本文主要是介绍【金猿人物展】DataPipelineCEO陈诚:赋能数据应用,发挥未来生产力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

陈诚
本文由DataPipelineCEO陈诚撰写并投递参与“数据猿年度金猿策划活动——2023大数据产业年度趋势人物榜单及奖项”评选。

大数据产业创新服务媒体
——聚焦数据 · 改变商业
我们处在一个“见证奇迹”的时代。在过去的20年间,我们见证了大数据技术快速发展所带来的巨大改变。如今我们看到,以大数据为基础的智能时代已然来临,这将为全球信息技术带来前所未有的机遇和挑战,促成未来生产力的爆发。但从行业实际应用的角度出发,如何释放企业积累和持续产生的大量数据价值,使其成为撬动未来生产力的支点,实现业务和效率的双重提升,是迈向新征程的重中之重。
实时数据+AIGC有望开辟新的维度
随着AI时代的到来,数据的增长呈现上升趋势,包括直接获得的数据、通过业务系统或机器数据捕获的数据以及由AI模型生成的数据。这些数据对于企业感知用户需求、优化体验和决策至关重要。尽管AIGC技术的创新或许能为突破传统瓶颈问题带来全新的解决方案,但作为新兴技术,AIGC如何清晰的实现业务价值,还需要依赖可靠性和可信度极高的数据。在这个过程中,作为下一代数据基础设施提供商,DataPipeline将发挥重要的作用。
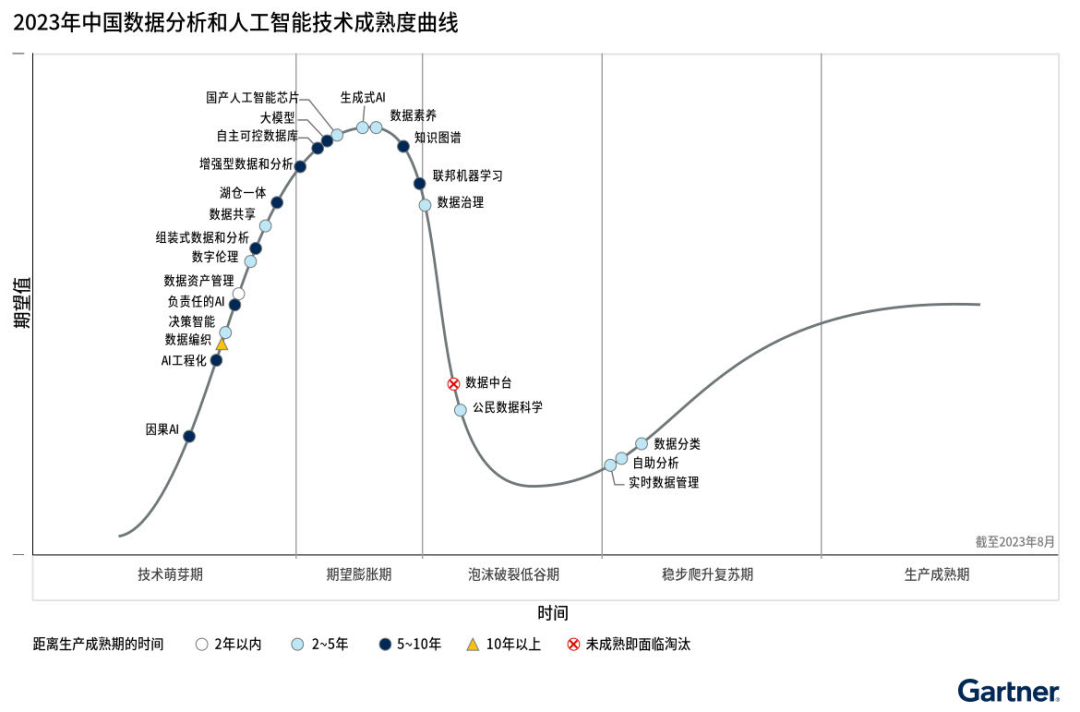
图源来自Gartner
数据领域在过去几十年得到迅速发展,现在每个企业都成为了“数据公司”。随着AIGC技术的发展,企业可以通过它来分析和处理内部所产生的大量独有数据资产,这种方式可以在市场分析、客户洞察、产品开发等多个方面发挥巨大作用,并且实现业务的持续创新和增长。因此,建立一个能够处理实时数据的基础设施变得至关重要,它能确保AIGC应用获取及时、可靠、精准的数据,实现实时分析和高效洞察,从而帮助企业充分释放数据价值。
从DataPipeline的产品结构上看,我们致力于将企业的数据这一核心生产要素和企业的价值通过基于DataOps的数据管理手段进行链接,并沉淀成必要的数字化底层能力。随着国家科技实力的不断提升和AIGC技术的崭露头角,数据流动所带来的价值也越发重要。不难预见,DataPipeline所提供的实时数据处理能力,将成为企业实现AIGC技术有效应用的关键。
