本文主要是介绍【网络通信 -- WebRTC】项目实战记录 -- MediaSoup 模糊测试 Fuzzer 使用简记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【网络通信 -- WebRTC】项目实战记录 -- MediaSoup 模糊测试 Fuzzer 使用简记
【1】搭建 Fuzzer 相关环境
安装 clang/LLVM 环境git clone https://gitee.com/mirrors/LLVM.gitcd LLVM ; mkdir build ; cd build
cmake -DLLVM_ENABLE_PROJECTS="clang;clang-tools-extra;compiler-rt" -DCMAKE_BUILD_TYPE="Release" -DLLVM_TARGETS_TO_BUILD="host" -G "Unix Makefiles" ../llvmsudo make
sudo make install【2】编译 Mediasoup 的 Fuzzer 测试工程
make CC=clang CXX=clang++ fuzzer【3】Mediasoup 的 Fuzzer 测试用例分析
【3.0】测试用例分析
Fuzzer 测试用例需要实现如下的入口函数,从而可以接收 Fuzzer 引擎产生的测试数据;
extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t len)
{...
}【3.1】运行测试用例
Detect memory leaks and just fuzz STUN
针对 STUN 进行 fuzzer 测试
命令
$ MS_FUZZ_STUN=1 LSAN_OPTIONS=verbosity=1:log_threads=1 ./out/Release/mediasoup-worker-fuzzer -artifact_prefix=fuzzer/reports/new/ -max_len=1400 -runs=10000 fuzzer/new-corpus deps/webrtc-fuzzer-corpora/corpora/stun-corpusDetect memory leaks and just fuzz RTP
针对 RTP 进行 fuzzer 测试
命令
$ MS_FUZZ_RTP=1 LSAN_OPTIONS=verbosity=1:log_threads=1 ./out/Release/mediasoup-worker-fuzzer -artifact_prefix=fuzzer/reports/new/ -max_len=1400 -runs=10000 fuzzer/new-corpus deps/webrtc-fuzzer-corpora/corpora/rtp-corpusDetect memory leaks and just fuzz RTCP
针对 RTCP 进行 fuzzer 测试
命令
$ MS_FUZZ_RTCP=1 LSAN_OPTIONS=verbosity=1:log_threads=1 ./out/Release/mediasoup-worker-fuzzer -artifact_prefix=fuzzer/reports/new/ -max_len=1400 -runs=10000 fuzzer/new-corpus deps/webrtc-fuzzer-corpora/corpora/rtcp-corpusDetect memory leaks and just fuzz mediasoup-worker C++ utils
针对 Mediasoup Utils 进行 fuzzer 测试
命令
