本文主要是介绍[学习笔记]刘知远团队大模型技术与交叉应用L2-Neural Network Basics,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本节首先介绍神经网络的一些基本构成部分。然后简要介绍神经网络的训练方式。介绍一种基于神经网络的形成词汇的向量表示的方法。接下来继续介绍常见的神经网络结构:RNN和CNN。最后使用PyTorch演示一个NLP任务的一个完整训练的Pipeline。
神经网络的基本组成
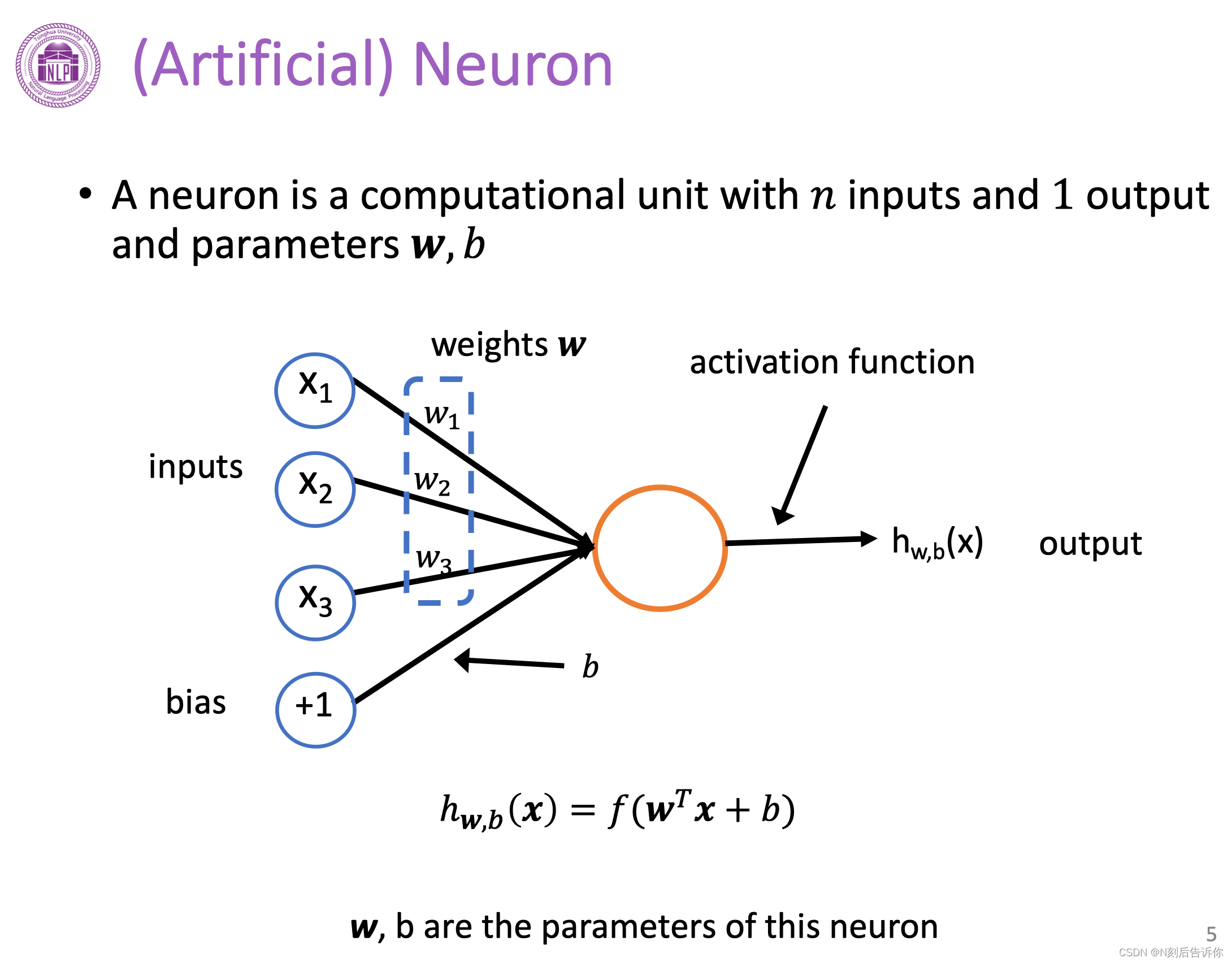
单个神经元
(人工)神经元接受n个输入,1个输出。由参数w、b以及激活函数f来构成。
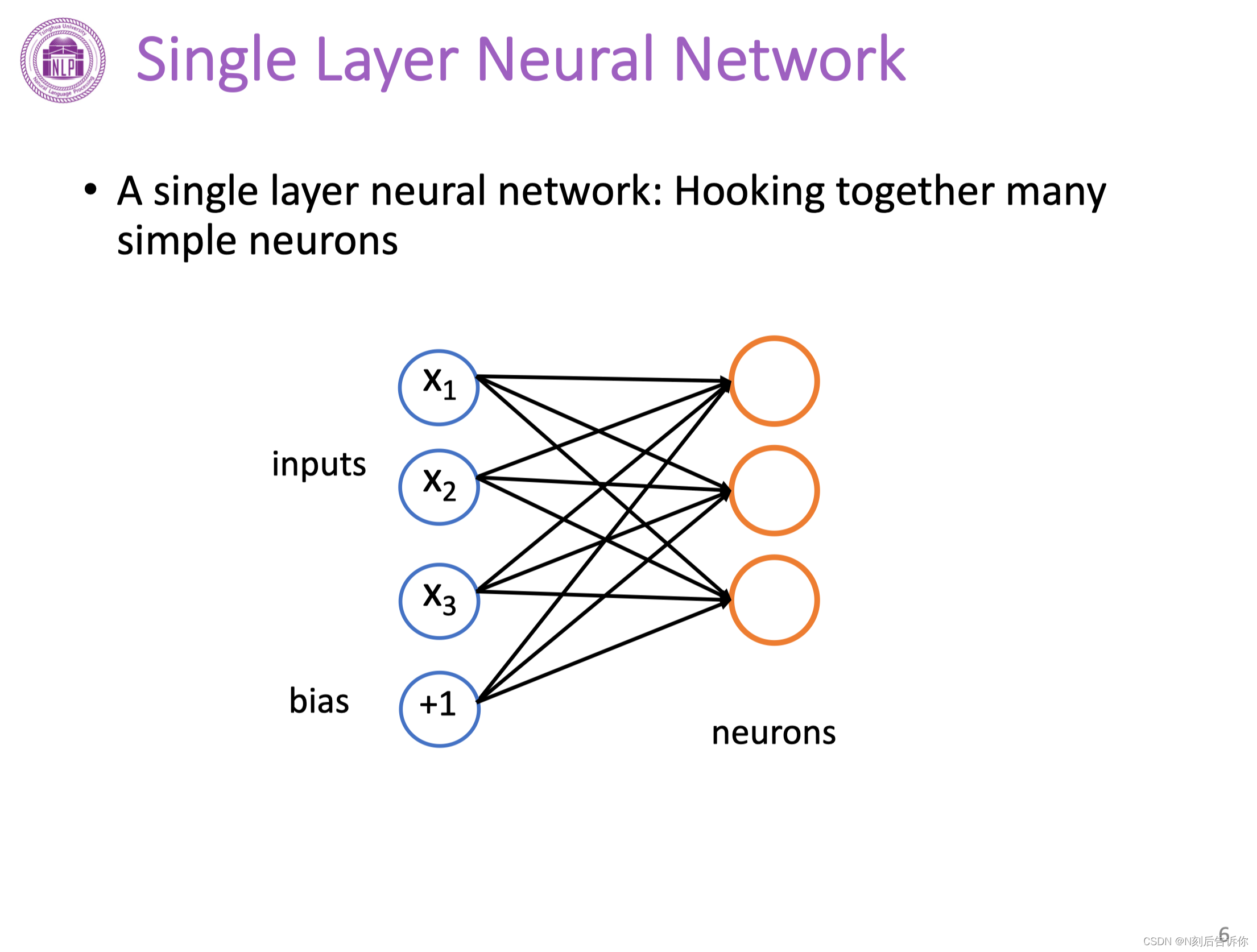
