本文主要是介绍还在为没有中文训练数据而头痛你的NLP任务吗?是时候看看这篇文章了~,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
编者:王小草
日期:2018年7月28日
今天俺要介绍的是一篇来自2018 ACL会议上的论文,属于语言表征上范畴,讲的是如何用无监督的方式进行跨语言的词嵌入表征。
1 背景知识
在介绍论文之前,善良的我先给大家介绍一下论文的背景知识。
1.1 什么是跨语言词嵌入?
英文:cross-lingual embedding
我们很熟知用word2vec(CBOW/Skip-grim)可以训练出有语义相似性的词嵌入向量,广泛应用于许多NLP任务,并取得了很好的效果。下图依次是在英文语料上独立训练的英文词嵌入,和在中文语料上独立训练的英文词嵌入。因为是在各自的语料上独立训练的,因此两个词嵌入矩阵在分布上也是独立不相关的。比如“happy”和“快乐”两个词的语义相同,但是他们的向量的相似性却为-0.052;同理“school”和“学校”的相似性为0.012,来自不同语言但含义相似的词几乎没有任何相关性。
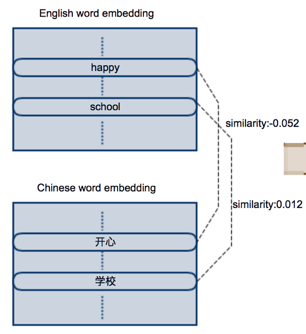
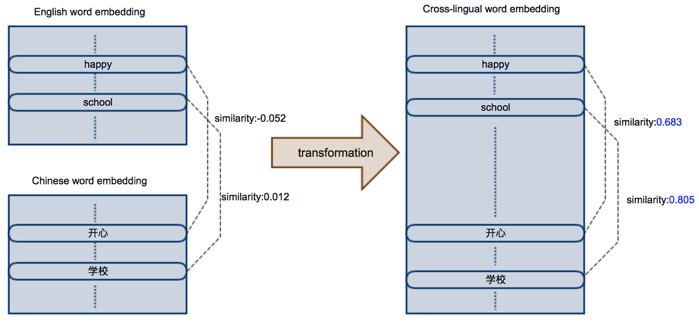
而跨语言词嵌入是指将不同语言独立训练的词向量,通过某种方式转换到同一个共享的空间中。在这个共享的空间中,即使是不同语言的词,只要具有相似含义,他们就有高的相似性。如下如,“happy”和“快乐”两个词在新的共享空间中,相似性为0.683;“school”和“学校”的相似性为0.805,体现了高的相似性。
1.2 为什么要进行跨语言词嵌入?
可以总结为3个好处:

其中第二点是至关重要的原因。因为目前英文语言的研究者多,公开的英文数据集也相对来说比其他语言更多。因此,当看到在英文上表现惊艳的模型时,发现因为缺少中文数据集,而无法迁移,总是苦之闷之,仰天捶胸。但是若可以将英文和中文的词都嵌入进相同的空间中,那么在英文上训练出来的模型,就可以直接应用在中文数据上了,简直痛之快之,伏案大笑。
1.3 如何进行跨语言词嵌入?
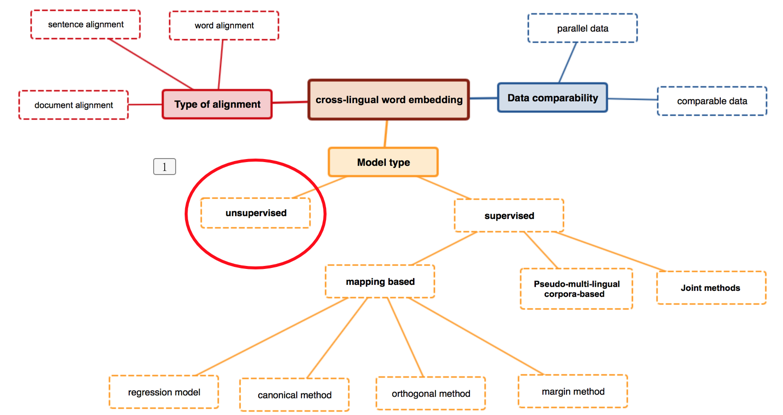
上图是跨语言词嵌入的几个研究方向。从训练数据上分可分为基于词对齐的,句子对齐的,以及文章对齐;或者是基于并行数据(如翻译对)或基于相似数据(如在pos上相似的词对)。从模型上分可以分为无监督和有监督。有监督的研究颇多,本文不详细介绍。无监督的模型是最近才兴起的,本文将着重介绍2018 ACL的一篇利用无监督算法进行跨语言词嵌入的文章。这篇文章的结果显示,无监督的模型不但取得了很好的成绩,还在大部分跨语言上超过了有监督的模型,这是喜之贺之。那么让我们带着激动的心情一起去看看作者到底是如何操作的呢?
