本文主要是介绍【书生·浦语】大模型实战营——第五课笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
教程文档:https://github.com/InternLM/tutorial/blob/main/lmdeploy/lmdeploy.md
视频链接:https://www.bilibili.com/video/BV1iW4y1A77P
大模型部署背景
关于模型部署
通常需要模型压缩和硬件加速

大模型的特点
1、显存、内存花销巨大
2、动态shape,输入输出数量不定
3、相对视觉模型,LLM结构简单,大部分都是decoder-only

大模型部署挑战
大模型的特点所带来的部署挑战:
1、设备:如何应对巨大的存储问题?
2、推理:如何加速token生成速度?如何有效管理、使用内存?
3、服务:如何提升系统整体吞吐量,如何降低响应时间?

大模型部署方案

continuous batch用于解决动态batch问题
云端常用的部署方案:deepspeed、tensorrt-llm、vllm、Imdepoly
移动端:llama.cpp(对移动端设备做了优化)、mlc-llm
LMDepoly简介
LMDeploy是LLM在nvidia设备上部署的全流程解决方案。(还没有涉及到移动端)
关于轻量化:
1、权重的4bit量化
2、k v cache的8bit量化
关于推理引擎:
1、turbomind,是LMDeploy的一个创新点
2、pytorch
关于服务:
1、api server
2、gradio:主要用于演示demo
3、triton inference