$ MS_FUZZ_UTILS=1 LSAN_OPTIONS=verbosity=1:log_threads=1 ./out/Release/mediasoup-worker-fuzzer -artifact_prefix=fuzzer/reports/new/ -max_len=2000 -runs=10000 fuzzer/new-corpus【4】crash 检测与分析
若测试过程中检测到代码问题,libfuzzer 会产生对应的 crash 文件,可以通过对 crash 文件的分析协助定位代码问题。
例如如下代码,其中存在堆栈溢出的问题,运行 fuzzer 测试会产生 crash 文件,此时可以对该 crash 文件进行分析。
extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t len)
{if(len < 60){std::cout << "len is : " << len << std::endl;std::cout << "data[61] is : " << data[61] << std::endl;}
}检测 crash 文件的命令如下
LSAN_OPTIONS=verbosity=1:log_threads=1 ./out/Release/mediasoup-worker-fuzzer ./fuzzer/reports/new/crash-da39a3ee5e6b4b0d3255bfef95601890afd80709其中
mediasoup-worker-fuzzer : 为基于 libfuzzer 编译的可执行文件
crash-da39a3ee5e6b4b0d3255bfef95601890afd80709 : 为 libfuzzer 检测出的崩溃文件恢复出的错误信息如下
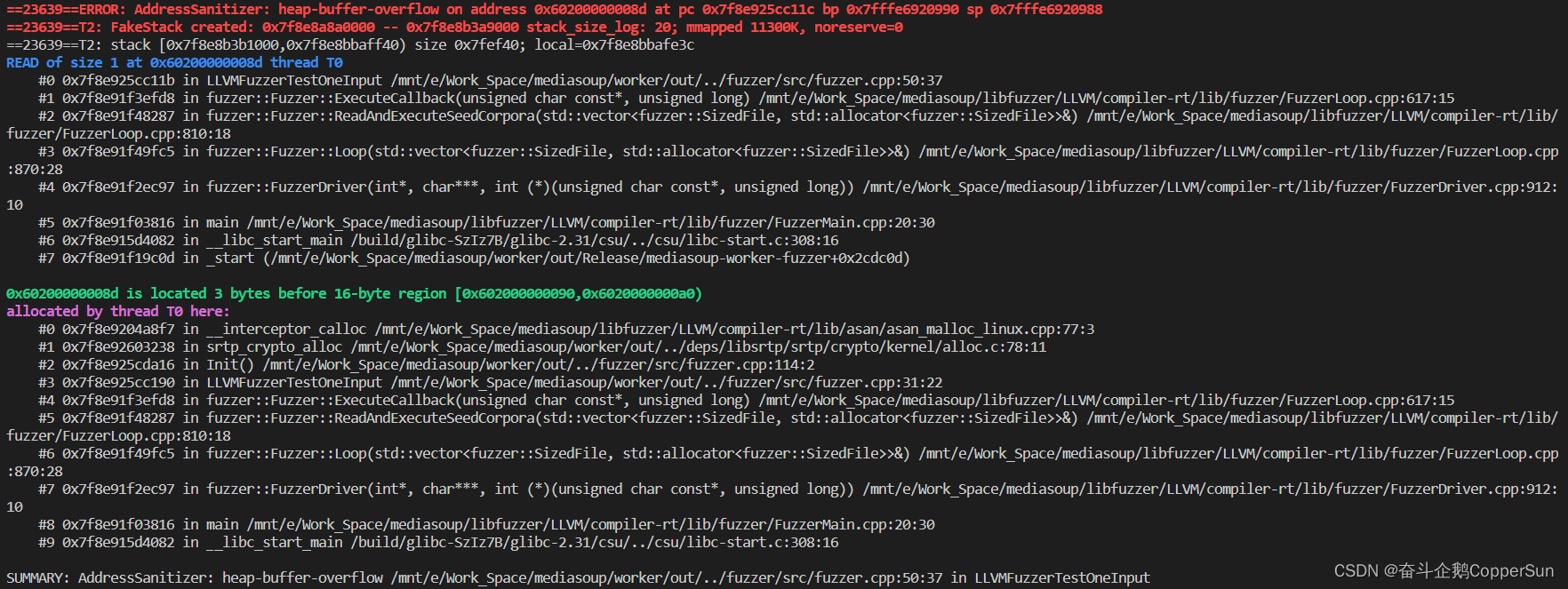
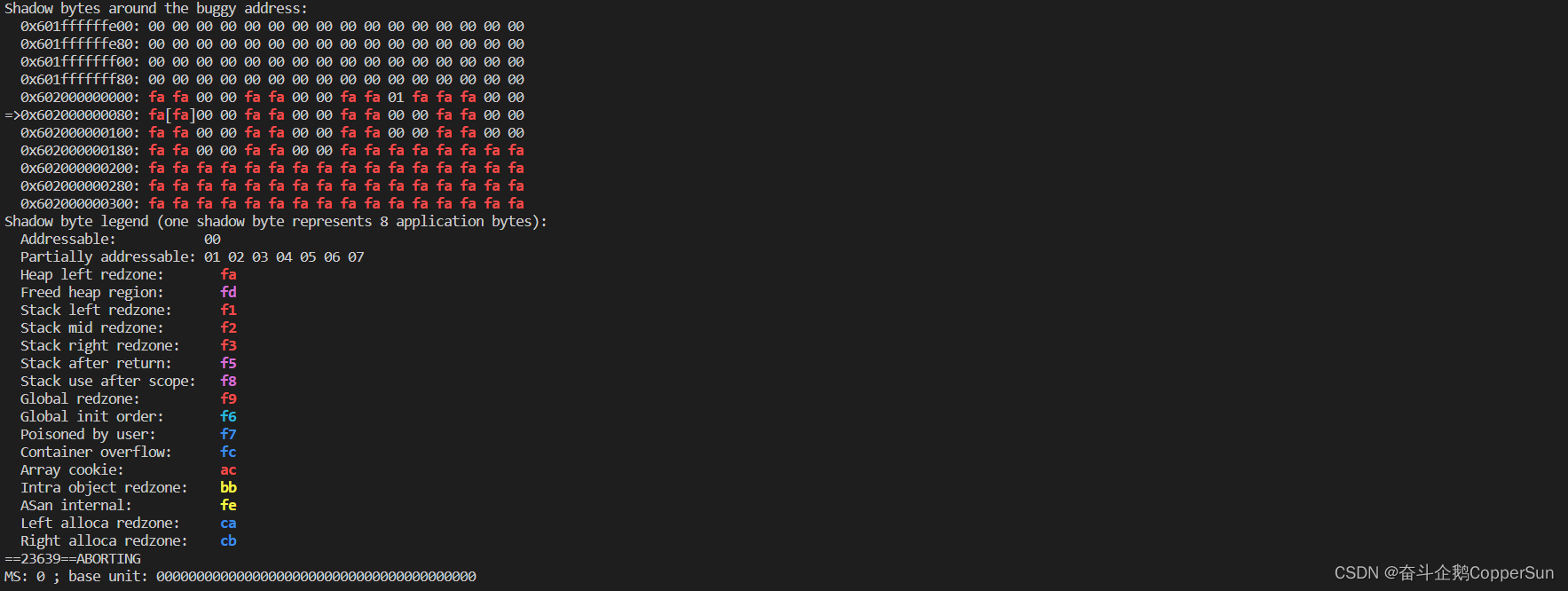
【5】libFuzzer
【5.1】libFuzzer 简介
LibFuzzer是一个 in-process,coverage-based,evolutionary 的模糊测试引擎,是 LLVM 项目的一部分,它与被测库链接,通过特定的入口点将模糊测试的输入提供给被测函数,并在测试过程中不断变异输入,并统计代码覆盖率和崩溃情况;
【5.2】libFuzzer 变异算法
变异 (Mutation) 算法用于产生新的且能够覆盖更多基本块的输入,LibFuzzer 包含了一系列内置的简单的变异算法具体如下,这些内置的变异算法中,变异的位置的和变异的值都是采用 Rand 随机函数生成。
// 代码路径:LLVM/compiler-rt/lib/fuzzer/FuzzerMutate.cppMutationDispatcher::MutationDispatcher(Random &Rand, const FuzzingOptions &Options) : Rand(Rand), Options(Options) {DefaultMutators.insert(DefaultMutators.begin(),{{&MutationDispatcher::Mutate_EraseBytes, "EraseBytes"},{&MutationDispatcher::Mutate_InsertByte, "InsertByte"},{&MutationDispatcher::Mutate_InsertRepeatedBytes, "InsertRepeatedBytes"},{&MutationDispatcher::Mutate_ChangeByte, "ChangeByte"},{&MutationDispatcher::Mutate_ChangeBit, "ChangeBit"},{&MutationDispatcher::Mutate_ShuffleBytes, "ShuffleBytes"},{&MutationDispatcher::Mutate_ChangeASCIIInteger, "ChangeASCIIInt"},{