本文主要是介绍对卷积神经网络、池化层、反卷积以及Text-CNN原理的理解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天,我们来讨论一下卷积,以及卷积神经网络,这里边具体怎么运算的,请看下面分析:
首先选取知乎上对卷积物理意义解答排名最靠前的回答。 然后再来看分析卷积神经网络
1、卷积
来自知乎的优秀回答!
不推荐用“反转/翻转/反褶/对称”等解释卷积。好好的信号为什么要翻转?导致学生难以理解卷积的物理意义。
这个其实非常简单的概念,国内的大多数教材却没有讲透。
卷积是分析数学中一种重要的运算。设: f(x)、 g(x)是R 上的两个可积函数,作积分:
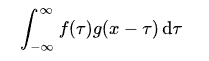
直接看图,不信看不懂。以离散信号为例,连续信号同理。
已知x[0] = a, x[1] = b, x[2]=c
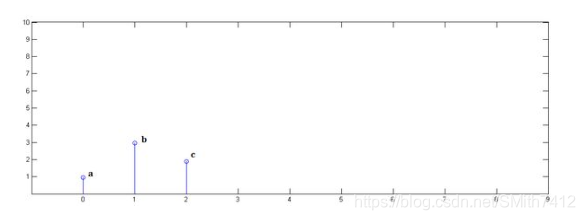
已知y[0] = i, y[1] = j, y[2]=k
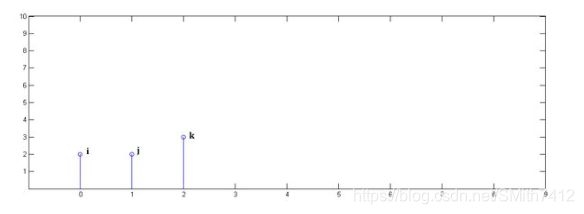
下面通过演示求x[n] * y[n]的过程,揭示卷积的物理意义。
第一步,x[n]乘以y[0]并平移到位置0
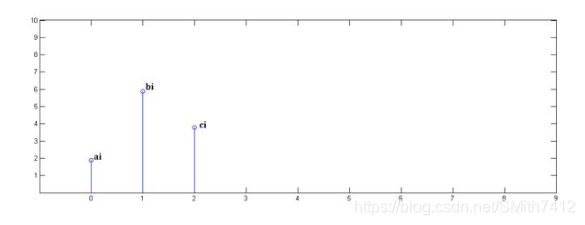
第二步,x[n]乘以y[1]并平移到位置1:
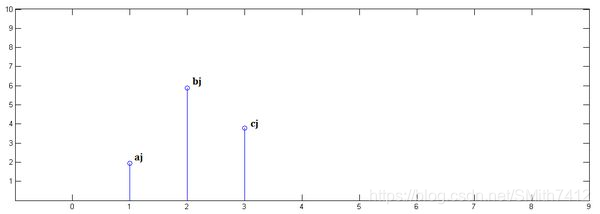
第三步,x[n]乘以y[2]并平移到位置2:

最后,把上面三个图叠加,就得到了x[n] * y[n]:
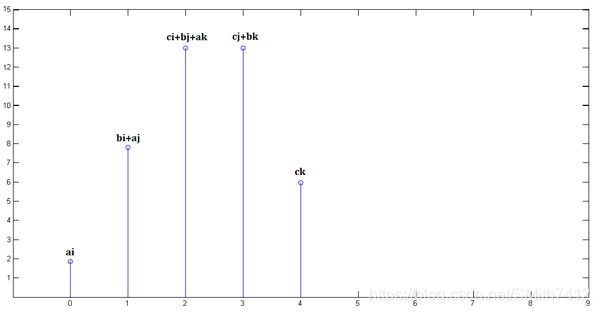