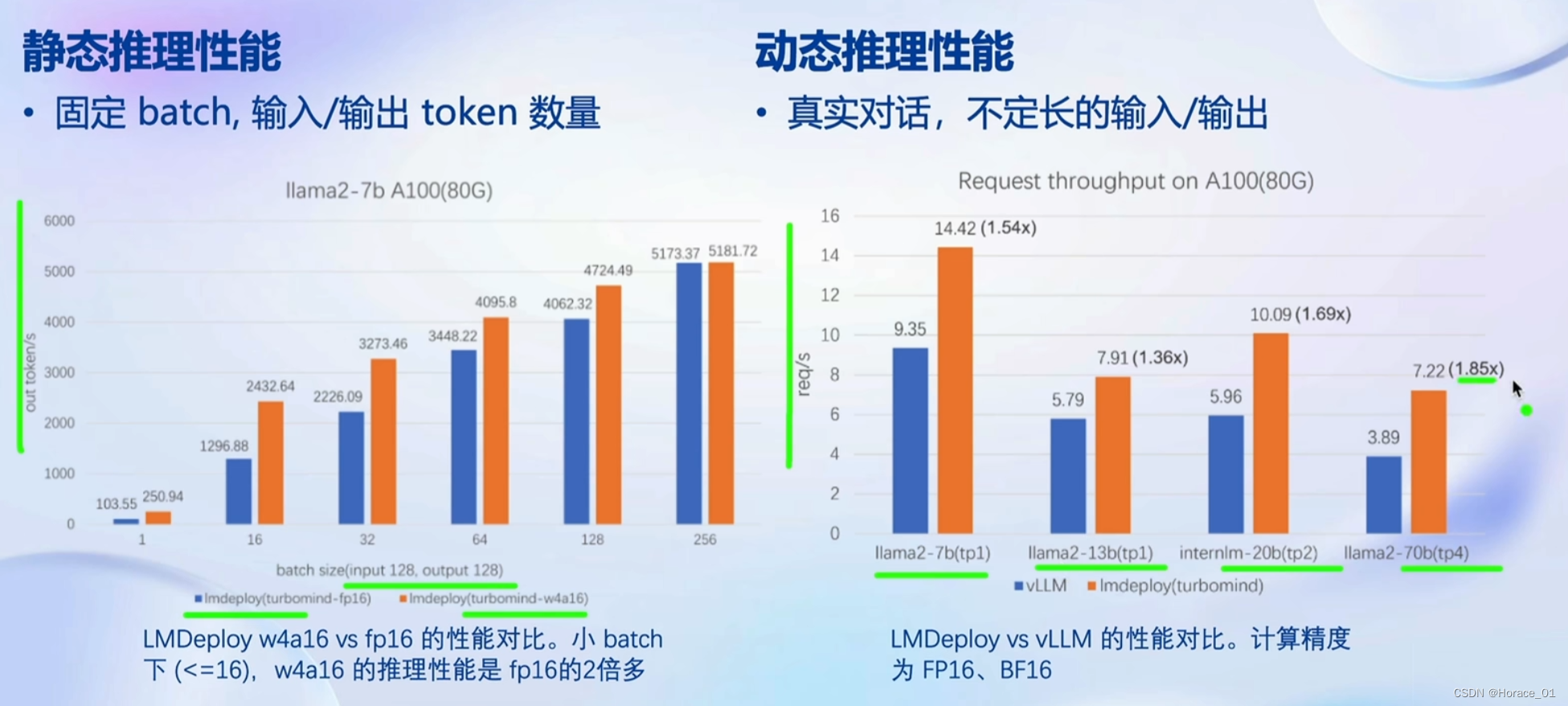
LMDeploy比vLLM的性能要好。
核心功能——量化

量化后,最大的输出长度变为原来的4倍。
为什么做Weight Only的量化?

