本文主要是介绍从大数据看最受欢迎的医院(广州篇),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对某方面有统计需求的同学可以留言哟~O(∩_∩)O~!!!
数据下载时间:20170622
先啰嗦几句:
1.最近经常跑医院,医院各种制度,各种流程,交通、住宿都很不方便。所以想做个统计,看看哪个医院比较好。
2.这是获取某个挂号网站的数据,因为挂号网站并没有形成严格垄断,所以有些医院并不在上面。
3.另外,一些小的诊所,因为没有网络挂号的必要,这些网站也是没有收录的。
4.被收录的医院一般都是比较大,人流比较多的医院。
5.如果有统计建议或者想知道哪个城市的医院情况的可以留一下言
相关内容:
大数据统计租房市场现状(广州篇)
如果链接打不开的话可以关注公众号:肥宝的实验室
下面直入主题吧:
●医院等级数量
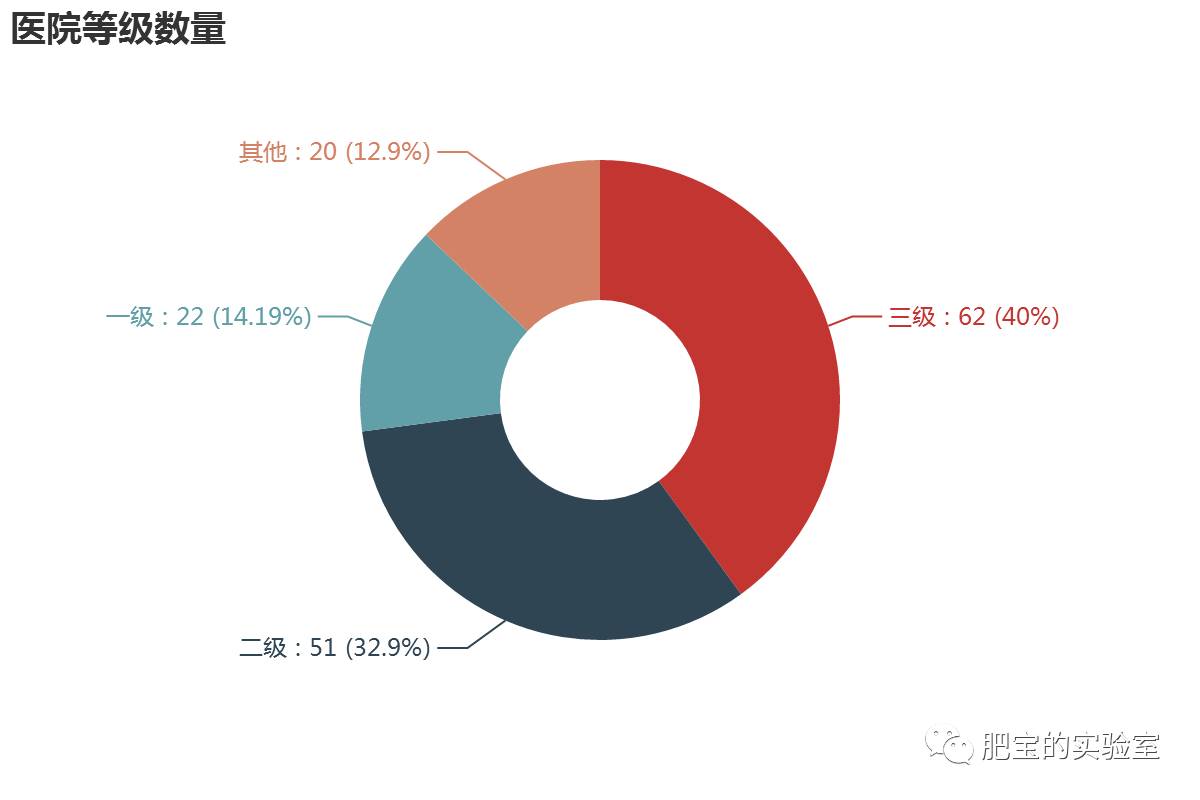
结论:
1.有部分医院找不到具体级别,都归为“其他”了。