从这里,可以看到卷积的重要的物理意义是:一个函数(如:单位响应)在另一个函数(如:输入信号)上的加权叠加。重复一遍,这就是卷积的意义:加权叠加。对于线性时不变系统,如果知道该系统的单位响应,那么将单位响应和输入信号求卷积,就相当于把输入信号的各个时间点的单位响应 加权叠加,就直接得到了输出信号。
通俗的说:在输入信号的每个位置,叠加一个单位响应,就得到了输出信号。这正是单位响应是如此重要的原因。
2、卷积神经网络
原文参考:http://www.jeyzhang.com/cnn-learning-notes-1.html
概述
卷积神经网络(Convolutional Neural Network, CNN)是深度学习技术中极具代表的网络结构之一,在图像处理领域取得了很大的成功,在国际标准的ImageNet数据集上,许多成功的模型都是基于CNN的。CNN相较于传统的图像处理算法的优点之一在于,避免了对图像复杂的前期预处理过程(提取人工特征等),可以直接输入原始图像。
图像处理中,往往会将图像看成是一个或多个的二维向量,如之前博文中提到的MNIST手写体图片就可以看做是一个28 × 28的二维向量(黑白图片,只有一个颜色通道;如果是RGB表示的彩色图片则有三个颜色通道,可表示为三张二维向量)。传统的神经网络都是采用全连接的方式,即输入层到隐藏层的神经元都是全部连接的,这样做将导致参数量巨大,使得网络训练耗时甚至难以训练,而CNN则通过局部连接、权值共享等方法避免这一困难,有趣的是,这些方法都是受到现代生物神经网络相关研究的启发(感兴趣可阅读以下部分)。

下面重点介绍下CNN中的局部连接(Sparse Connectivity)和权值共享(Shared Weights)方法,理解它们很重要。
2.1 局部连接与权值共享
下图是一个很经典的图示,左边是全连接,右边是局部连接。
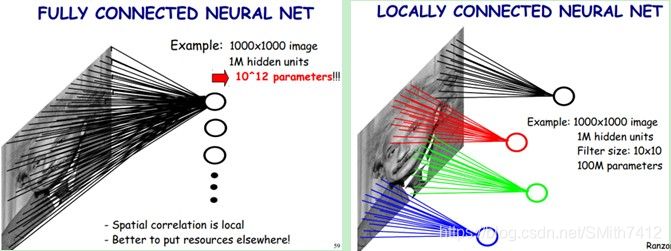