单层神经网络
多个单个神经元组成单层神经网络。
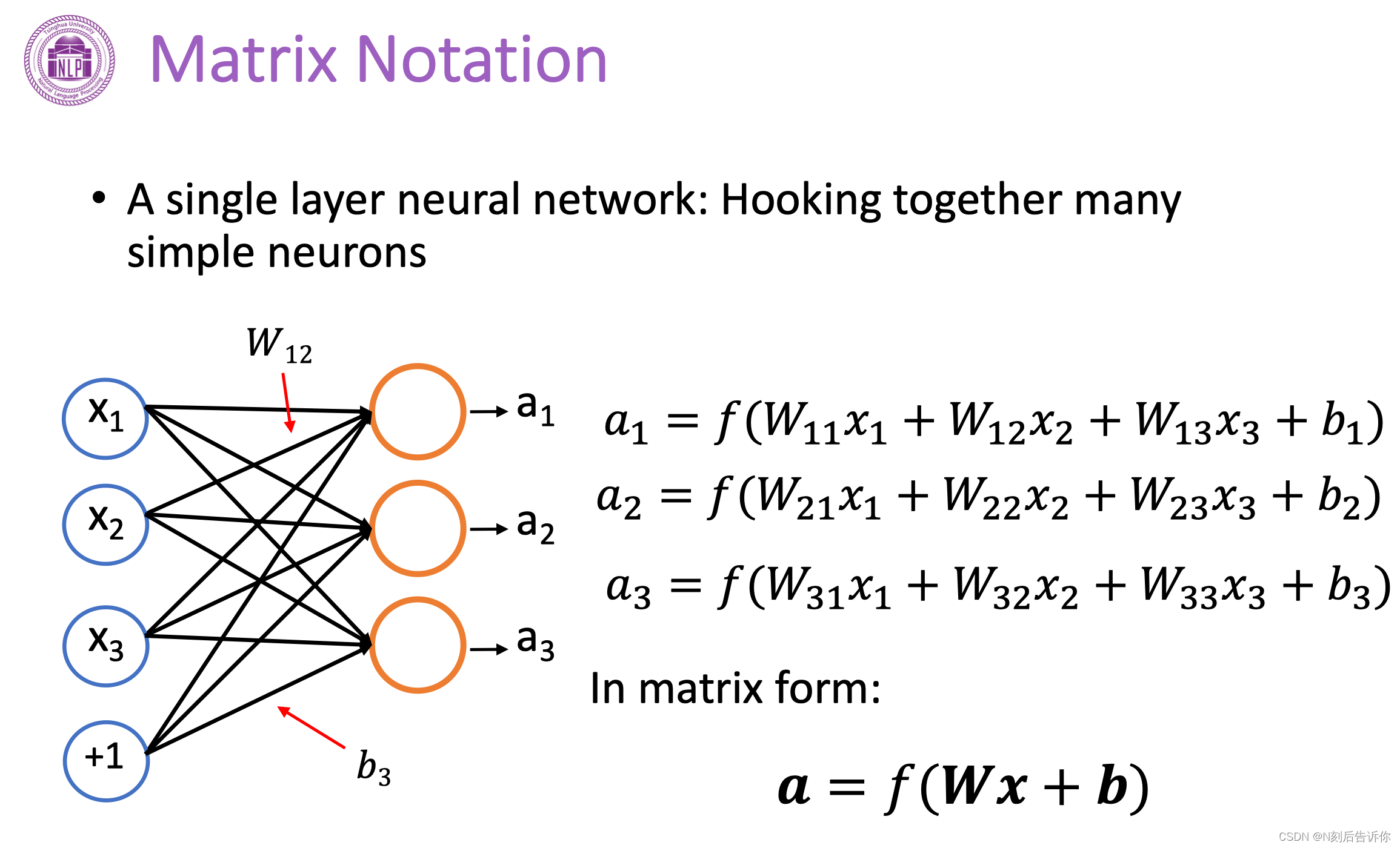
矩阵表示
多层神经网络
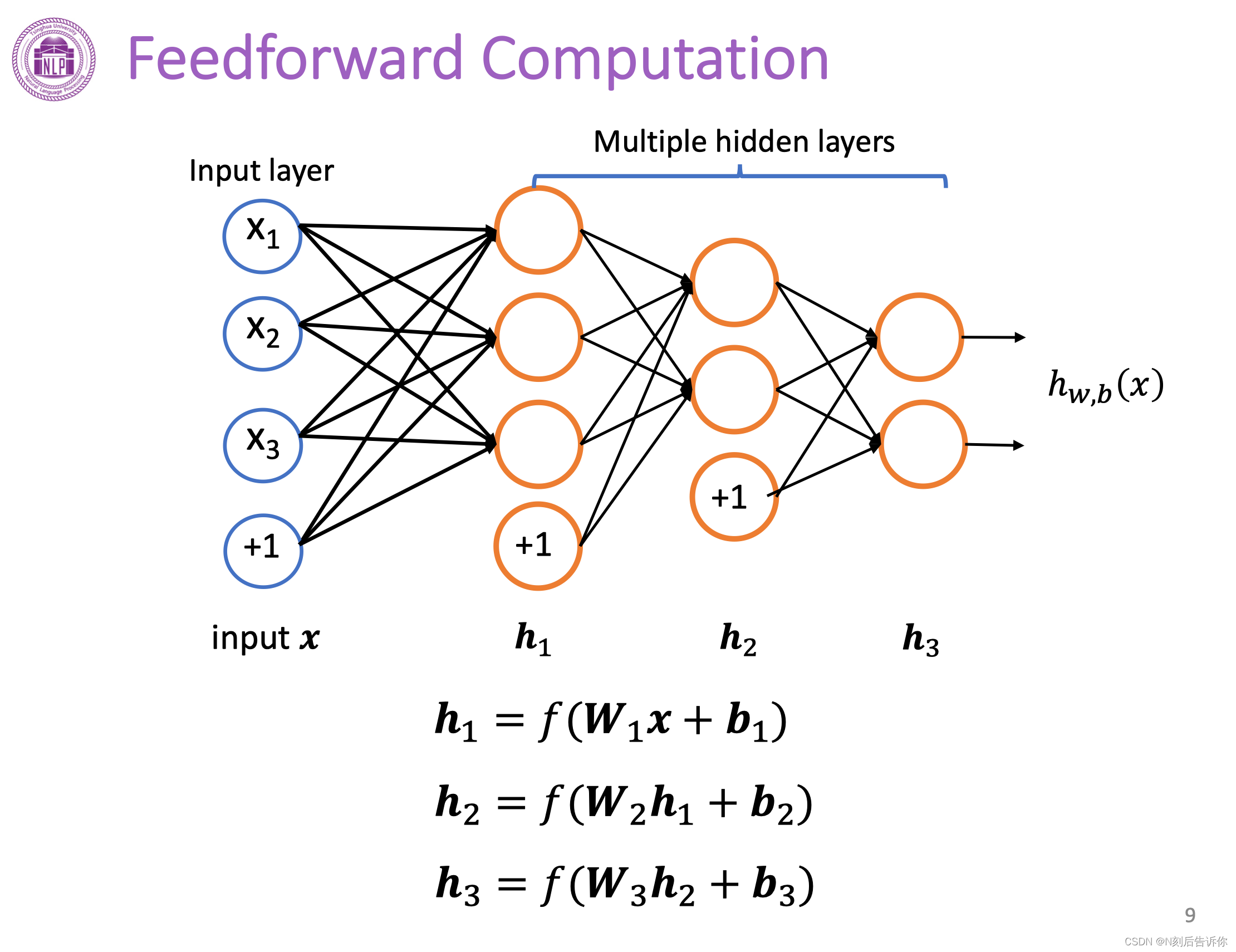
多个单层神经网络叠加在一起可以形成多层神经网络。
从前往后依次进行神经元的计算称为前向计算(传播)。
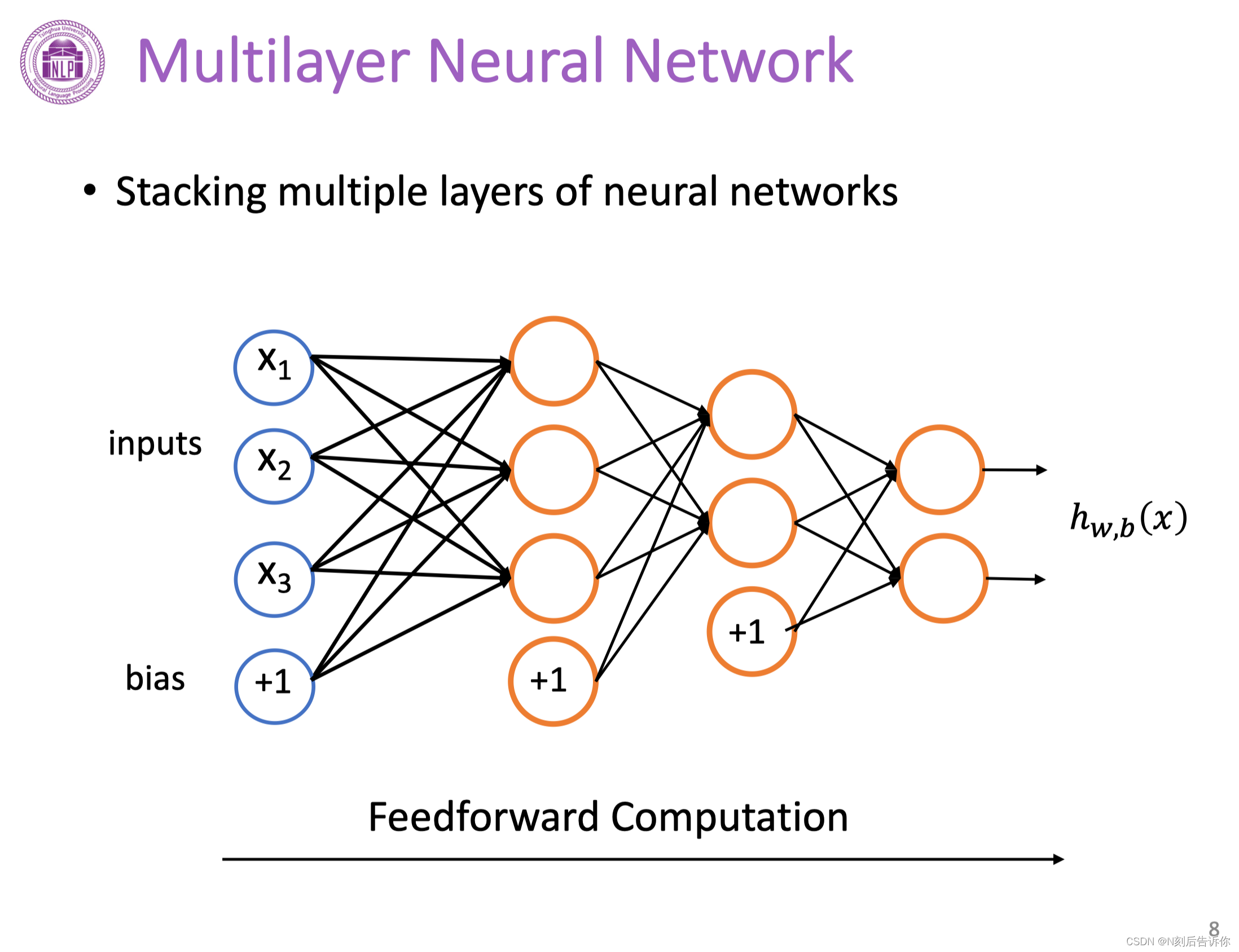
前向计算
前向计算过程中,中间神经元的输出结果被称为隐层输出,用符号h表示。
为什么要用非线性激活函数f?
如果没有非线性激活函数,那么多层神经网络本质上等价为单层神经网络。所以非线性激活函数对保持神经网络的层数,提高神经网络的表达能力是必要的。