&MutationDispatcher::Mutate_ChangeBinaryInteger, "ChangeBinInt"},{&MutationDispatcher::Mutate_CopyPart, "CopyPart"},{&MutationDispatcher::Mutate_CrossOver, "CrossOver"},{&MutationDispatcher::Mutate_AddWordFromManualDictionary, "ManualDict"},{&MutationDispatcher::Mutate_AddWordFromPersistentAutoDictionary, "PersAutoDict"},});// 以上函数的具体实现}
【5.2】libFuzzer 语料库 (Corpus)
libFuzzer 覆盖引导模糊器依赖于被测代码的样本输入语料库,理想情况下,该语料库会为被测代码提供各种有效和无效的输入;模糊器基于当前语料库中的样本输入生成随机突变,如果突变触发了测试代码中先前未覆盖的路径的执行,则该突变将保存到语料库中以供将来变更;
运行模糊器,需要将零个或多个语料库目录作为命令行参数传递,模糊器将读取每个语料库目录中的测试样本输入,并且生成的任何新测试输入将被写回第一个语料库目录;
【5.3】libFuzzer 选项
libFuzzer 的命令行一般格式如下
./fuzzer [-flag1=val1 [-flag2=val2 ...] ] [dir1 [dir2 ...] ]常用的选项如下
- -help
- 打印帮助信息
- -seed
- 随机种子,如果为 0 (默认值) 则生成种子
- -runs
- 单个测试运行的次数,-1 (默认值) 无限期运行
- -max_len
- 测试输入的最大长度,如果为 0 (默认值) ,则 libFuzzer 会尝试根据语料库猜测一个好的值
- len_control
- 首先尝试生成小输入,然后尝试更大的输入,指定长度限制增加的速率,默认值为 100,如果为 0 则立即尝试输入大小为 max_len 的输入;
- -timeout
- 超时 (单位 : 秒) 默认为 1200,如果输入的时间超过此值则将该过程视为故障情况
- -rss_limit_mb
- 内存使用限制,单位为 Mb,默认为 2048,使用 0 则禁用该限制,如果输入需要执行超过此数量的 RSS 内存,则该过程将被视为失败案例;
- -malloc_limit_mb
- 如果非零,如果目标尝试使用一个 malloc 调用分配此数量的 Mb,则模糊器将退出。如果应用零(默认)相同的限制,则应用rss_limit_mb。
- -timeout_exitcode
- 如果 libFuzzer 报告超时使用的退出代码 (默认为 77)
- -error_exitcode
- 如果 libFuzzer 本身报告错误 (泄漏,OOM 等),使用的退出代码 (默认为77)
- -max_total_time
- 如果为正则表示运行模糊器的最长总时间 (单位 : 秒),如果为 0 (默认值) 则无限期运行
- -merge
- 如果设置为 1 则触发新代码覆盖的第 2,第 3 等语料库目录中的任何语料库输入将合并到第一个语料库目录中,默认为 0 此标志可用于最小化语料库
- -merge_control_file
- 指定用于合并进程的控制文件。如果合并进程被杀死,它会尝试将此文件保留在适合恢复合并的状态。默认情况下,将使用临时文件。
- -minimize_crash
- 如果为 1 则最小化提供的崩溃输入,与 -runs = N 或 -max_total_time = N 一起使用以限制尝试次数
- -reload
- 如果设置为 1 (默认值) 则定期重新读取语料库目录以检查新输入;这允许检测由其他模糊测试过程发现的新输入。
- -jobs