对于一个1000 × 1000的输入图像而言,如果下一个隐藏层的神经元数目为10^6个,采用全连接则有1000 × 1000 × 10^6 = 10^12个权值参数,如此数目巨大的参数几乎难以训练;而采用局部连接,隐藏层的每个神经元仅与图像中10 × 10的局部图像相连接,那么此时的权值参数数量为10 × 10 × 10^6 = 10^8,将直接减少4个数量级。
尽管减少了几个数量级,但参数数量依然较多。能不能再进一步减少呢?能!方法就是权值共享。具体做法是,在局部连接中隐藏层的每一个神经元连接的是一个10 × 10的局部图像,因此有10 × 10个权值参数,将这10 × 10个权值参数共享给剩下的神经元,也就是说隐藏层中10^6个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10 × 10个权值参数(也就是卷积核(也称滤波器)的大小),如下图。

这大概就是CNN的一个神奇之处,尽管只有这么少的参数,依旧有出色的性能。但是,这样仅提取了图像的一种特征,如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像的不同映射下的特征,称之为Feature Map。如果有100个卷积核,最终的权值参数也仅为100 × 100 = 10^4个而已。另外,偏置参数也是共享的,同一种滤波器共享一个。
卷积神经网络的核心思想是:局部感受野(local field),权值共享以及时间或空间亚采样这三种思想结合起来,获得了某种程度的位移、尺度、形变不变性(?不够理解透彻?)。
2.2 网络结构
下图是一个经典的CNN结构,称为LeNet-5网络。
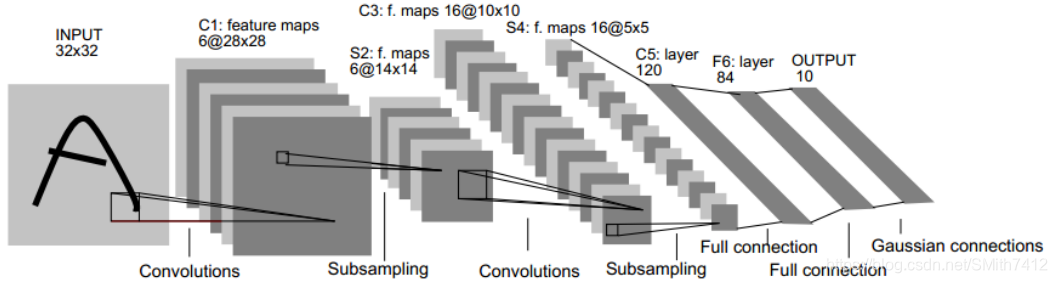
2.3 卷积层
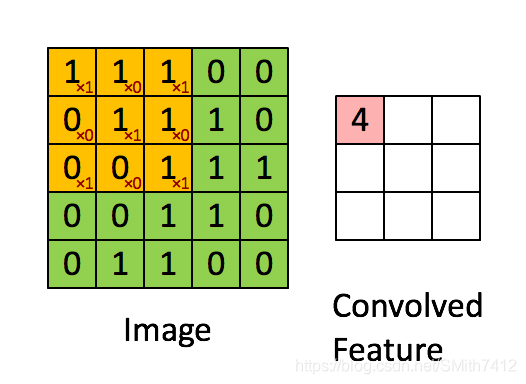