LLM中存在两种密集场景:
1、计算密集:神经网络参数量大,前向一次要经过很多计算,这个我是理解的
2、访存密集:读取什么数据呢?这个我很疑惑,群里有大佬说是KV Cache的访存
大部分时候,LLM访存才是性能瓶颈的原因,而不是数值计算的时候。
为什么只做weight only的量化?一举多得
1、将FP16的模型权重量化为int4,访存量降为FP16的1/4,降低了访存成本,提高了decoding速度(不太理解具体的过程?)
2、节省了显存
如何做weight only的量化?
使用AWQ算法。
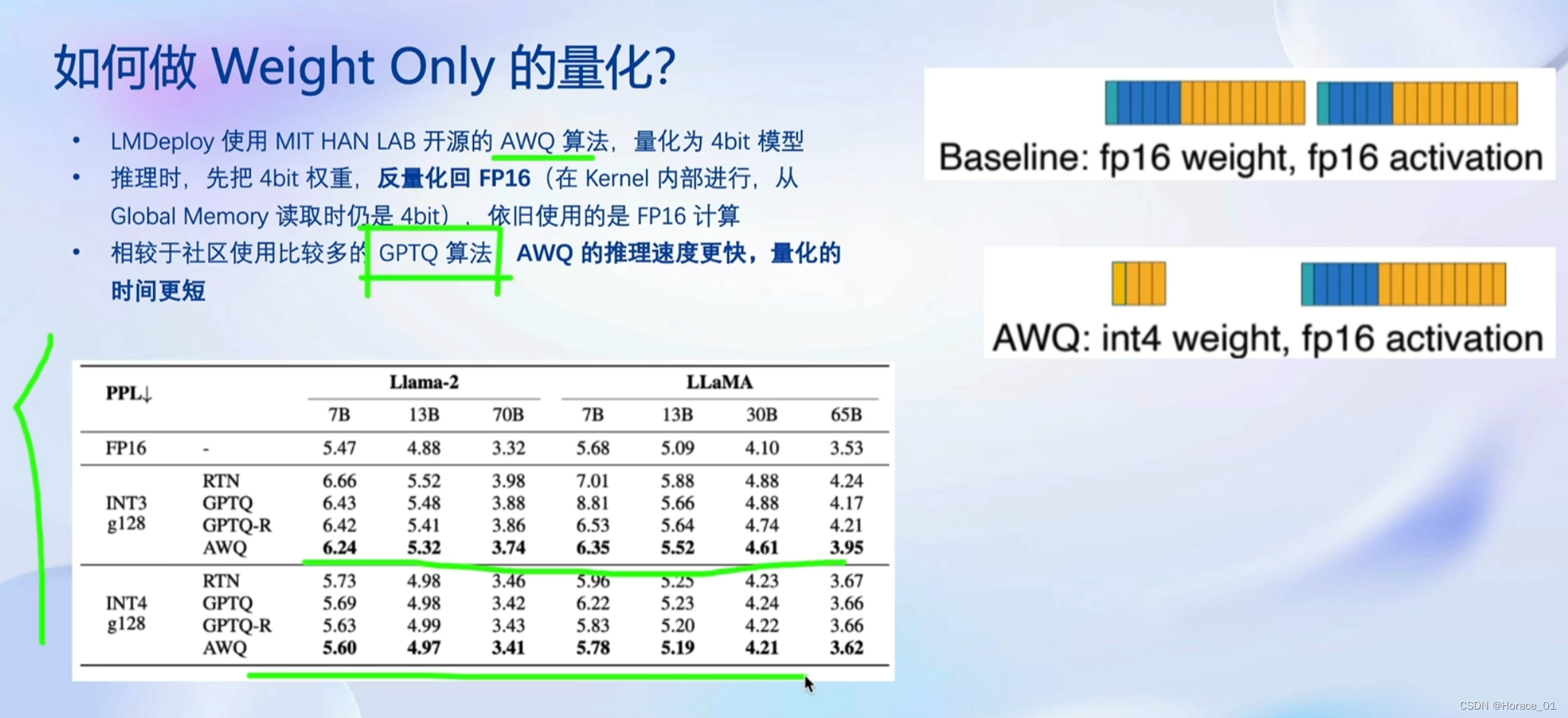
AWQ的思想:在矩阵计算中,有一部分参数是非常重要的,所以其他参数可以量化来降低精度。
推理引擎TurboMind
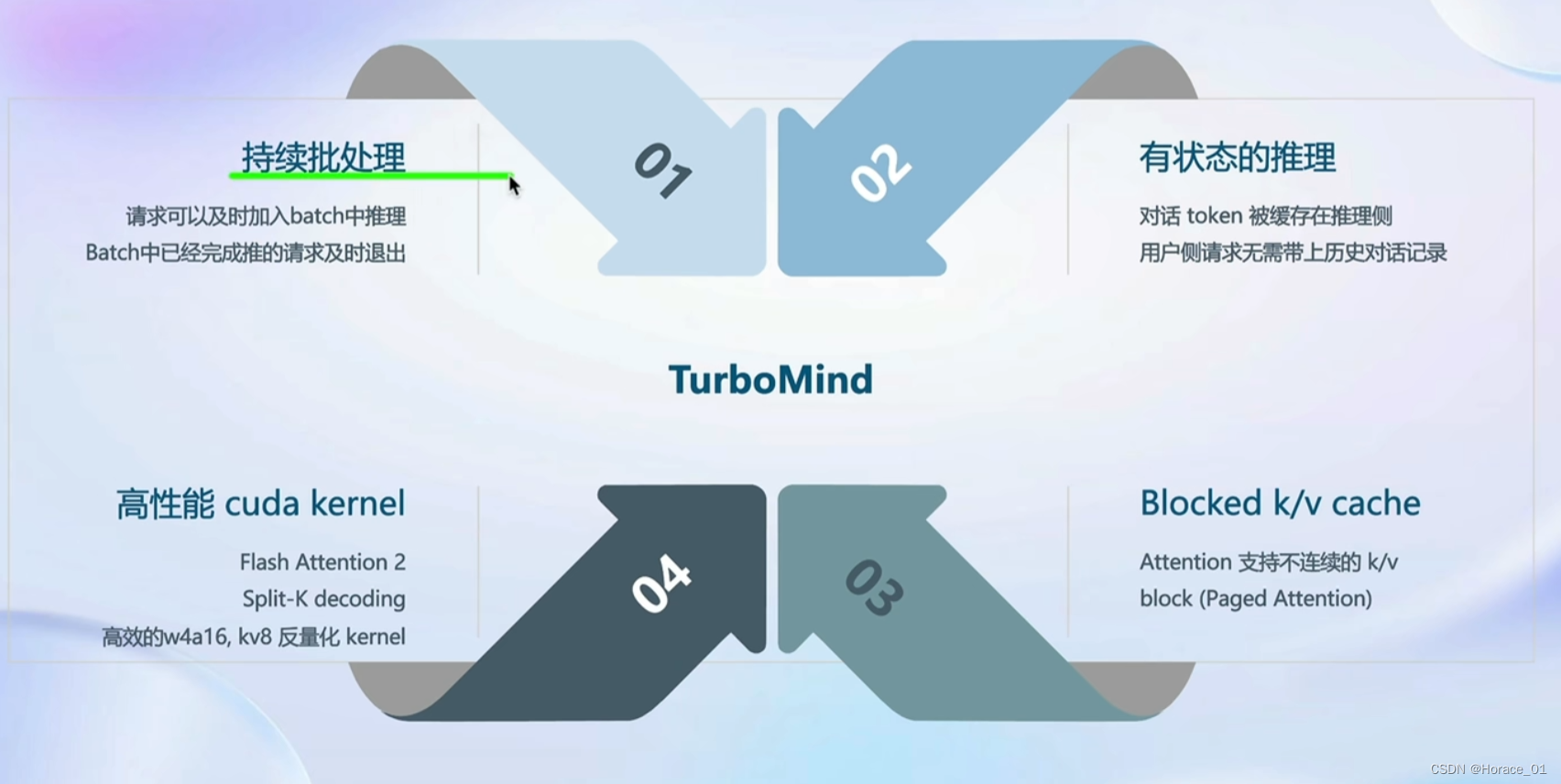
持续批处理
continuous batch
两个重要的概念:
1、请求队列
2、batch slot