常见的激活函数
sigmoid:将实数转化为(0,1)上的数
Tanh:将实数转化为(-1,1)上的数
ReLU:将负数全部转为0,正数保留

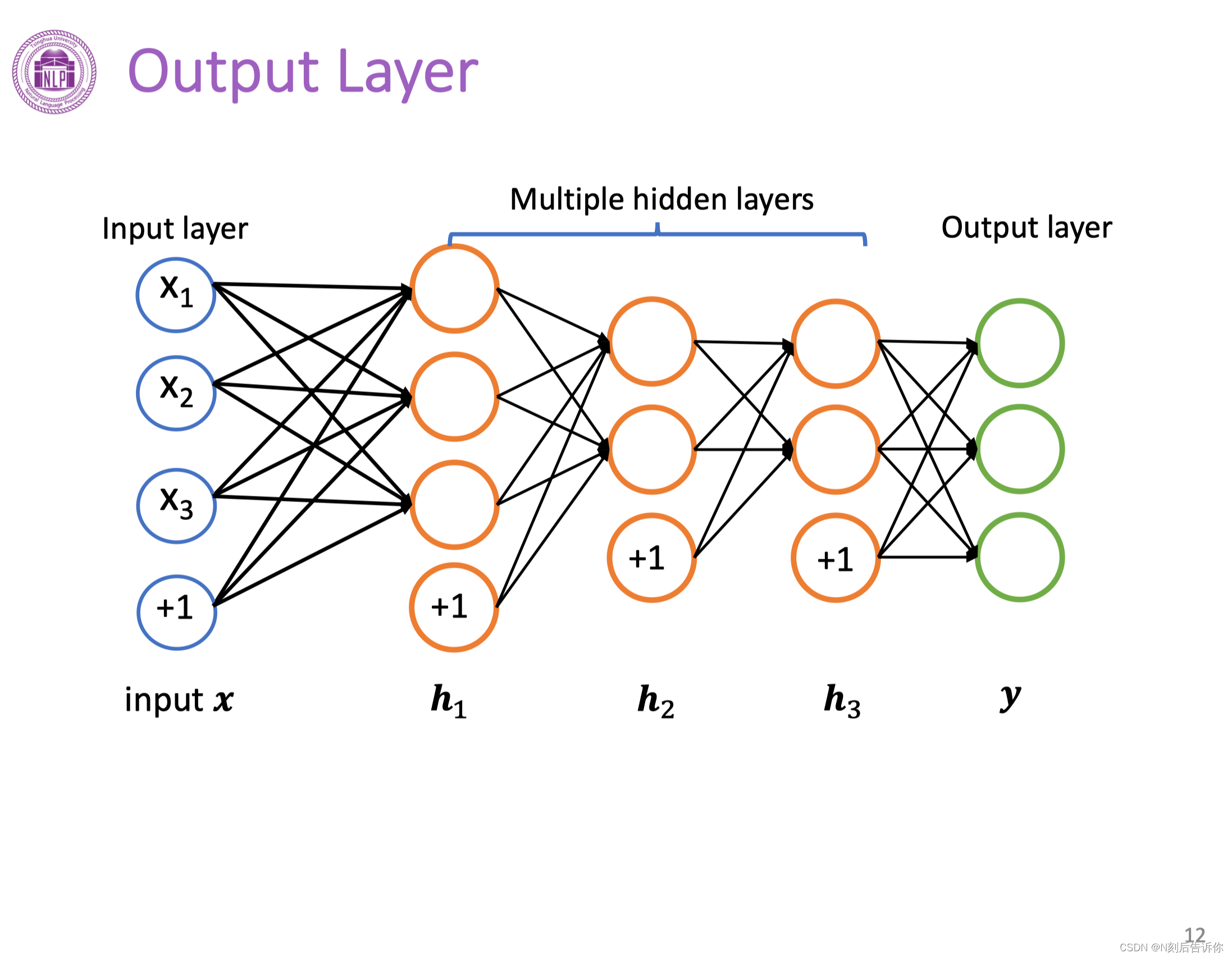
网络的输出层
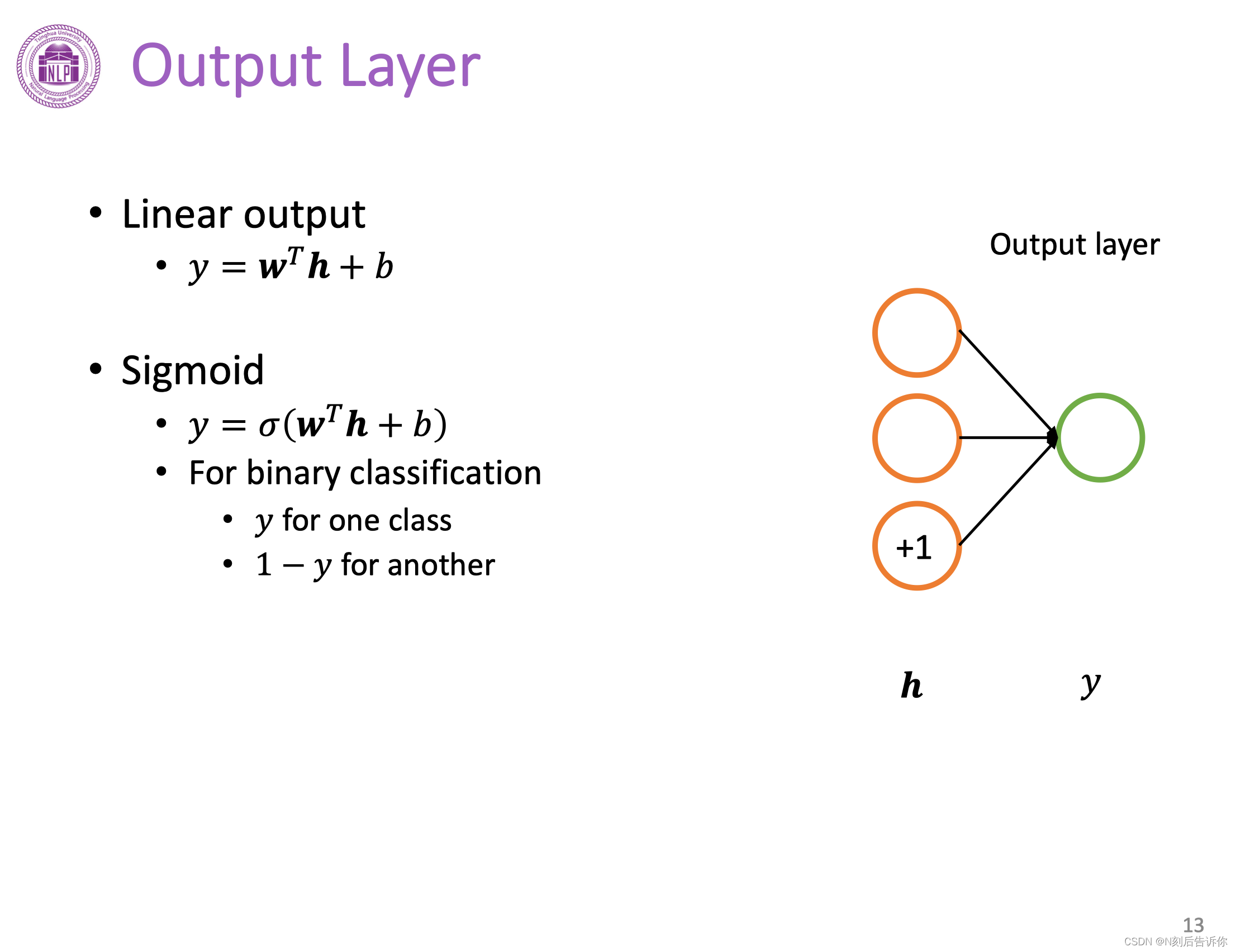
输出层有多种形态,取决于模型的要求。以线性输出和sigmoid输出层为例。
线性输出层一般用于回归问题。
sigmoid输出层可以用于解决二分类问题:将隐层结果压到(0,1),然后这个值用于概率。
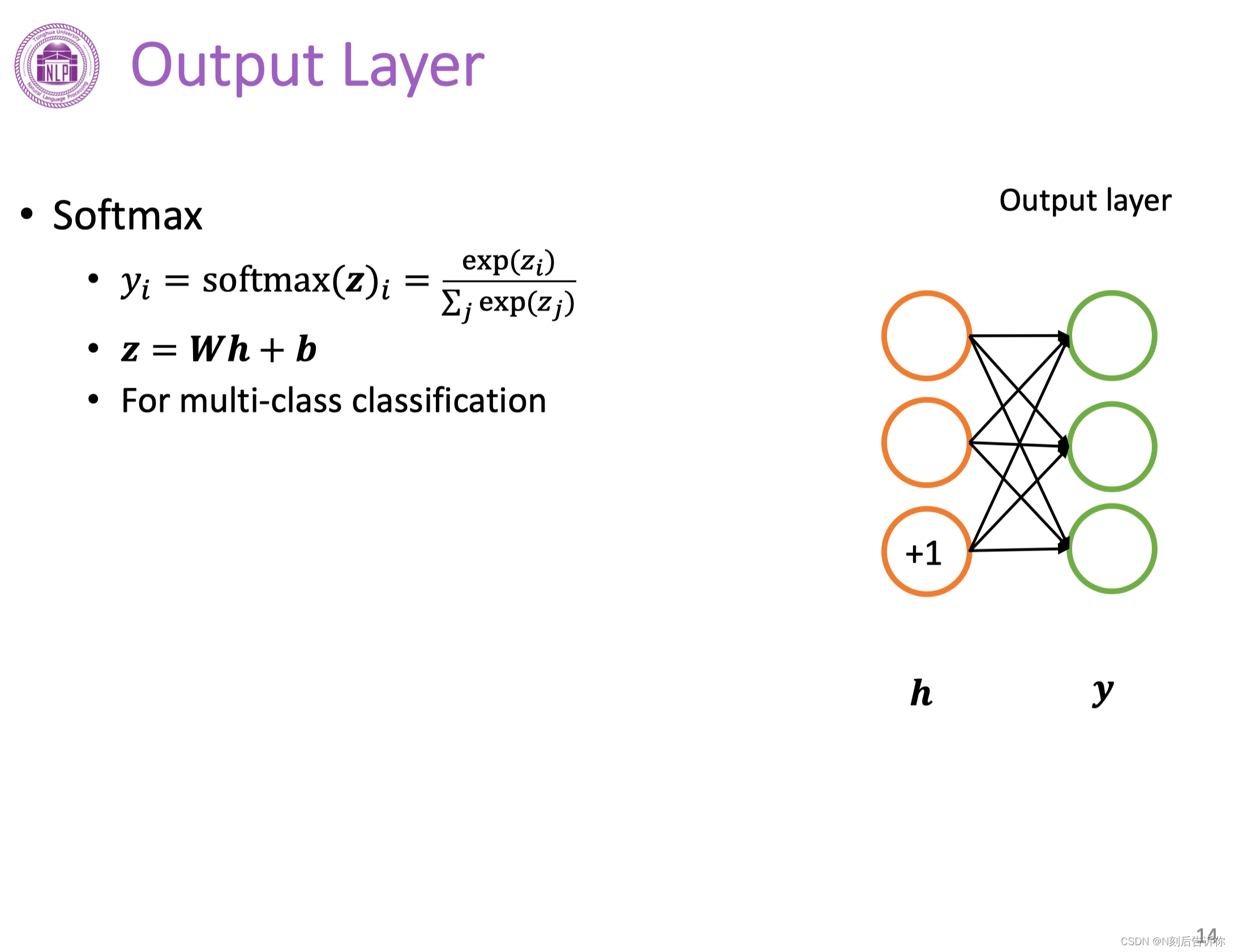
softmax输出层可以解决多分类问题:首先将隐层结果转化为我们分类的维度长的向量,然后经过softmax函数转化为概率向量。
如何训练一个神经网路
训练目标
回归问题,可以用最小化均方差作为训练目标。