卷积层是卷积核在上一级输入层上通过逐一滑动窗口计算而得,卷积核中的每一个参数都相当于传统神经网络中的权值参数,与对应的局部像素相连接,将卷积核的各个参数与对应的局部像素值相乘之和,(通常还要再加上一个偏置参数),得到卷积层上的结果。如下图所示。
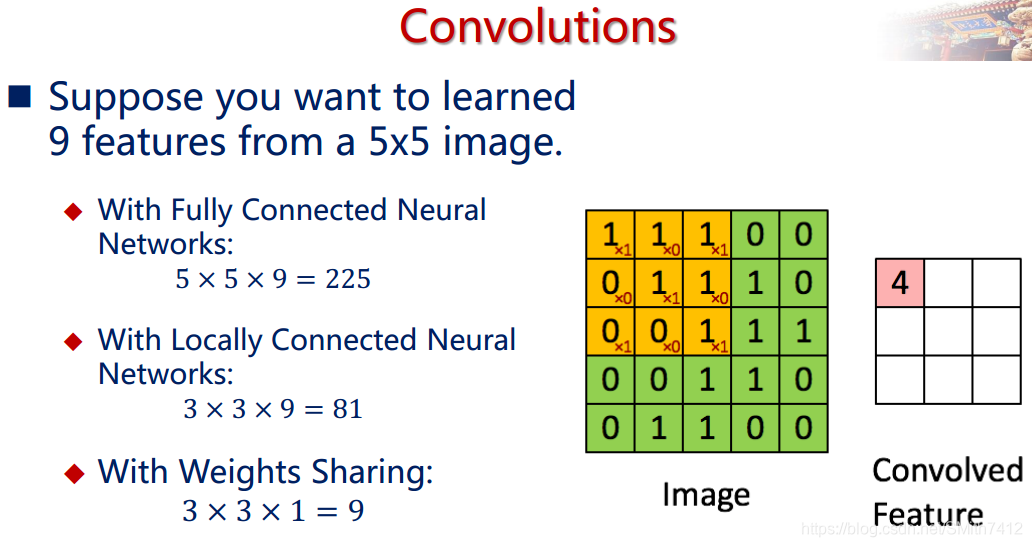
下面的动图能够更好地解释卷积过程:
2.4 池化/采样层
通过卷积层获得了图像的特征之后,理论上我们可以直接使用这些特征训练分类器(如softmax),但是这样做将面临巨大的计算量的挑战,而且容易产生过拟合的现象。为了进一步降低网络训练参数及模型的过拟合程度,我们对卷积层进行池化/采样(Pooling)处理。池化/采样的方式通常有以下两种:
1、Max-Pooling: 选择Pooling窗口中的最大值作为采样值;
2、Mean-Pooling: 将Pooling窗口中的所有值相加取平均,以平均值作为采样值
如下图所示。

2.5 LeNet-5网络详解
以上较详细地介绍了CNN的网络结构和基本原理,下面介绍一个经典的CNN模型:LeNet-5网络。
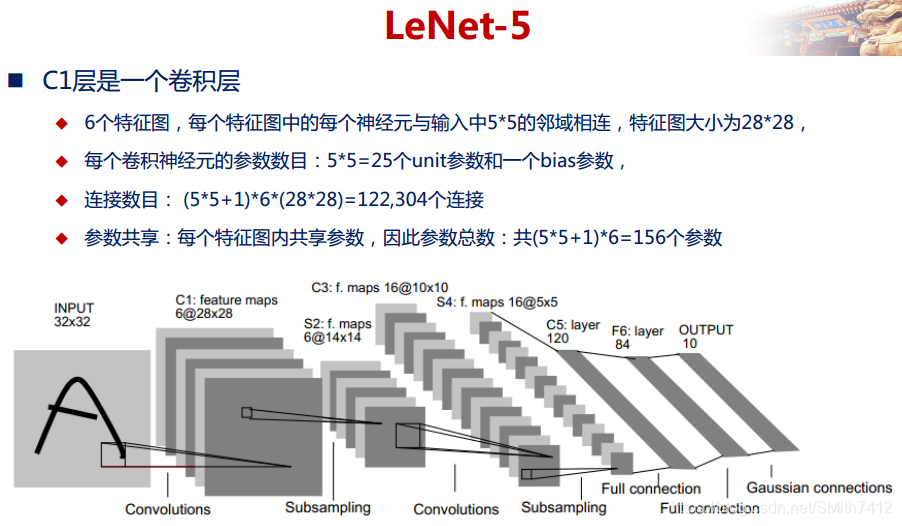
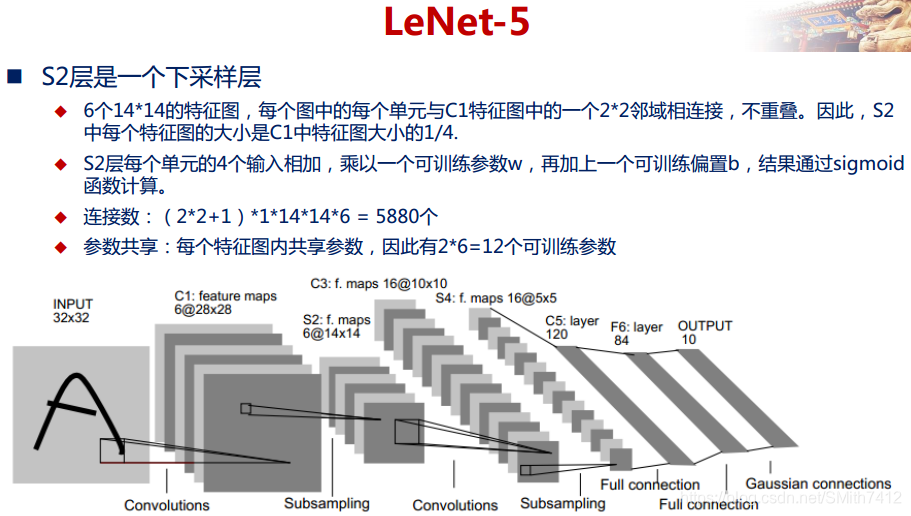
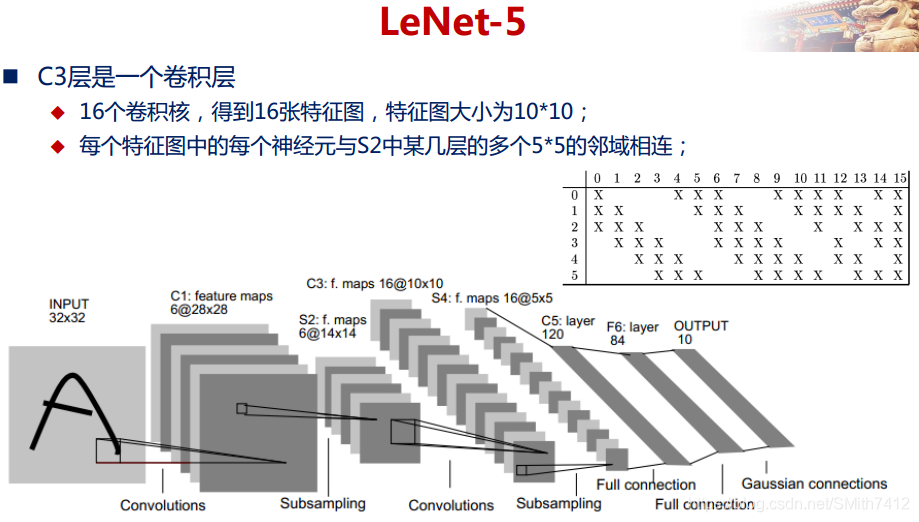
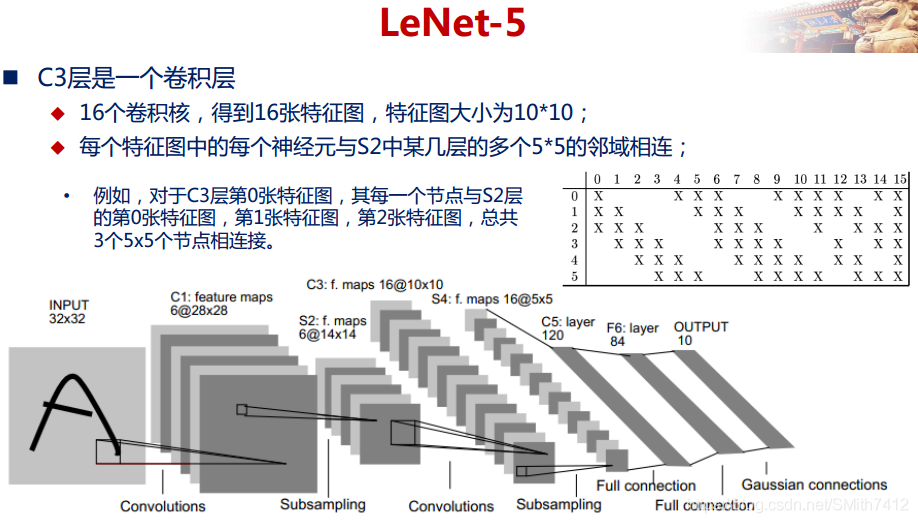
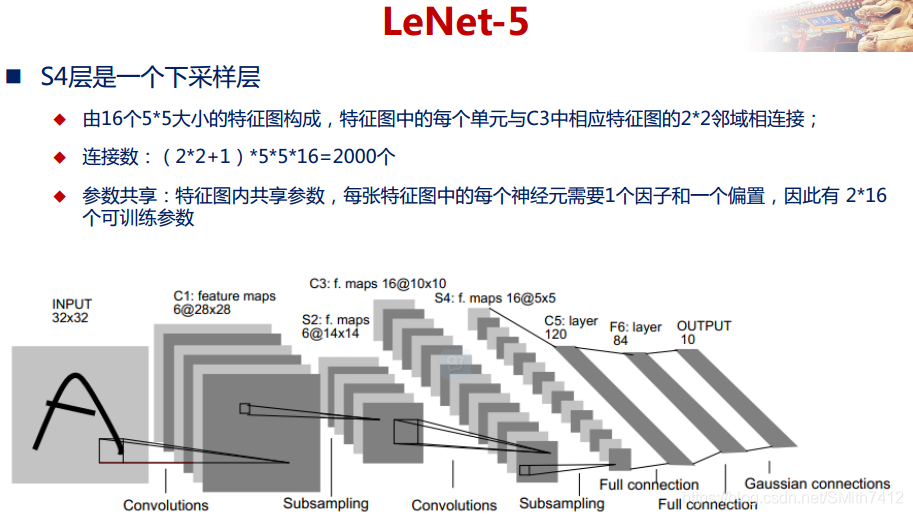
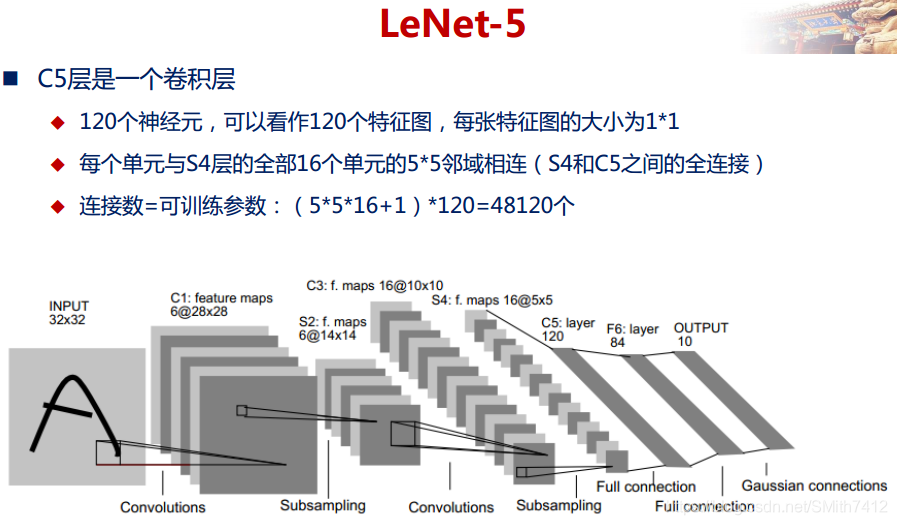
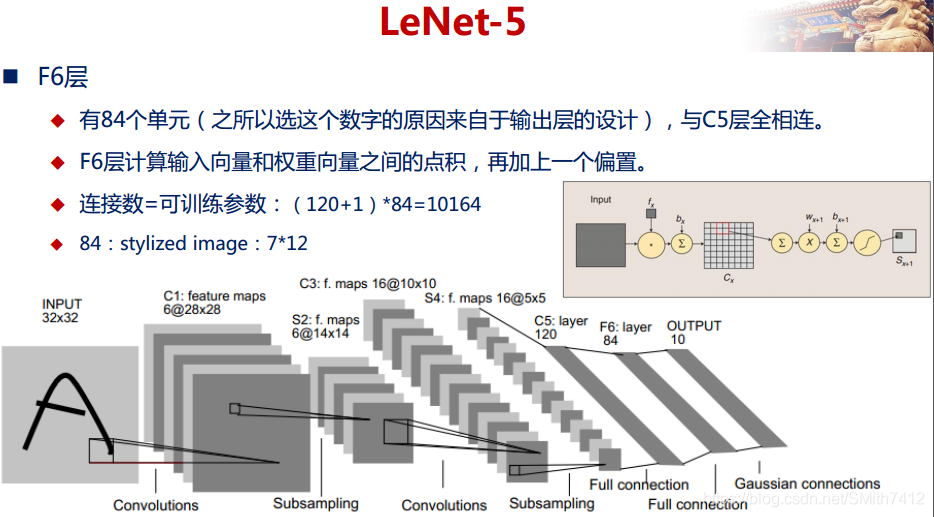
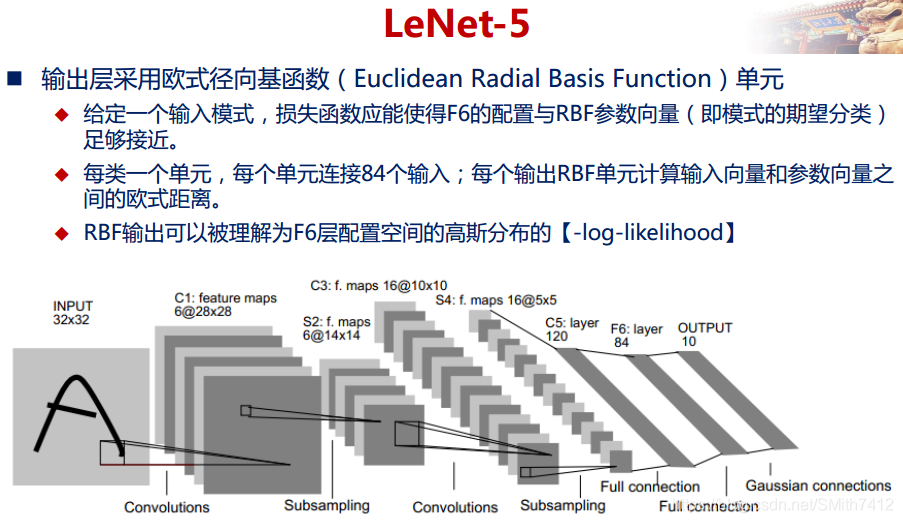
