033487
known_lon=66.2922997248
wordsize=1
tile_x=6157
tile_y=3393
tile_z=1
units="category"
description="USGS 24-category land use categories"
mminlu="USGS"
missing_value=128
iswater=16
islake=-1
isice=24
isurban=1
row_order=top_bottom
注意:
type:为文件描述类型
category_min:分类代码的最小值
category_max:分类代码的最大值
projection:投影类型
dx:横向格点间的间隔,即栅格影像的横向分辨率 #与data.hdr文件中横向网格分辨率保持一致
dy:纵向格点间的间隔,即栅格影像的纵向分辨率 #与data.hdr文件中纵向网格分辨率保持一致
known_x:指定一个标记点横向坐标
known_y:指定一个标记点纵向坐标
known_lat:标记点横向坐标的纬度 #tiff文件左下角的纬度,在ArcGIS中打开数据的属性查看
known_lon:标记点纵向坐标的经度 #tiff文件左下角的经度,在ArcGIS中打开数据的属性查看
tile_x:横向格点数 #参考ArcGIS中的列数
tile_y:纵向格点数 #参考ArcGIS中的行数
units:格点值的单位
description:文件描述
iswater:水体类别的编号 #查看自己重分类后的水体类别编号
islake:湖泊类别的编号 #查看自己重分类后的湖泊类别编号
isice:冰川类别的编号 #查看自己重分类后的冰川类别编号
isurban:城市类别的编号 #查看自己重分类后的城市类别编号
missing_value:缺省值是128。
在编辑完index文件后,将data.bil重命名为00001-06157.00001-03393,其中6157为lucc2015的列数,3393为lucc2015的行数,这样tiff转换二进制就成功了。如下图:

六、修改GEOGRID.TBL
在WPS安装目录中的geogrid文件夹下,找到GEOGRID.TBL文件,打开后找到name=LANDUSEF项,分别在每一项的后面面加上
landmask_water = lucc2015 # Calculate a landmask from this field
interp_option = lucc2015:nearest_neighbor
rel_path = lucc2015:lucc2015/
然后保存即可。如下图:

七、修改namelist.wps
土地利用数据制作完成之后,需要在namelist.wps中设置geog_data_res=‘usgs_30s+default’,‘lucc2015+default’,‘lucc2015+default’,我的namelist.wps设置如下所示:

注:
(1) 如果您希望使用 USGS 静态地面数据,而不是默认的 MODIS数据,则需要将geog_data_res指定为:
geog_data_res = ‘usgs_30s+default’, ‘usgs_30s+default’,、
(2) 在 V3.8 之前,USGS 是默认的。如果您使用的是 V3.8 之前的 WPS 版本,并且希望使用默认的 USGS 数据,则只需指定:
geog_data_res = ‘10m’, ‘2m’, ‘30s’
(3) 在 V3.8 之前,如果您希望使用 MODIS数据,则需要指定:
geog_data_res = ‘modis_30s+10m’, ‘modis_30s+2m’, ‘modis_30s+30s’
(4) 可用分辨率为 10 m(~19 公里)、5m(~9 公里)、2 m(~4 公里)和 30 s(~0.9 公里)。
八、运行geogrid.exe
运行完后,在WPS中生成以下三个文件(因为我是三层嵌套)。

后面就可以用新的土地利用数据去做测试啦!
这篇关于WRF土地利用数据替换的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