- 要运行完成的模糊测试作业的数量;默认值为 0 表示运行单个模糊测试过程直到完成,如果值 > = 1 则将存在 jobs 个作业在并行的单独工作进程中执行模糊测试;每个这样的工作进程都将其 stdout / stderr 重定向到 fuzz- <JOB> .log 文件中
- -workers
- 同时运行模糊测试作业的工作进程数,如果为 0 (默认值) 则使用 min(jobs,NumberOfCpuCores() / 2)
- -dict
- 提供输入关键字的字典
- -use_counters
- 使用覆盖计数器生成代码块被击中频率的近似计数,默认为 1
- -reduce_inputs
- 尽量减少输入的大小,同时保留其完整的功能集,默认为 1
- -use_value_profile
- 使用价值观来指导语料库的扩展,默认为 0
- -only_ascii
- 如果为 1 则仅生成 ASCII (isprint`` +``isspace) 输入,默认为 0
- -artifact_prefix
- 提供在将 fuzzing 工件 (崩溃,超时或慢速输入) 保存为 $(artifact_prefix) 文件时使用的前缀,默认为空
- -exact_artifact_path
- 如果为空则忽略 (默认值),如果非空则将失败时写入的单个工件(崩溃,超时) 写为$(exact_artifact_path),这会覆盖 -artifact_prefix 并且不会在文件名中使用校验和,不要对多个并行进程使用相同的路径
- -print_pcs
- 如果为 1 则打印出新覆盖的 PCs,默认为 0
- -print_final_stats
- 如果为 1 则退出时打印统计信息,默认为 0
- -detect_leaks
- 如果为 1 (默认值) 且启用了 LeakSanitizer 则尝试在模糊测试期间检测内存泄漏
- -close_fd_mask
- 指示在启动时关闭的输出流
- 0 (默认值) :既不关闭 stdout 也不关闭 stderr
- 1:关闭 stdout
- 2:关闭 stderr
- 3:关闭 stdout 和 stderr
- 指示在启动时关闭的输出流
【5.4】libFuzzer 输出
执行 libFuzzer 期间的输出如下
INFO: Seed: 1523017872
INFO: Loaded 1 modules (16 guards): [0x744e60, 0x744ea0),
INFO: -max_len is not provided, using 64
INFO: A corpus is not provided, starting from an empty corpus
#0 READ units: 1
#1 INITED cov: 3 ft: 2 corp: 1/1b exec/s: 0 rss: 24Mb
#3811 NEW cov: 4 ft: 3 corp: 2/2b exec/s: 0 rss: 25Mb L: 1 MS: 5 ChangeBit-ChangeByte-ChangeBit-ShuffleBytes-ChangeByte-
#3827 NEW cov: 5 ft: 4 corp: 3/4b exec/s: 0 rss: 25Mb L: 2 MS: 1 CopyPart-
#3963 NEW cov: 6 ft: 5 corp: 4/6b exec/s: 0 rss: 25Mb L: 2 MS: 2 ShuffleBytes-ChangeBit-
#4167 NEW cov: 7 ft: 6 corp: 5/9b exec/s: 0 rss: 25Mb L: 3 MS: 1 InsertByte-
...- 部分 1 包含 fuzzer 的相关选型和配置信
- 部分 2 包含相关事件以及统计信息
- 事件
- READ
- The fuzzer has read in all of the provided input samples from the corpus directories.