LeNet-5网络在MNIST数据集上的结果

3 池化层和padding的理解
3.1 池化层的理解
参考来源:https://www.cnblogs.com/eilearn/p/9282902.html
pooling池化的作用则体现在降采样:保留显著特征、降低特征维度,增大kernel的感受野。另外一点值得注意:pooling也可以提供一些旋转不变性。
池化层可对提取到的特征信息进行降维,一方面使特征图变小,简化网络计算复杂度并在一定程度上避免过拟合的出现;一方面进行特征压缩,提取主要特征。
最大池采样在计算机视觉中的价值体现在两个方面:(1)、它减小了来自上层隐藏层的计算复杂度;(2)、这些池化单元具有平移不变性,即使图像有小的位移,提取到的特征依然会保持不变。由于增强了对位移的鲁棒性,这样可以忽略目标的倾斜、旋转之类的相对位置的变化,以此提高精度,最大池采样方法是一个高效的降低数据维度的采样方法。
需要注意的是:这里的pooling操作是特征图缩小,有可能影响网络的准确度,因此可以通过增加特征图的深度来弥补(这里的深度变为原来的2倍)。
在CNN网络中卷积池之后会跟上一个池化层,池化层的作用是提取局部均值与最大值,根据计算出来的值不一样就分为均值池化层与最大值池化层,一般常见的多为最大值池化层。池化的时候同样需要提供filter的大小、步长。
tf.nn.max_pool(value, ksize, strides, padding, name=None)
参数是四个,和卷积很类似:
第一个参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape
第二个参数ksize:池化窗口的大小,取一个四维向量,一般是[1, height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为了1