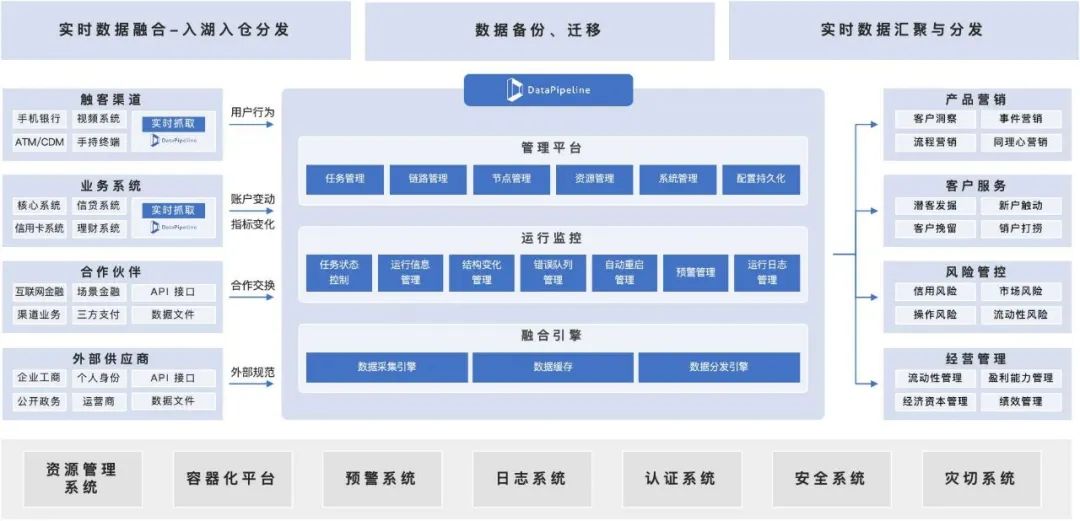
DataPipeline产品架构图
影响数据生产力的两大关键因素
一项技术从萌芽之初发展到稳定成熟的过程中,不可避免的会经历多个阶段。2000年,大数据概念的首次出现,便引起了数据处理领域的高度关注。到了2014年,当大数据最后一次被Gartner收录至Emerging Technologies Hype Cycle中,意味着大数据已步入稳定的成熟期。十年后的今天,大数据已成为企业战略的重要核心,数据在各行各业的发展运营、业务开拓、市场洞察和管理决策等方面中的重要性不言而喻。
“数据是新时代的石油。”这句话虽然有些老生常谈,但它却揭示了一个事实:在当今世界,数据已成为企业最重要的资产之一。在这个共识之下,企业以数据驱动数字化转型,实现数据生产力的充分释放。但是,数据技术的更新迭代和市场需求的快速升级,使数据管理在内外部作用下面临着新的挑战。如何推动数据与业务深度融合,让数据在业务中发挥实际作用并为企业创造价值,成为了每个企业不容忽视的重要课题。
随着新的业务形态不断出现,各行业的客户行为也发生着日新月异的变化,例如服务场景的社交化、营销渠道的线上线下一体化等,这对传统的经营模式带来了巨大挑战。企业在释放数据生产力的过程中,有着两个关键的影响因素。
一是数据应用场景不断丰富。随着数据技术的更新迭代和市场需求的快速升级,在业务侧,数据驱动了各种各样的应用场景,如风控、营销、客户体验、内部管理等多种用数场景推动了数据管理理念与实践的变革。在技术侧,数据源的架构变得繁多和复杂,数据应用也逐渐变得更加垂直和场景化,这倒逼了现代数据架构飞速发展。
二是数据供给速度持续提高。业务部门想要快速抓住商机、及时构建应用并留存客户进行营销,不仅需要用数据快速测算市场规模,更需要在时间窗口打开的时机内提供相应的产品和服务从而占领市场,这导致业务部门对数据处理的时效性要求变得越来越高。
在应对不断丰富的场景和数据处理速度的变化时,企业面临的核心问题是如何获得时效性更强、可靠性更高和可观测性更强的数据基础设施,以提高企业的运营效率和帮助企业发现新的业务增长点。
基础设施可靠性和业务需求间的平衡