分类问题,可以用最小化交叉熵作为训练目标。

随机梯度下降
沿着负梯度方向可以使函数值下降。
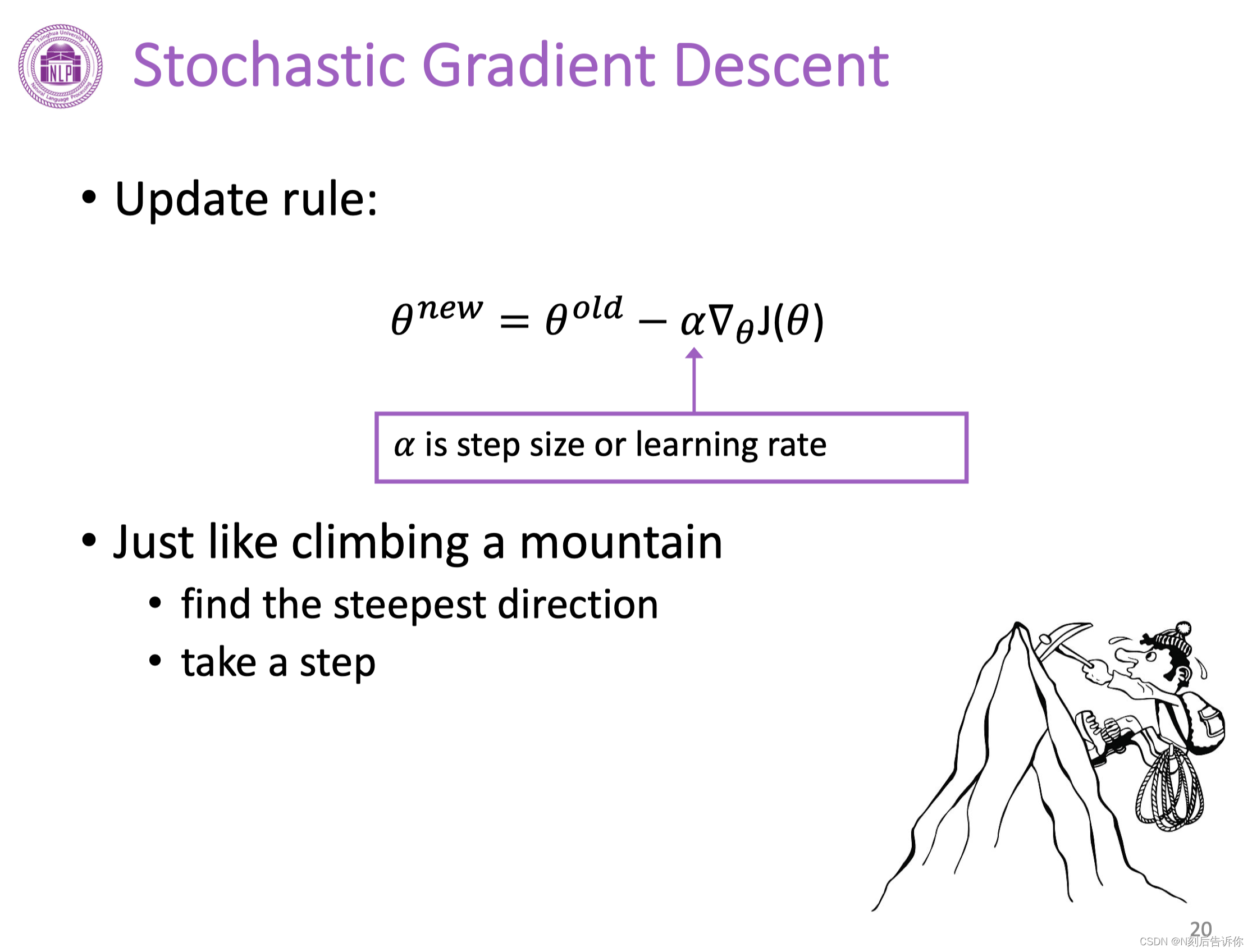
梯度

链式法则

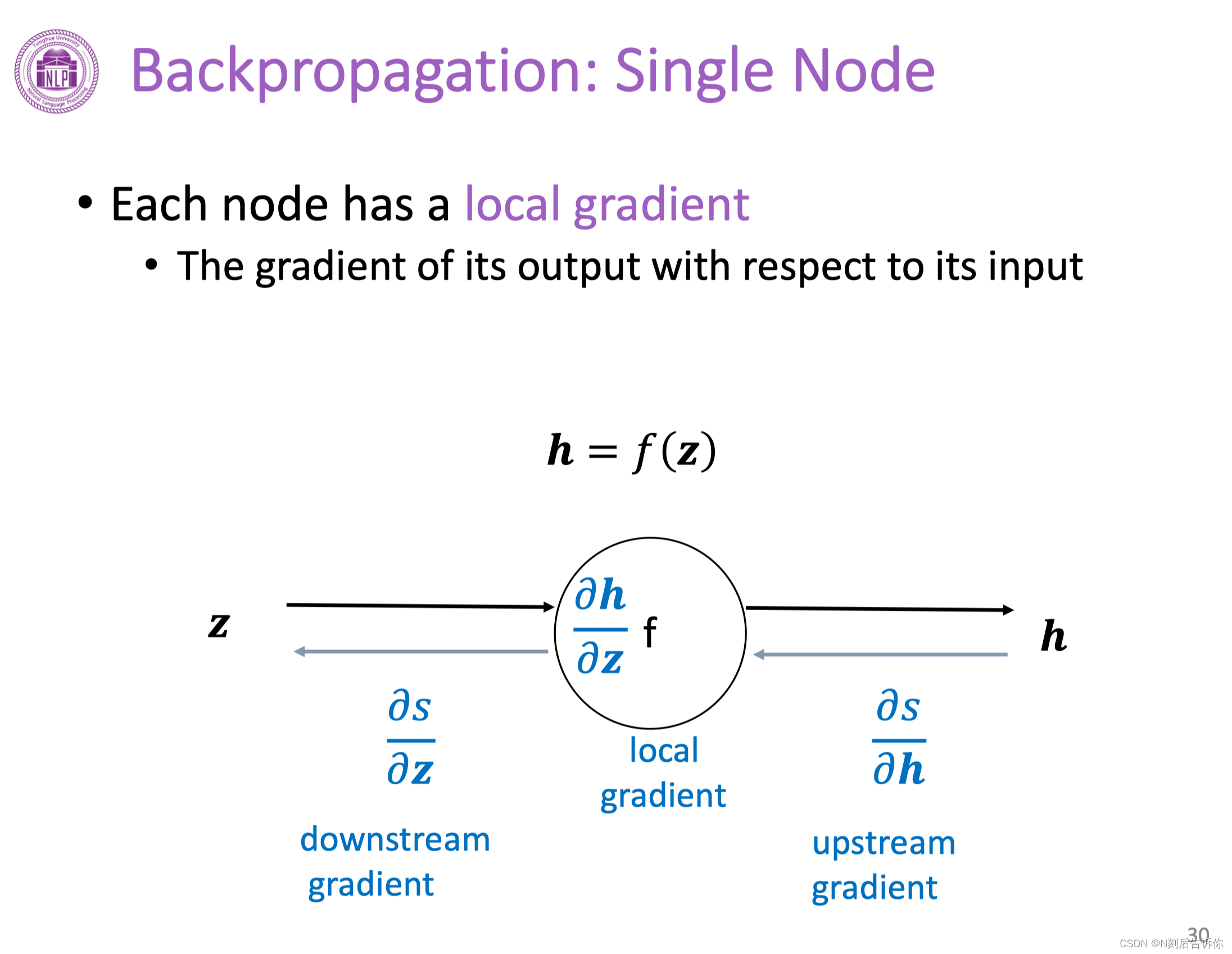
反向传播
在实际深度学习场景中,对每个参数梯度的计算是通过反向传播算法实现的。
下面先介绍计算图的概念。
计算图
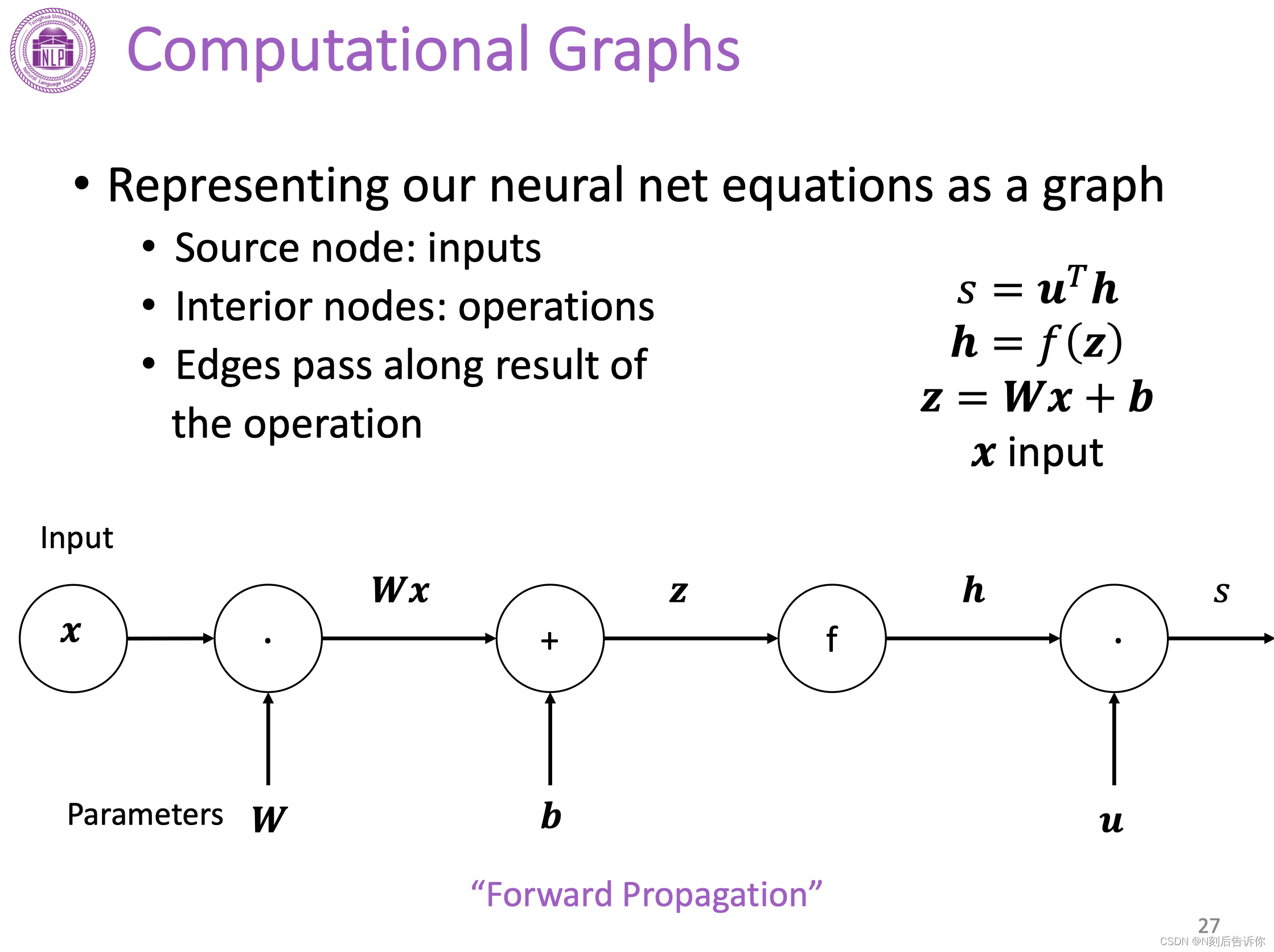
反向传播
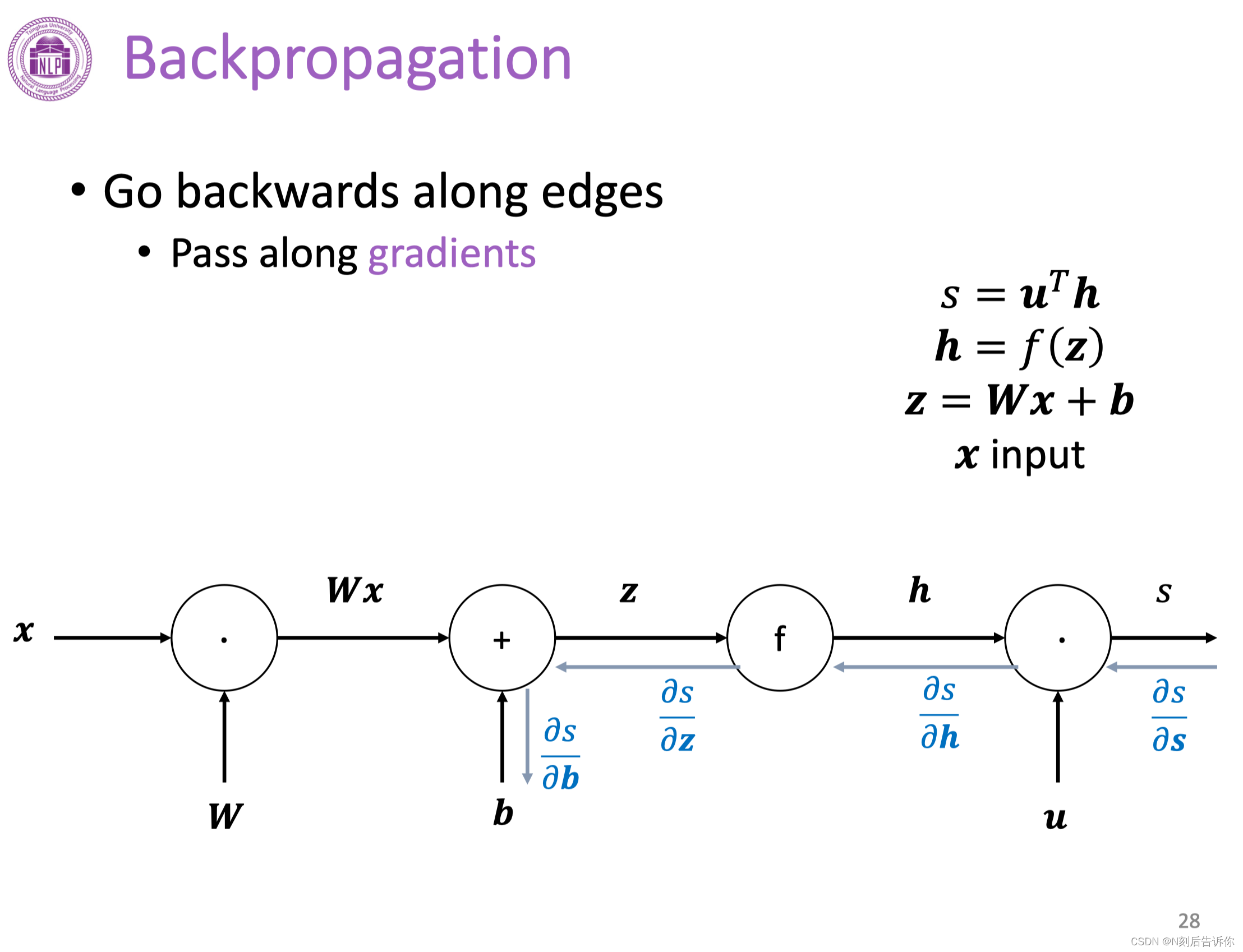
反向传播(单个节点)
链式法则可以将上游梯度和下游梯度通过本地梯度链接起来。