第三个参数strides:和卷积类似,窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1]
第四个参数padding:和卷积类似,可以取’VALID’ 或者’SAME’
返回一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式
举例:池化输出特征图计算和卷积计算公式相同,区别是池化是求卷积区域中的max,不涉及卷积计算。
(1)pooling(kernel size 2×2,padding 0,stride 2) 323216->pooling之后(32-2+0)/2 + 1 =16*16
pool3 = tf.nn.max_pool(layer3,[1,2,2,1],[1,2,2,1],padding=‘SAME’) // p = (f-1)/2=(2-1)/2=0,所以padding='SAME’或“VALID”输出一样
(2)pooling(kernel size 3×3,padding 0,stride 1) 323216->pooling之后(32-3+0)/1 + 1 = 30*30
pool3 = tf.nn.max_pool(layer3,[1,3,3,1],[1,1,1,1])
3.2 padding的理解
之前在讨论卷积神经网络的时候,我们是使用filter来做元素乘法运算来完成卷积运算的。目的是为了完成探测垂直边缘这种特征。但这样做会带来两个问题。
卷积运算后,输出图片尺寸缩小;
越是边缘的像素点,对于输出的影响越小,因为卷积运算在移动的时候到边缘就结束了。中间的像素点有可能会参与多次计算,但是边缘像素点可能只参与一次。所以我们的结果可能会丢失边缘信息。