构建实时数据管理体系是一个逐步演进的过程,这也反映了企业对数据时效性需求的巨大变化。我们发现,随着业务应用需要最新的数据以做出有效的决策,数据处理的时效性要求已从按季、月计算转变为以分钟、秒为单位。这一过程的关键在于增强多方角色协同与敏捷开发程度,确保数据从生产到消费的各个环节都紧密相连,从而形成一个有机的整体。当前趋势表明,基于大数据平台、流式计算引擎的数据处理模式相对数仓的数据处理模式而言,并不是替代和颠覆的关系,而是会共同且长期的存在于企业的数据架构当中,并不断引入和集成,更新、更加场景化的处理模式,从而应对快速变化的业务需求和市场需求。
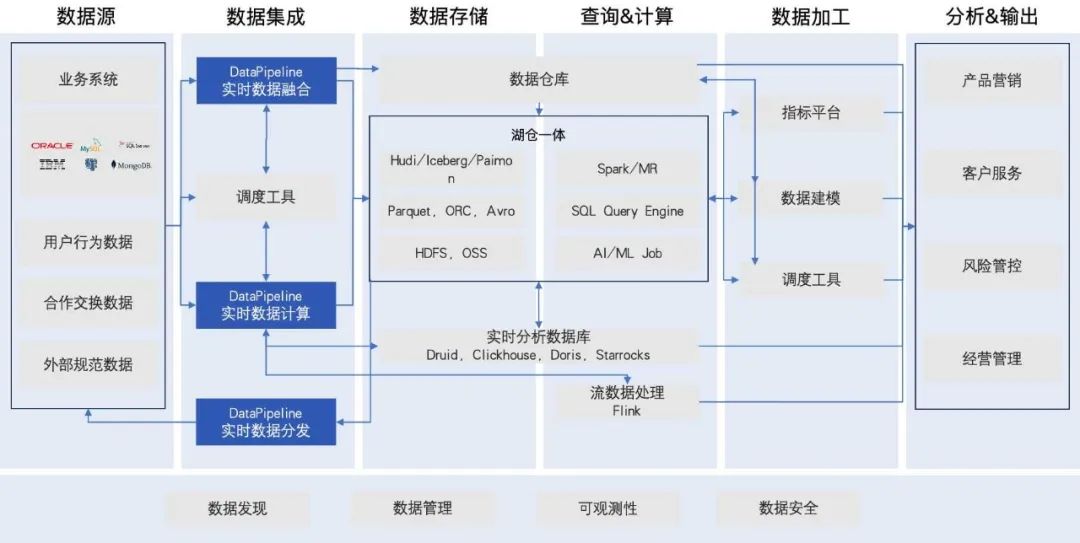
DataPipeline作为安全可靠的数字基础设施,一方面,我们能够高效地将数据从异构的数据源集成到业务系统,优化数据流程和提升数据处理的时效性,帮助企业迅速响应市场变化。另一方面,我们通过对业务需求进行精确判断和筛选,确保理解客户业务需求和最终目标,避免资源浪费。基于这种方法,我们既能清晰地规划产品发展路线,又能高效配置资源,从而实现数据生产力的最大化。
技术投入和成本效益的平衡
目前,我们可以大约接触到1400多种大数据技术。尽管技术的多样性为创新提供了广阔空间,但也带来了技术投入和成本效益之间的考量。自2010年开始,伴随互联网行业的崛起,数据量级呈现爆炸式增长,出现了更加复杂和多样的数据源,数据的流转、存储以及管理等问题变得更加复杂。到今天,多重系统和并行逻辑的使用仍会导致数据架构变得复杂,而AIGC等新技术的引入,会进一步增加数据架构的复杂性,这严重降低和阻碍了数据价值的释放与效率。因此,对于企业而言,建立统一的数据架构和管理机制至关重要,它不仅简化了管理流程,而且确保了技术投入和成本效益之间的平衡。
我们致力于让数据回归业务,让客户关心业务本身。DataPipeline提供统一的实时数据管理平台,通过对数据链路持续构建,像交付应用一样快速、灵活地交付数据,并在过程中管理好数据链路的可观测性,让数据业务人员更容易地发现数据、安全地使用数据,最终达到降低TCO,提高ROI,帮助各行各业的企业实现数字化和智能化转型的长期战略目标。
发挥未来生产力
目前,以人工智能、云计算、大数据及互联网技术为代表的技术正对各行各业的业务模式和竞争形态进行重塑。在新的发展格局之下,技术场景的快速分化产生大量不同特性的存储与计算引擎、信创大势下优秀国产基础软件涌现、业务导向下数据结构的快速迭代、网络技术革新带来的丰富数据源,繁荣的技术生态正在呼唤更创新的数据管理方式。