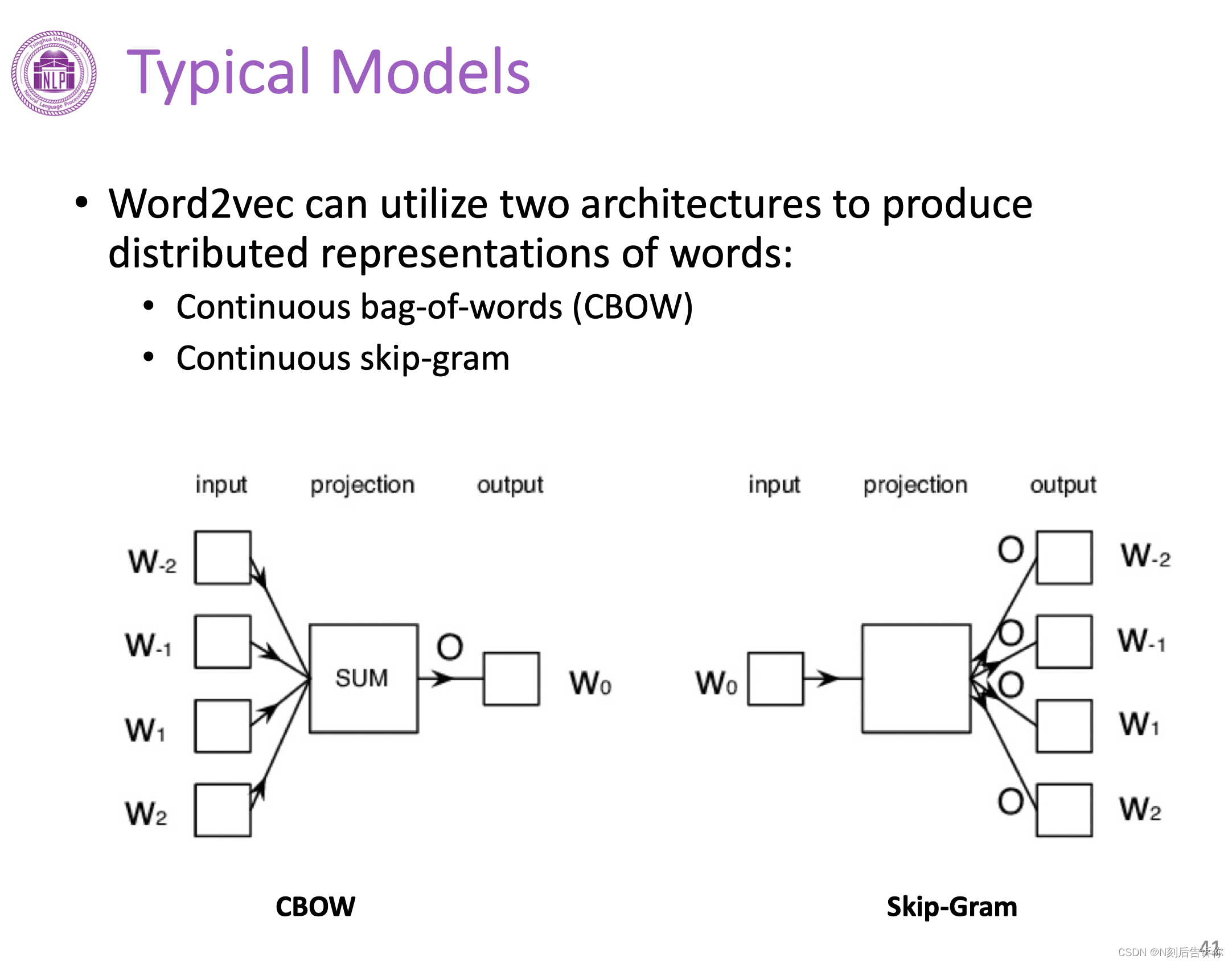
词向量表示:Word2Vec
Word2Vec实际上有两类模型,一类是Continuous bag-of-words(CBOW),一类叫Continuous skip-gram。
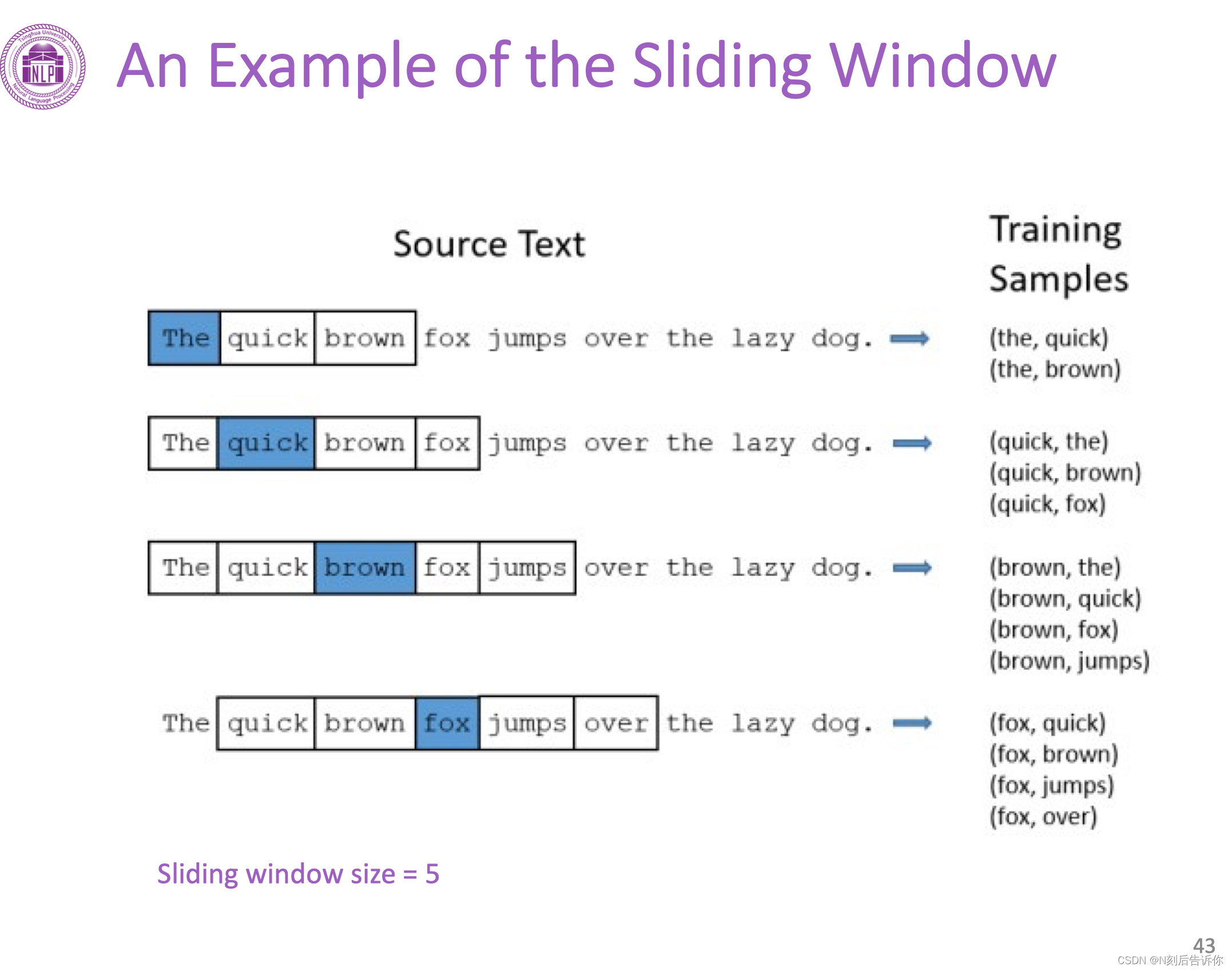
滑动窗口
Word2Vec使用滑动窗口来构造训练数据。滑动窗口是指一段文本中连续出现的几个单词。窗口中间的词称为target,其他被称为context。
CBOW是根据context词来预测target词的模型。
skip-gram则相反,是根据target词来预测context词的模型。