那么为了解决这个问题,我们引入padding, 什么是padding呢,就是我们认为的扩充图片, 在图片外围补充一些像素点,把这些像素点初始化为0.
padding的用途:
(1)保持边界信息,如果没有加padding的话,输入图片最边缘的像素点信息只会被卷积核操作一次,但是图像中间的像素点会被扫描到很多遍,那么就会在一定程度上降低边界信息的参考程度,但是在加入padding之后,在实际处理过程中就会从新的边界进行操作,就从一定程度上解决了这个问题。
(2)可以利用padding对输入尺寸有差异图片进行补齐,使得输入图片尺寸一致。
(3)卷积神经网络的卷积层加入Padding,可以使得卷积层的输入维度和输出维度一致。
(4)卷积神经网络的池化层加入Padding,一般都是保持边界信息和(1)所述一样。
padding模式:SAME和VALID
SAME:是填充,填充大小, p = (f-1)/2;VALID:是不填充,直接计算输出。
3.3 池化层的公式计算
输入数据维度为W*W
Filter大小 F×F
步长 S
padding的像素数 P
可以得出
N = (W − F + 2P )/S+1
输出大小为 N×N
4.反卷积
前面已经介绍了卷积是如何运算的,接下来介绍反卷积。
卷积可以转化为一副图像与一个矩阵C的乘积。
反卷积(转置卷积)只是正向时左乘CT,而反向时左乘(CT)^T。
知乎上的高票答案:https://www.zhihu.com/question/43609045
动态图片:https://github.com/vdumoulin/conv_arithmetic
5.Text-CNN的原理
1.简介
TextCNN 是利用卷积神经网络对文本进行分类的算法,由 Yoon Kim 在 “Convolutional Neural Networks for Sentence Classification” 一文 中提出. 是2014年的算法.