流程:

有状态的推理

问的时候,历史消息放在模型推理处
blocked k/v cache
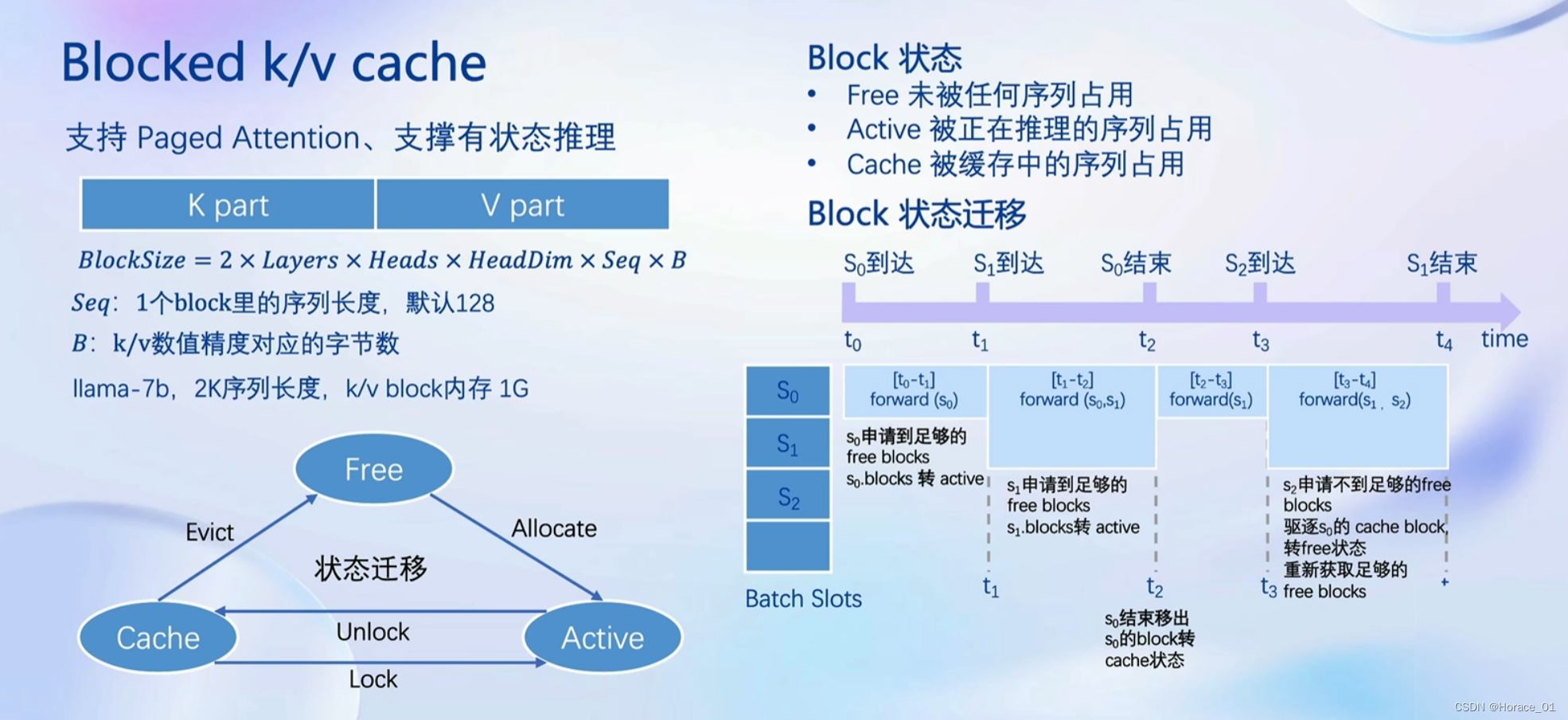
k、v是transformer里attention计算产生的东西。后面计算需要依赖于k,v。
blocked指的是分块。
只存当前使用的k,v。
高性能cuda kernel

