本文主要是介绍使用Colossal-AI云平台精调私有GPT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍
ChatGPT的出现展示了人工智能发展的潜力。通用数据集塑造的综合性大型语言模型在垂类领域中表现并不完美,存在幻想(AI Hallucination)等问题。要真正提升此类大语言模型在垂类领域的性能,应当使用高质量垂类数据集对模型进行精调。
目前,有大量企业客户想要将大模型能力融入日常业务,因而产生了对垂类大模型的迫切需求。大模型所能提供的快速有效地解决问题和生成回答的能力,可以帮助提高生产力并降低企业运营成本。然而,未经精调的大模型在企业特定场景下往往难以给出准确的回答,而准确性对企业用户而言又至关重要。因此,为了推动企业乃至行业的智能化和自动化,企业需要准确而专业的人工智能大模型来应对行业内的各项挑战。
通常而言,由于大模型的参数量和训练样本量巨大,训练一个精确的垂类大模型耗时较长,且需要熟练的工程团队和大量的计算资源。这些困难使得大模型训练成本极高,成为了企业利用大模型的主要障碍。
针对这一紧迫问题,我们革命性地创造了Colossal-AI平台,作为低成本训练大模型的解决方案。Colossal-AI平台融入了大量高性能计算和人工智能领域的先进技术与方案,以科技的力量助力大模型训练的降本增效,帮助企业以最低的成本达到最好的训练效果。
访问Colossal-AI平台:
https://platform.luchentech.com/
Colossal-AI 云平台
Colossal-AI平台是一个专业的深度学习训练云平台。它提供了强大的计算能力和模型加速支持,显著降低了模型训练成本,是训练深度学习大型模型的不二选择。

Colossal-AI 平台优势
在本教程中,我们将指导您使用我们的ColossalAI平台来训练或精调一个行业垂类的LLM。如果您感兴趣,请按照以下步骤,亲自体验从初始环境设置到模型最终部署的模型训练全流程。
我们将以使用医疗数据精调LLaMA-2模型为例,使其具备回答医疗问题的能力。若想将大模型用于其他领域,您只需要使用不同的数据集和训练代码来训练自己的大模型。我们还提供训练代码模板,可以满足基础的精调需求,进一步节省您的时间。
模型精调的简单步骤
要完成LLaMA-2模型精调过程,主要步骤如下:
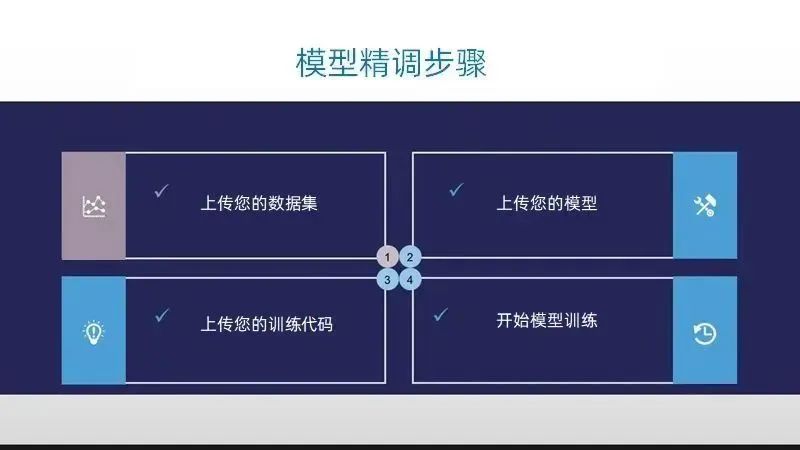
模型精调步骤
上传数据集
数据在影响模型性能方面起着至关重要的作用。选择数据需要慎重考虑。在网上有许多高质量的数据集可供使用,您也可以使用自己的数据集进行训练。
我们可以下载Hugging Face上的数据集。
我们选择 shibing624/medical 中的 英文数据集。
shibing624/medical :
https://huggingface.co/datasets/shibing624/medical