文章:https://arxiv.org/pdf/1408.5882.pdf
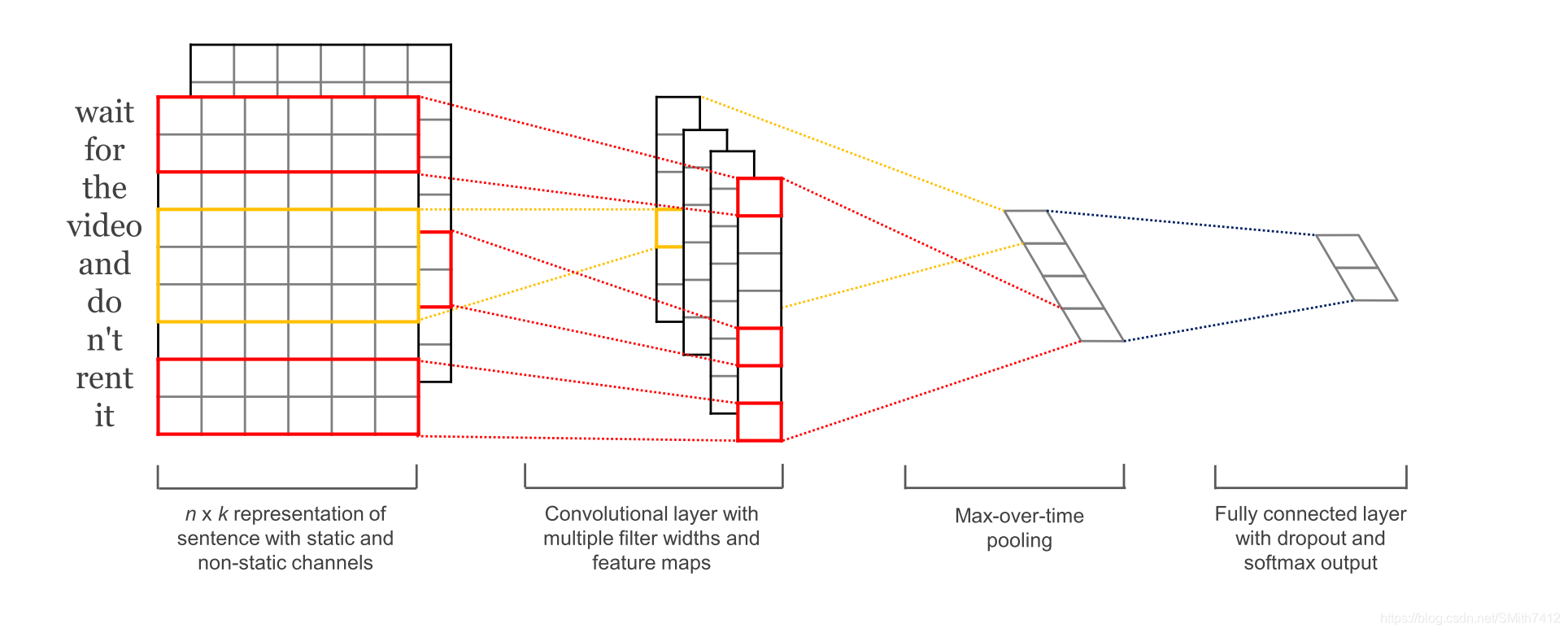
详细大家请点击这里,总结的很好!
此外,也对于卷积网络,大家也可以参考:
https://blog.csdn.net/v_july_v/article/details/51812459
这篇关于对卷积神经网络、池化层、反卷积以及Text-CNN原理的理解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