flash attention、fast w4a16,kv8、split-k decoding、算子融合这四个东西都是为了加快token生成速度的。
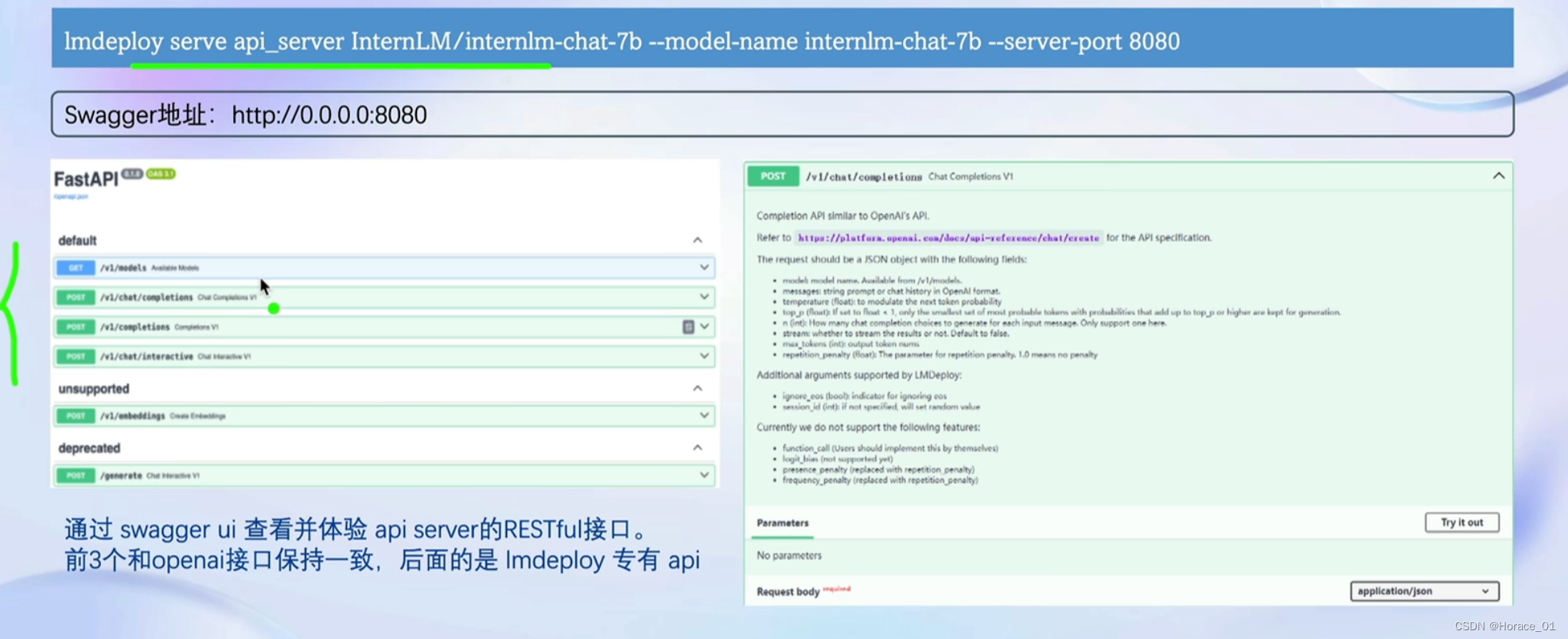
推理服务 api server
可以通过一个简单的命令,运行起一个服务
这篇关于【书生·浦语】大模型实战营——第五课笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