同时,业务全场景创新、数据量爆炸式增长且渗透度高、数据时效性需求增加、数据采集/获取/应用的复杂度提升、异构数据技术引擎的涌现与驱动,这几个因素的加权将带来必然的数据管理理念与实践的变革。
自DataPipeline创立之初,我们便秉承着“连接一切数据、应用和设备”的使命,将业务聚焦于组织的数据管理全景,始终致力于释放数据生产力。在多年的发展中,DataPipeline深耕对数据安全性、可靠性及运行性能有着最高行业标准的金融业,旨在打造具有高标准的行业级标杆案例,再逐步覆盖能源、运营商、政企等行业,目前已服务了中国银行、中国民生银行、中国石油、中国电信等世界五百强企业在内的数百家客户。实践证明,DataPipeline通过打造实时数据管理基础,有效满足了众多客户根据自身特点和业务场景的需求。这不仅让客户能够充分地挖掘数据潜力,也使他们能够敏捷应对业务变化。通过这种方式,DataPipeline成功地支持了各行各业的数字化和智能化转型进程。

DataPipeline获得重点领域信息化领先客户的深入认同
同时,我们深知新技术的应用需要全产业链的共同探索。为此,DataPipeline不断加强生态系统的建设,积极投入产业适配。目前,DataPipeline已与多家生态伙伴开展生态建设,共同构建自主安全的上下游业务生态,旨在向下深度整合各类数据管理技术,向上支撑各行业的数字化和智能化应用,确保它们的成功落地和稳定运行。
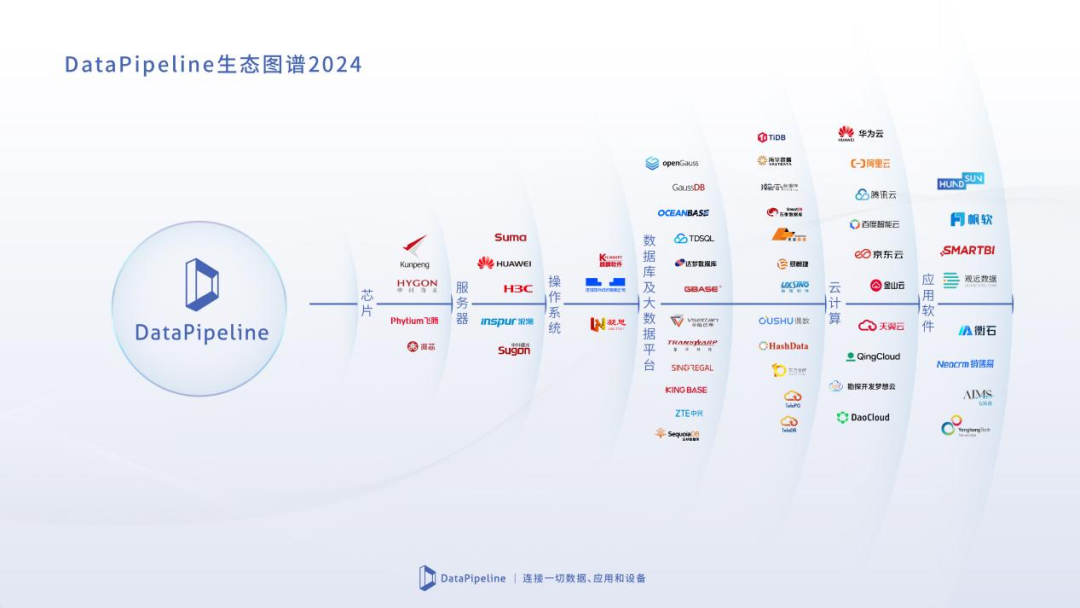
DataPipeline生态图谱
我们相信,在不远的未来,数据生产力必将得到更进一步的释放!
·关于陈诚:
陈诚,DataPipeline创始人&CEO,本科就读于上海交通大学,留学于美国密歇根大学并获荣誉毕业,曾就职于美国 Google、Yelp 等国际知名公司;专注于大数据、计算机算法、软件工程、互联网产品等领域的研究,曾参与大数据团队构建实时可扩展大数据平台每年给 Yelp 节省上千万美元。


这篇关于【金猿人物展】DataPipelineCEO陈诚:赋能数据应用,发挥未来生产力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