英文数据集:
https://huggingface.co/datasets/shibing624/medical/blob/main/finetune/train_en_1.json
可以使用如下指令下载:
wget https://huggingface.co/datasets/shibing624/medical/resolve/main/finetune/train_en_1.json
下载完之后,我们需要执行下面的Python脚本预处理数据集。
| Python |
我们提供了一个用于数据处理的Python脚本范例。您也可以使用自己的代码。
| Python |

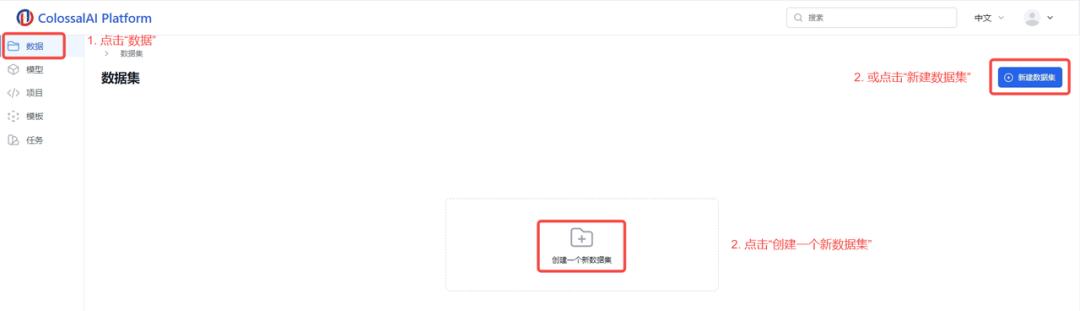
预处理后,您可以将您的数据集上传到Colossal-AI云平台,请按照图中所示的5个步骤进行操作:
1.点击左侧菜单栏中的“数据”
2.点击“创建一个新数据集”或“新建数据集”按钮
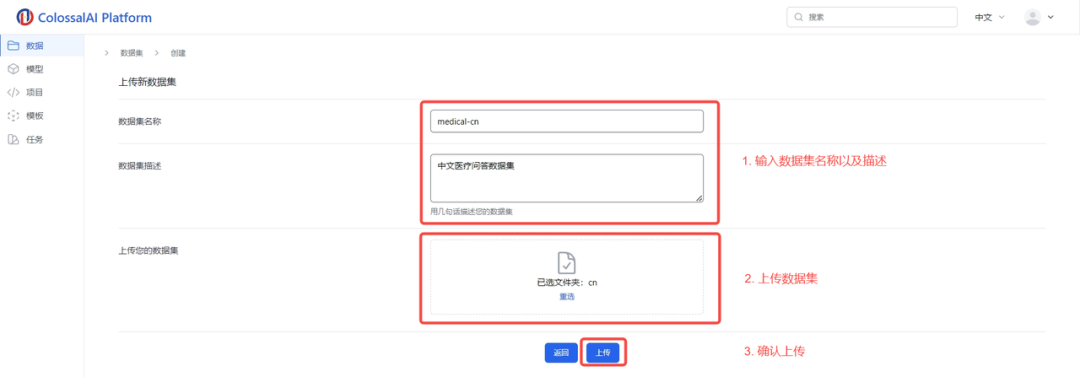
3.输入您的数据集名称以及描述
4.选择数据集文件夹
5.确认上传
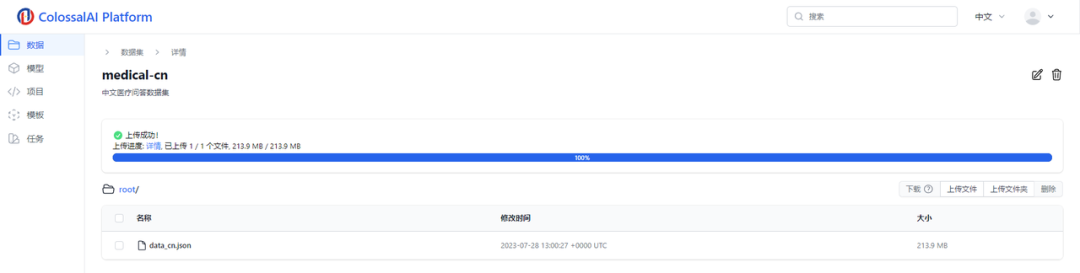
完成这些步骤后,您可以在Colossal-AI云平台上查看已上传的数据集。
上传你的模型