例子
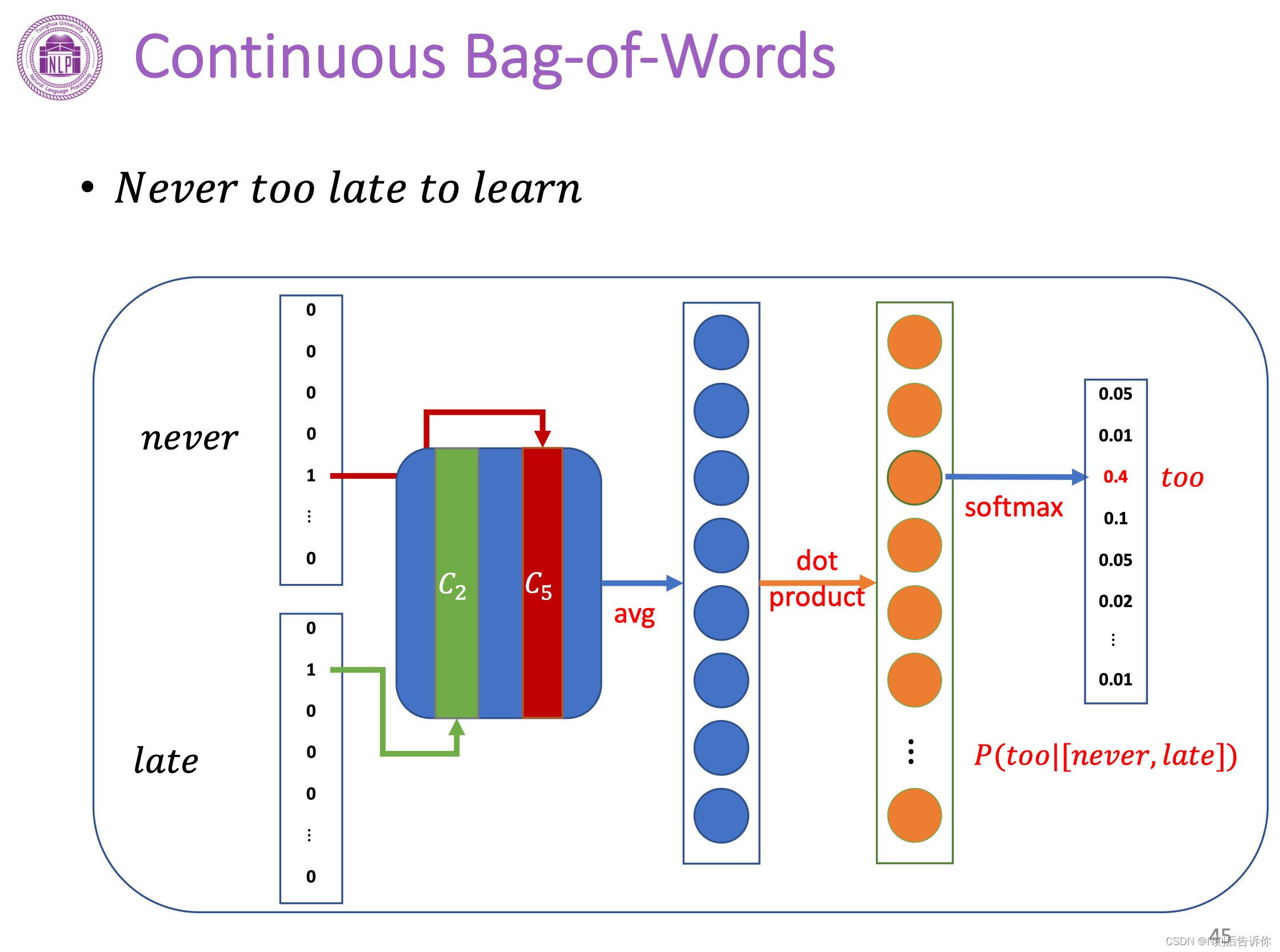
CBOW模型
bag-of-word假设不考虑context词的顺序对target词的预测的影响。
以Never to late to learn这句话为例,应用CBOW模型。假设窗口大小为3,就是要用never,late来预测too。
下面是CBOW的网络结构。
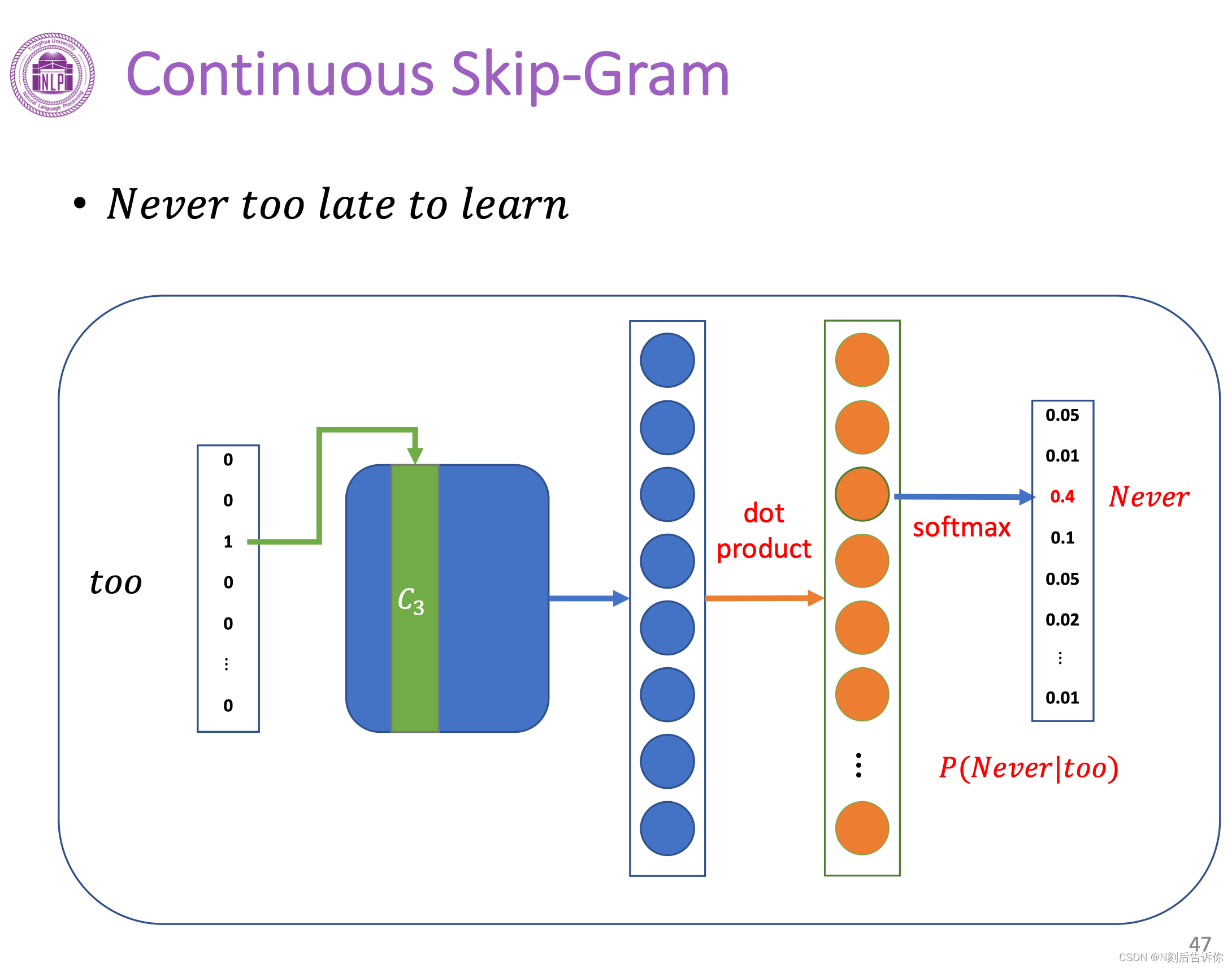
Skip-Gram模型
下面是Skip-Gram的模型结构。
Full Softmax的问题
上面两个模型,最后都将转化为分类问题,最后经过映射到词表大小的频率向量中,最后再使用cross entropy loss来进行训练。
但是当词表非常大的时候,进行softmax后,进行反向传播的计算量非常大。所以需要想办法提高计算的效率。
下面介绍两种提高计算效率的方法:
负采样(Negative sampling)
想法是不对所有负例更新权重,而是采样其中一部分进行权重更新。采样的依据是词的频率,词频越高越容易被采样。