- fuzzer 已经从语料目录中读取所有提供的输入样本
- INITED
- The fuzzer has completed initialization, which includes running each of the initial input samples through the code under test.
- fuzzer 已经完成初始化, 即通过测试代码运行所有初始输入样本
- NEW
- The fuzzer has created a test input that covers new areas of the code under test. This input will be saved to the primary corpus directory.
- fuzzer 已经创建了测试输入,覆盖了测试代码的新的区域,这些输入将被保存在主要的语料目录中
- REDUCE
- The fuzzer has found a better (smaller) input that triggers previously discovered features (set -reduce_inputs=0 to disable).
- fuzzer 已经查找到由先前发现的特性触发的更好的输入
- PULSE
- The fuzzer has generated 2n inputs (generated periodically to reassure the user that the fuzzer is still working).
- fuzzer 已经生成了 2n 个输入
- DONE
- The fuzzer has completed operation because it has reached the specified iteration limit (-runs) or time limit (-max_total_time).
- fuzzer 已经完成运行
- RELOAD
- The fuzzer is performing a periodic reload of inputs from the corpus directory; this allows it to discover any inputs discovered by other fuzzer processes (see Parallel Fuzzing).
- fuzzer 进行从语料目录中周期性的读取输入,正将使得 fuzzer 实例发现其他 fuzzer 进程发现的输入
- READ
- 事件
- 统计
- cov:
- Total number of code blocks or edges covered by executing the current corpus.
- 执行当前语料库覆盖的代码块或边缘总数
- ft:
- libFuzzer uses different signals to evaluate the code coverage: edge coverage, edge counters, value profiles, indirect caller/callee pairs, etc. These signals combined are called features (ft:).
- libFuzzer 使用不同的信号来评估代码覆盖率,(edge coverage, edge counters, value profiles, indirect caller/callee),这些信号的组合即为特性(ft:)
- corp:
- Number of entries in the current in-memory test corpus and its size in bytes.
- 当前内存测试语料库中的条目数及其字节大小
- lim:
- Current limit on the length of new entries in the corpus. Increases over time until the max length (-max_len) is reached.
- 当前对语料库中新词条长度的限制。随时间增加,直到达到最大长度(-max_len)
- exec/s:
- Number of fuzzer iterations per second.
- 每秒模糊器迭代次数
- rss:
- Current memory consumption. For NEW and REDUCE events, the output line also includes information about the mutation operation that produced the new input:
- 当前内存消耗,对于 NEW 和 REDUCE 事件,输出行还包括有关产生新输入的变异操作的信息
- L:
- Size of the new input in bytes.
- 新输入的大小 (字节)
- MS: <n> <operations>
- Count and list of the mutation operations used to generate the input
- 用于生成输入的变异操作的计数和列表
- cov:
参考致谢
本博客为博主的学习实践总结,并参考了众多博主的博文,在此表示感谢,博主若有不足之处,请批评指正。
【1】libfuzzer从入门到放弃(一)
【2】LibFuzzer学习
【2】libFuzzer – a library for coverage-guided fuzz testing
【3】libFuzzer – a library for coverage-guided fuzz testing(中文翻译)
这篇关于【网络通信 -- WebRTC】项目实战记录 -- MediaSoup 模糊测试 Fuzzer 使用简记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