接下来,您需要在进行训练之前上传模型。对于精调工作(例如此示例),您需要上传一个预训练模型。我们目前在平台上存储了一些预训练模型,如Bloom、GPT和LLaMA。您可以直接使用这些模型而无需上传它们。如果您想使用其他模型,可以按照以下步骤上传自定义模型:

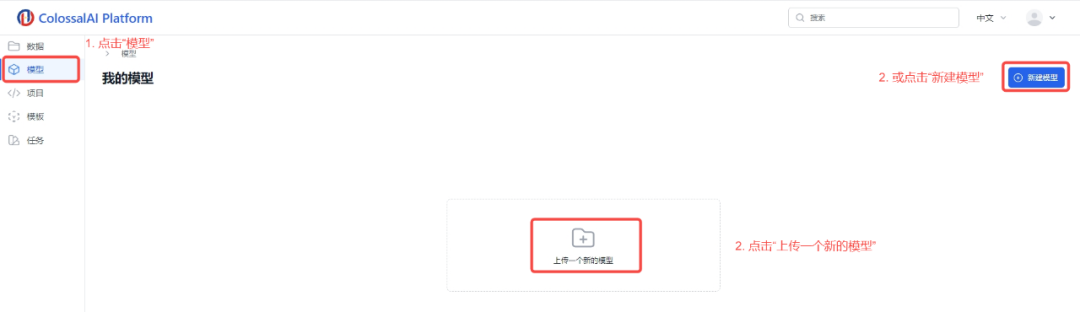
1.点击左侧菜单栏中的“模型”
2.点击“上传一个新的模型”或“新建模型”按钮
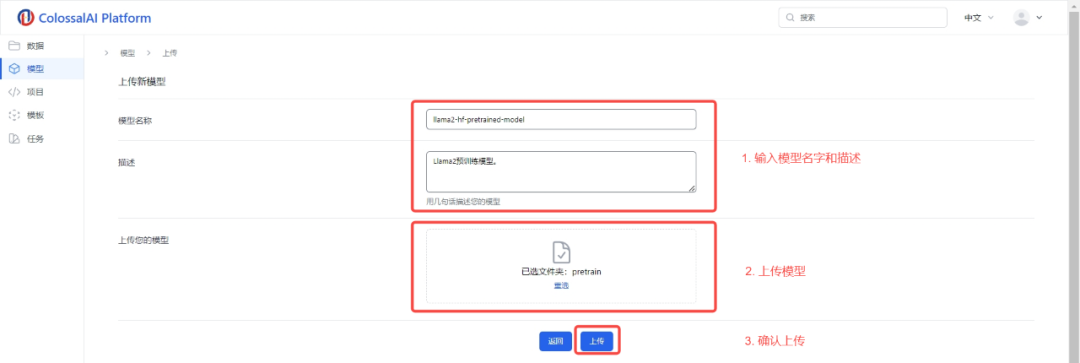
3.输入您的模型名称和描述
4.选择模型文件夹
5.确认上传
您将在文件夹中找到您上传的模型。

上传训练脚本
上传模型后,下一步就是上传训练代码。您可以选择使用自己的训练代码,也可以使用我们提供的训练模板,只需要稍作修改即可满足您的需求。

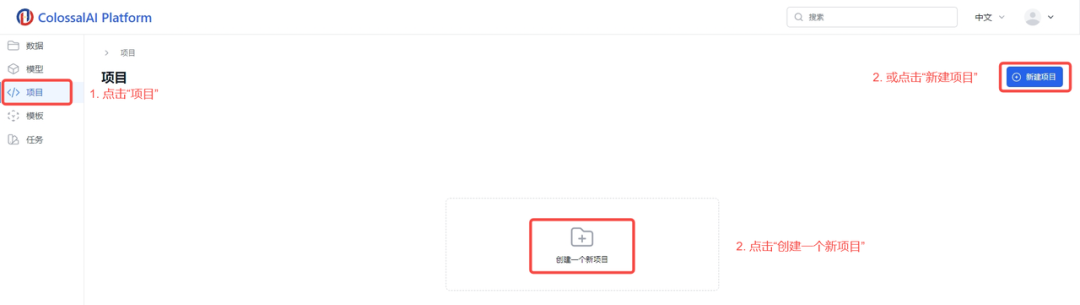
1.点击左侧菜单栏中的“项目”
2.点击“创建一个新项目”或“新建模型”按钮
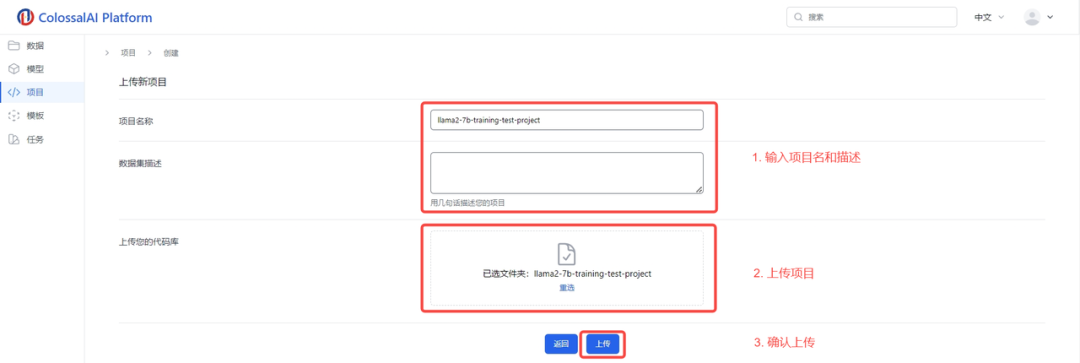
3.输入您的项目名称和描述
4.上传项目
5.确认上传
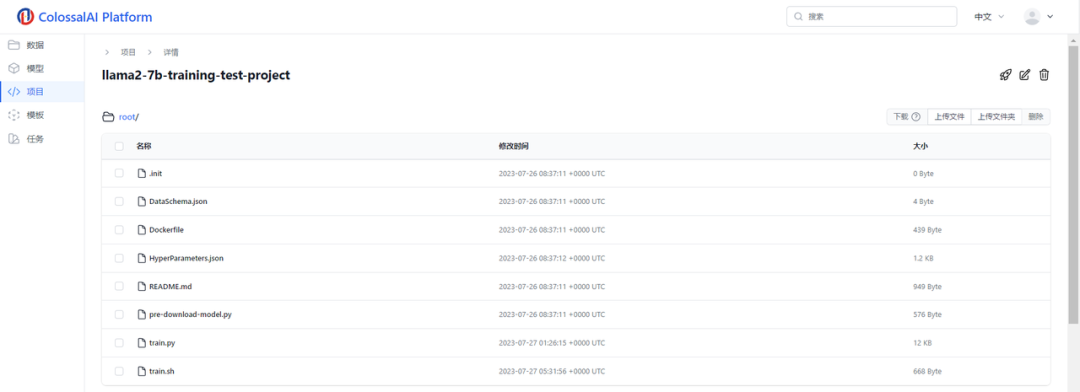
开始训练任务
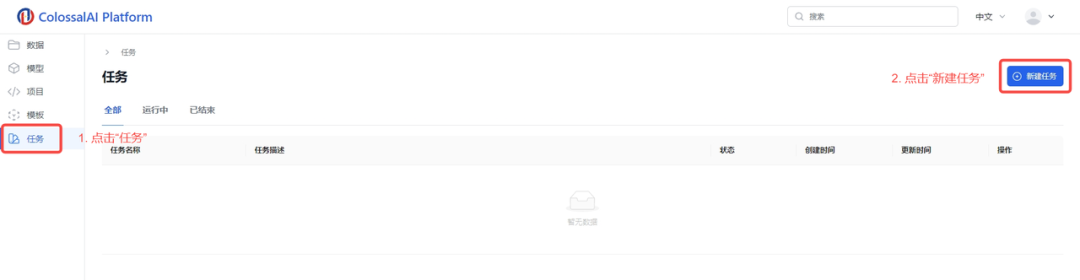
完成上述准备工作后,您可以开始训练模型。只需启动任务并填写您的超参数,您可以按照下图所示步骤操作:

1.点击”任务“
2.输入任务名称和描述
3.选择项目
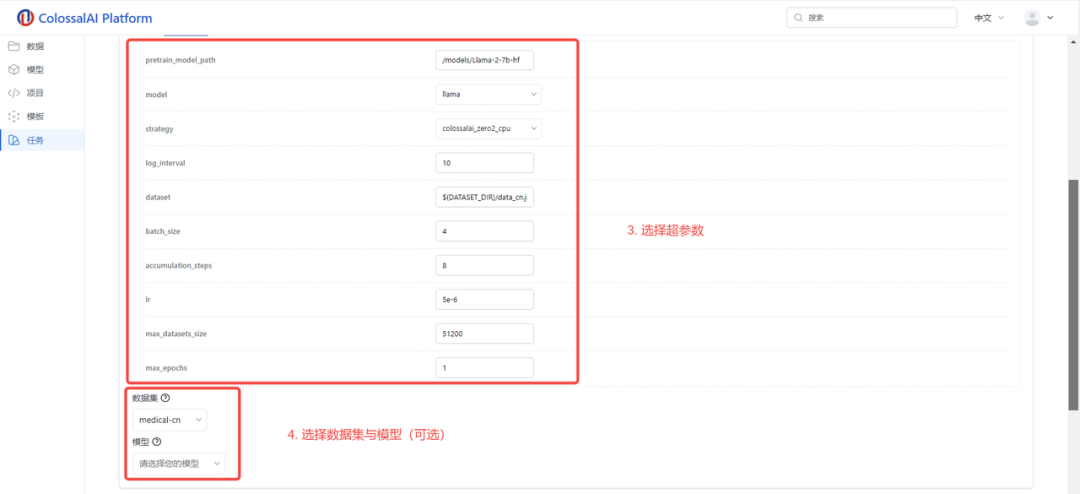
4.选择超参数
5.选择数据集与模型(可选)
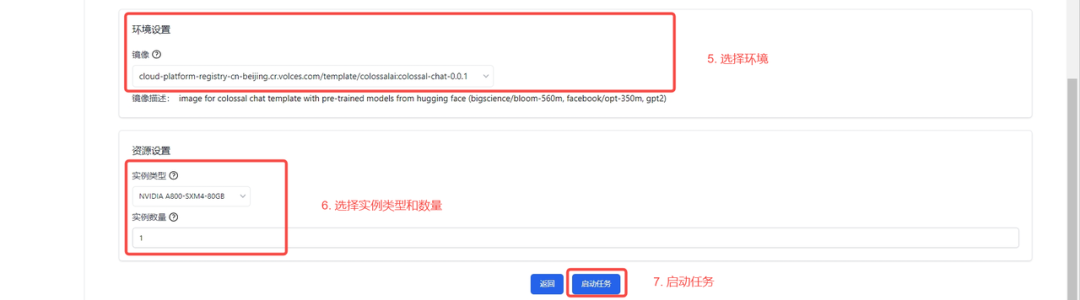
6.选择环境
7.选择实例类型和数量
8.启动任务

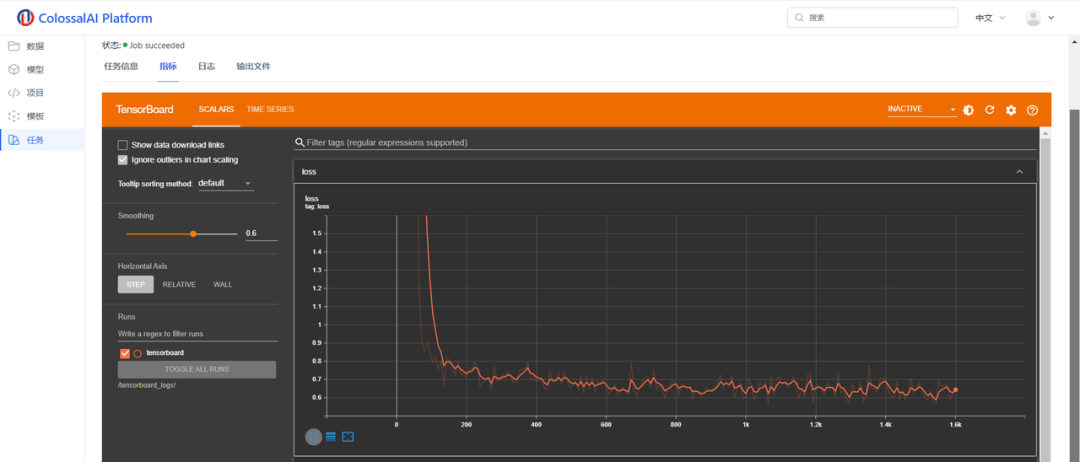
然后你可以看到loss曲线和保存好的模型权重。
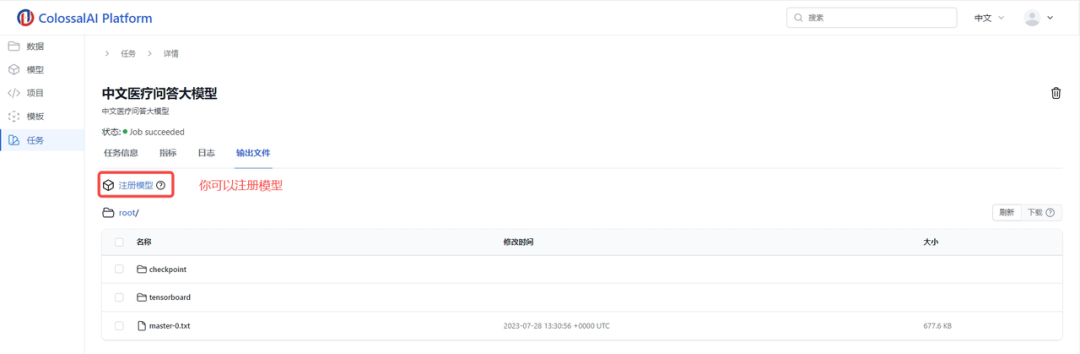
你可以注册模型,然后在我们的Colossal-AI云平台上进行推理。
推理
Colossal-AI云平台提供了多种并行加速方法和针对特定推理任务量身定制的优化解决方案。这些优化措施可以显著提高模型的推理速度,同时减少内存使用。因此,当您在本地部署和使用模型时,您会发现硬件需求大大降低,从而整体改善用户体验。
按照上面概述的步骤,您可以顺利上传您的推理项目并启动一个任务。
以下是推理结果:

在本示例精调完成后,经过训练的模型变得擅长处理医疗问题并为患者提供有价值的建议。在实际推理场景中,假设一个患者出现膝盖疼痛的情况。该模型可以迅速深入了解关节疼痛和僵硬的潜在原因,同时建议进行相关的诊断测试,以查明潜在问题。此外,它还提供了对不同测试相关风险的见解,例如强调滑液培养可以帮助确定确切的原因,但可能涉及一些侵入性操作。