负采样使得最后需要更新的参数量下降很多,使Word2Vec模型计算成为可能。

分层softmax(Hierarchical softmax)
略
Word2Vec的其他训练技巧
Sub-Sampling
为了平衡常见词和罕见词出现的频率。一般而言,罕见词出现概率低,但是可能包含丰富语义信息,所以利用下面的公式计算去掉一些词的概率。具体来说,如果一个词出现频次高,那么这个词被去掉的概率就越高。

非固定大小的滑动窗口
前面讲到的context词处于平等地位。实际上,如果考虑离target词近的词可能比远离target词的context词更与target词相关。所以可以考虑使用不固定大小的滑动窗口。它的大小根据采样得到。这样离target词近的词有更大概率被采样和训练。

循环神经网络RNNs
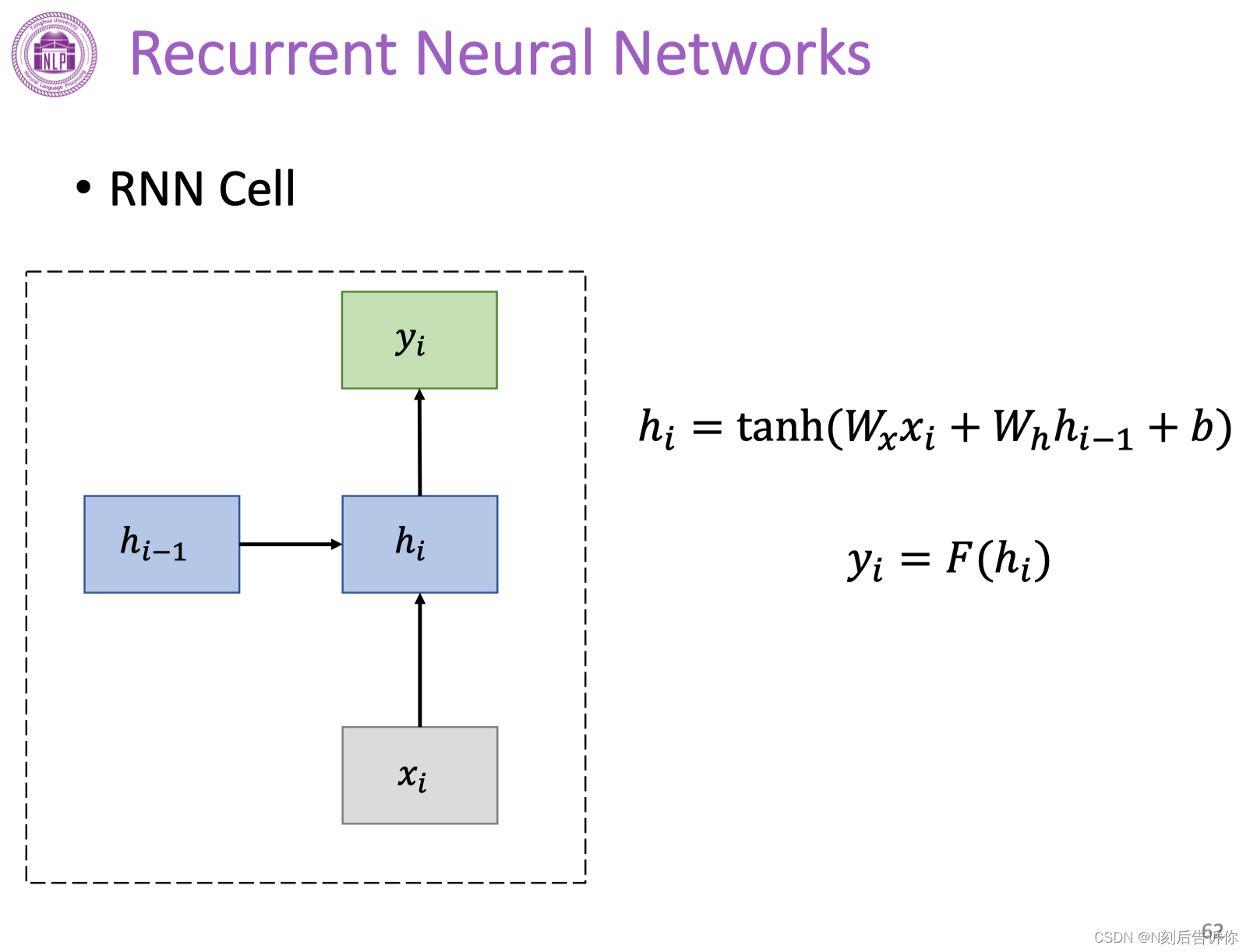
下图是RNN的神经网络结构。

RNN单元
上面的RNN网络结构可以看成是RNN单元的复制。
RNN当前隐藏状态的值是依赖于过去隐藏状态值的。
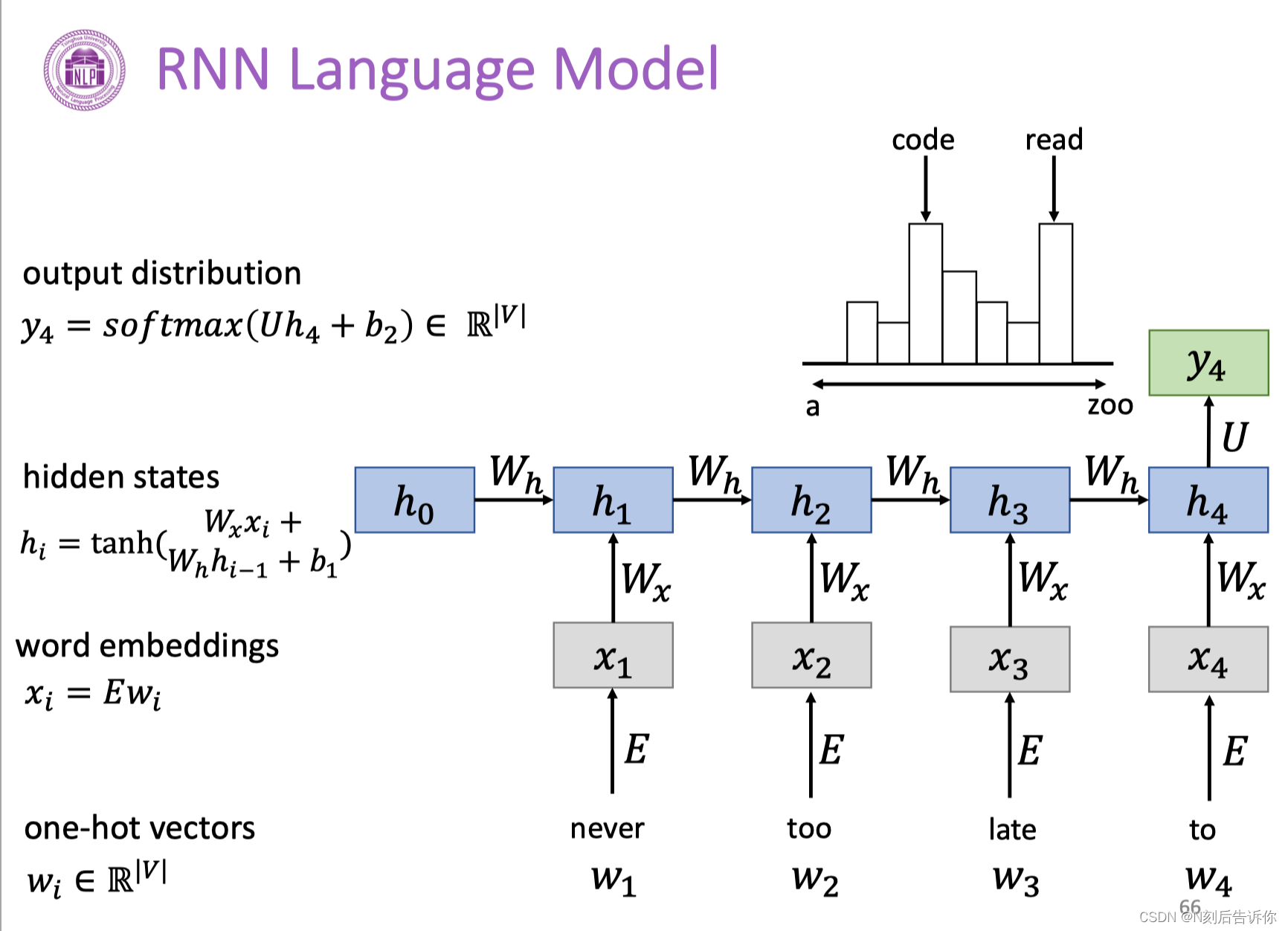
RNN语言模型
下面是一个例子。可以发现其中的参数是共享的,这有助于模型可以泛化到不同长度的样本。也有助于减少参数量。
RNN的应用场景
序列标注(Sequence Labelling):给定一句话,要求给出每个词的词性
序列预测(Sequence Prediction):给定一周七天的温度,预测每天的天气情况
图片描述(Photograph Description):给定图片,创造一句话来描述对应图片