2 数据准备与定义
2.1 准备独立语言的词嵌入矩阵
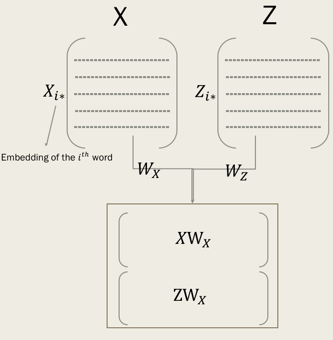
X X 与分别表示两类语言中独立训练好的词嵌入矩阵,需要自己先训练好的。
Xi∗ X i ∗ 与 Zi∗ Z i ∗ 表示在相应的词嵌入矩阵中的第i个词的词嵌入向量。
我们的目标是要学习 WX W X 和 WZ W Z 这两个转换矩阵(transformation metrices),从而使得 XWX X W X 和 ZWZ Z W Z 在同一个跨语言空间中。如下图:
2.2 定义词典
因为是无监督的,所以是不需要任何训练数据集的。但是我们得定义一个词典,这个词典的行是来自X语言的词(x1,x2,..xi,…);列是来自于Z语言的词(z1,z2,…,zi,…)。 Dij D i j =1,如果Z中的第j个词是X中的第i个词的翻译,否则 Dij D i j =0.
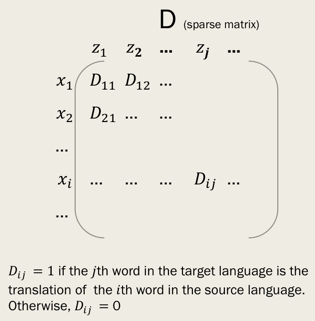
接下去,是两部重头戏:
1)通过X,Y两个独立的词嵌入矩阵去初始化字典D
2) 通过优化D,得到最优的 WX W X 和 WZ W Z
3 方法详解
3.1 词嵌入标准化
重头戏总是有铺垫颇多,先来看看文中对词嵌入矩阵进行标准化的方法,等下重头戏中要用到。
标准化的过程分为三步:
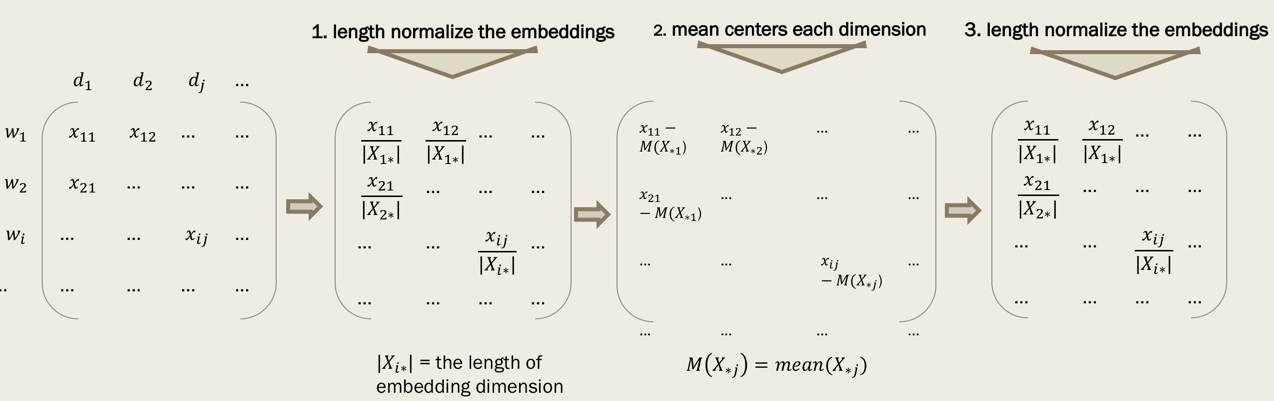
根据长度归一化词嵌入: Xi∗ X i ∗ / | Xi∗ X i ∗ |,即将每个词嵌入向量的维度上都除以嵌入向量的长度。
均值中心化每个维度:对类一列都减去该列的均值。
中心化之后再进行一次一模一样的长度归一化,确保最后输出的词向量是unit length的。
为啥要这样做呢?主要出于两个原因
1)0均值之后,向量之间的点乘就是这两个向量的余弦相似度,也等价于是欧氏距离,因此可以直接用来描述向量之间的相似性。(至于为什么这样标准化了之后就各种等价了呢,作者在他以前写的一篇文章中做了解释:【Learning principled bilingual mappings of word em- beddings while preserving monolingual invariance.】)
2)长度归一化之后,当进行奇异值分解的时候, XTDZ X T D Z = USVT U S V T , S就相当于是词向量的维度与维度之间的相似性矩阵。(后文求最优化的过程会用到奇异值分解)
3.2 完全无监督的初始化
3.2.1 初始化字典的困境
困境:
现在我们要用X和Y两个词嵌入矩阵去初始化词典D了。但是!因为 X X 与是两类语言独立训练出来的词嵌入矩阵,因此无论是他们的第i个词 Xi∗ X i ∗ 与
这篇关于还在为没有中文训练数据而头痛你的NLP任务吗?是时候看看这篇文章了~的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