总之,在重新训练后,该模型在处理与医疗相关的查询方面表现出色,提供及时有效的响应。这一成功突显了利用人工智能支持和增强医疗咨询领域的潜力,标志着人工智能在医疗保健领域的应用迈出了重要一步。
结语
总之,Colossal-AI云平台重新定义了大型AI模型训练的领域,使复杂的模型训练变得简单。使用Colossal-AI云平台,无需繁琐的环境配置或深入研究复杂的加速方法——您只需点击几下即可实现模型训练显著的加速。最快短短3天内,您就可以拥有自己经过精调的大型模型。除此之外,您的所有数据都将保持私有,Colossal-AI云平台采用了强大的加密措施来保护您的信息。
Colossal-AI云平台致力于降低模型训练成本,并最大化模型训练效率。我们也很注重保护用户信息的安全和隐私,让您无忧训练大模型。
我们向企业和个人发出公开邀请,欢迎您使用Colossal-AI云平台,踏上探索AI之旅,我们会为您带来无与伦比的丝滑体验。平台提供低价A800/H800/H100等算力,结合Colossal-AI降本增效能力,可有效降低大模型训练部署成本。平台目前开放免费内测,填写链接即可参与
https://wj.qq.com/s2/12833857/176a/
这篇关于使用Colossal-AI云平台精调私有GPT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