文本分类(Text Classification):给定一句话,区分其情感是正面还是负面的
RNN的优缺点
优点:
- 可以处理变长数据
- 模型大小不会随着输入的增大而增大
- 权重是共享的
- 后面的计算理论上可以获取到前面的信息
缺点:
- 顺序计算很慢
- 实际应用中,后面的计算很难获取到前面的信息
RNN上的梯度问题-梯度消失/爆炸
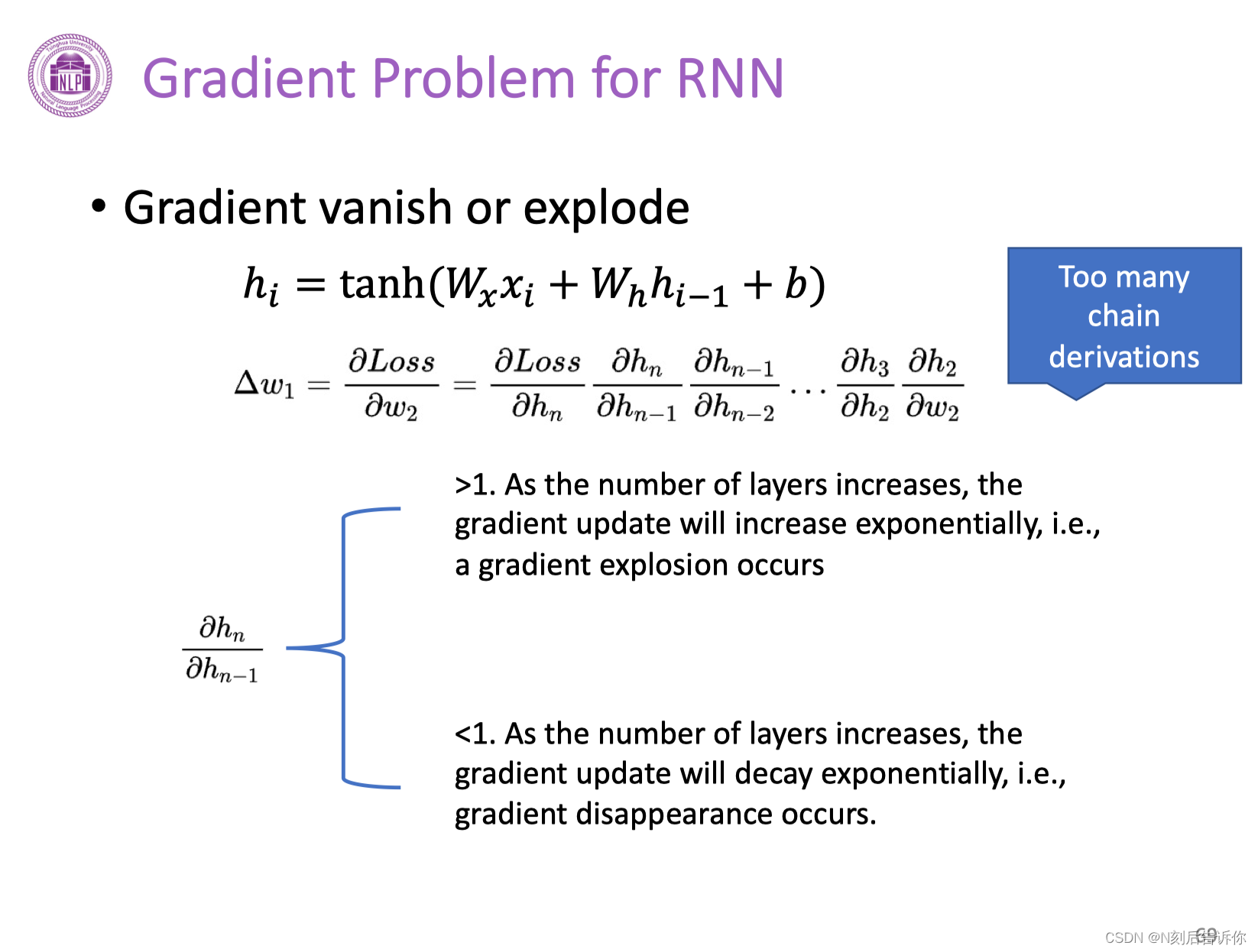
为了解决RNN的缺陷,需要更优的RNN单元。因此提出了两个变体,分别是GRU和LSTM。
Gated Recurrent Unit(GRU)
在传统RNN中引入gating机制。分别引入更新门和重置门。这两个门的作用是权衡过去信息和当前信息的影响。


下面演示一个GRU的计算。
分别计算重置门的系数,更新门的系数。新的临时隐藏层参数。再加上上一层隐藏层的输出。利用这些就可以计算需要传输到下一层的隐藏变量hi。
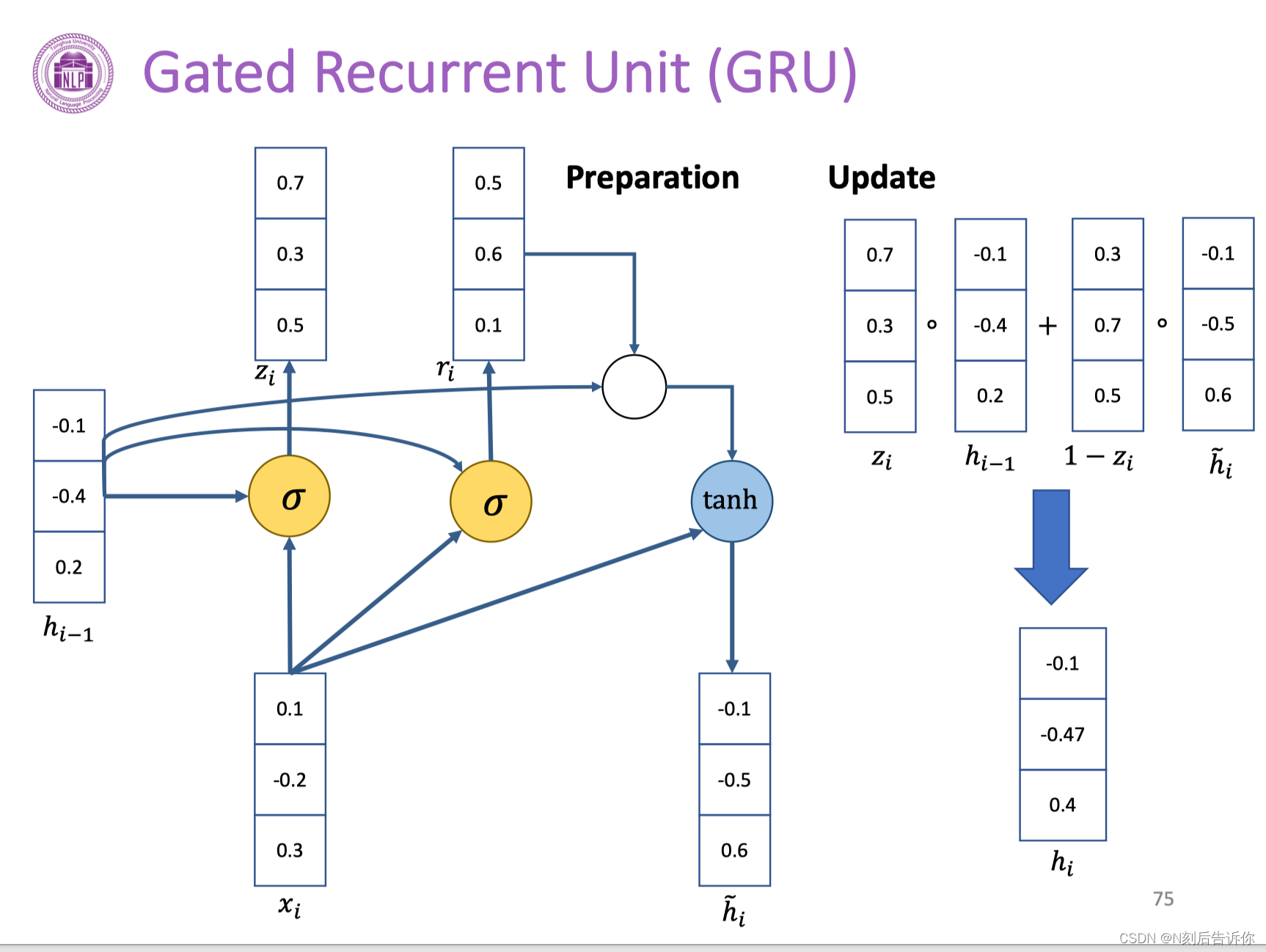
当重置门的系数为0时,则上一层隐藏层的输入不参与这一层临时隐藏层的计算。
一个例子是,一个新文章的开头,过去的信息是无用的。

更新门的系数接近1,则表示当前层的输出近似等于上一层的隐藏层输出。
如果系数接近0,则当前层的输出近似等于当前层临时隐藏变量,相当于丢弃了之前的状态。

卷积神经网络CNNs
这篇关于[学习笔记]刘知远团队大模型技术与交叉应用L2-Neural Network Basics的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