2.三级医院是最高级的,占了三分一,二级医院也差不多。
3.一级医院只有不到六分一。
4.出现高级医院比低级医院多的原因估计是很多医院没有被收录,另外很多小诊所可能也没有达到评级标准。
5.这些医院都分布在哪里呢?下面看看医院的地理分布。
●医院的地理分布
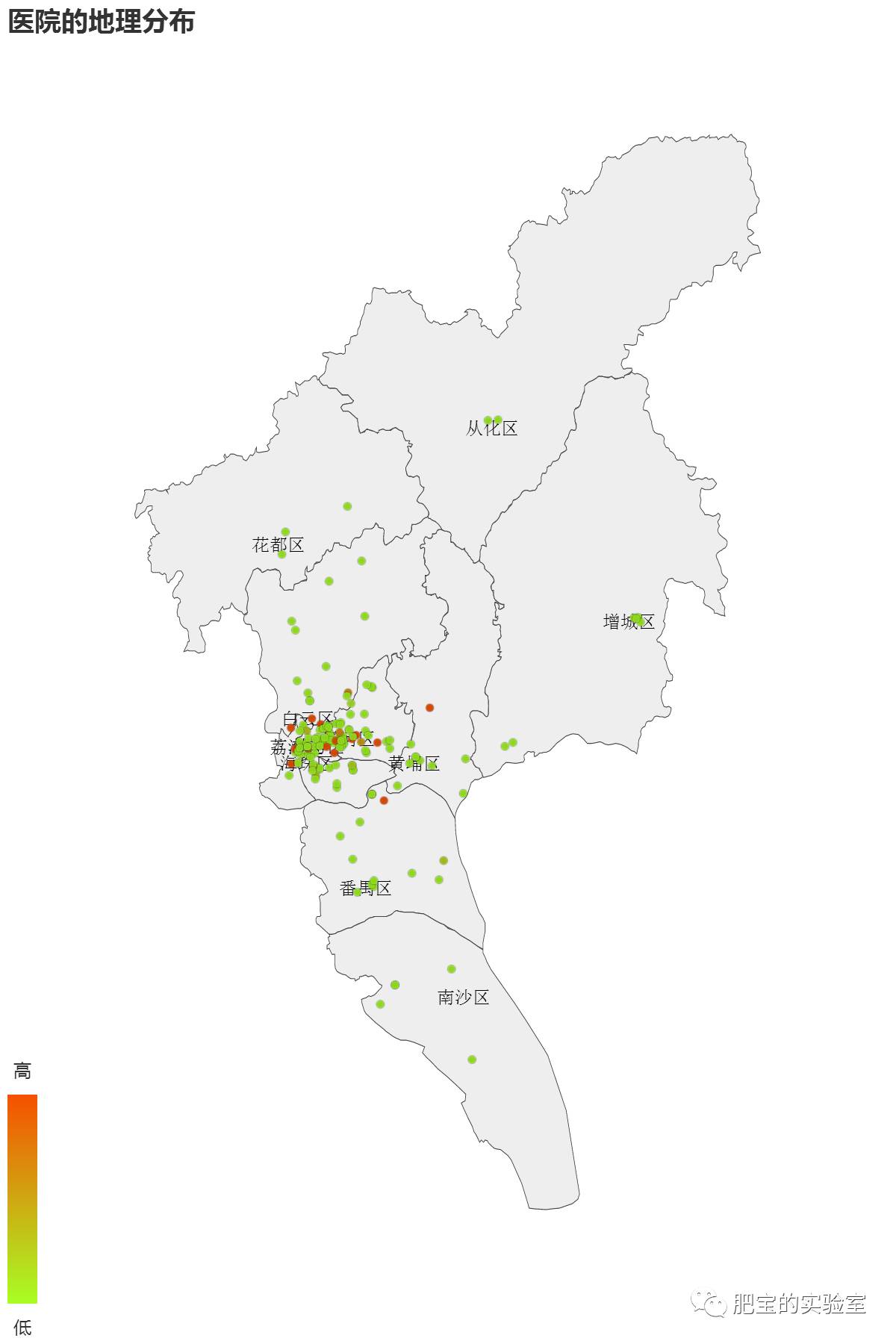
结论:
1.这些医院都是集中在天河、海珠、越秀比较发达的区域,超过80%。
2.这个区域也是租房供应量最密集最贵的地方。可以猜想城市规划都是集中发展的。
3.白云区也有相当多的医院,分布在白云山两旁。这可能是因为早年的规划,那一带当时算是郊区,兴建了一批制药厂,后来就建立一些医院,当然,这只是个人猜测。
4.离中心区域越远的地方,大医院的分布就越少了,从化、增城、花都、南沙寥寥无几。
5.所以考虑买房的同学们,真的应该想一下,偏远地区是否值得去,因为太远了,仅仅从租房信息和医院信息来看,基础设施还没完善。推荐旁边的佛山,那边其实更加近。
●医院评分
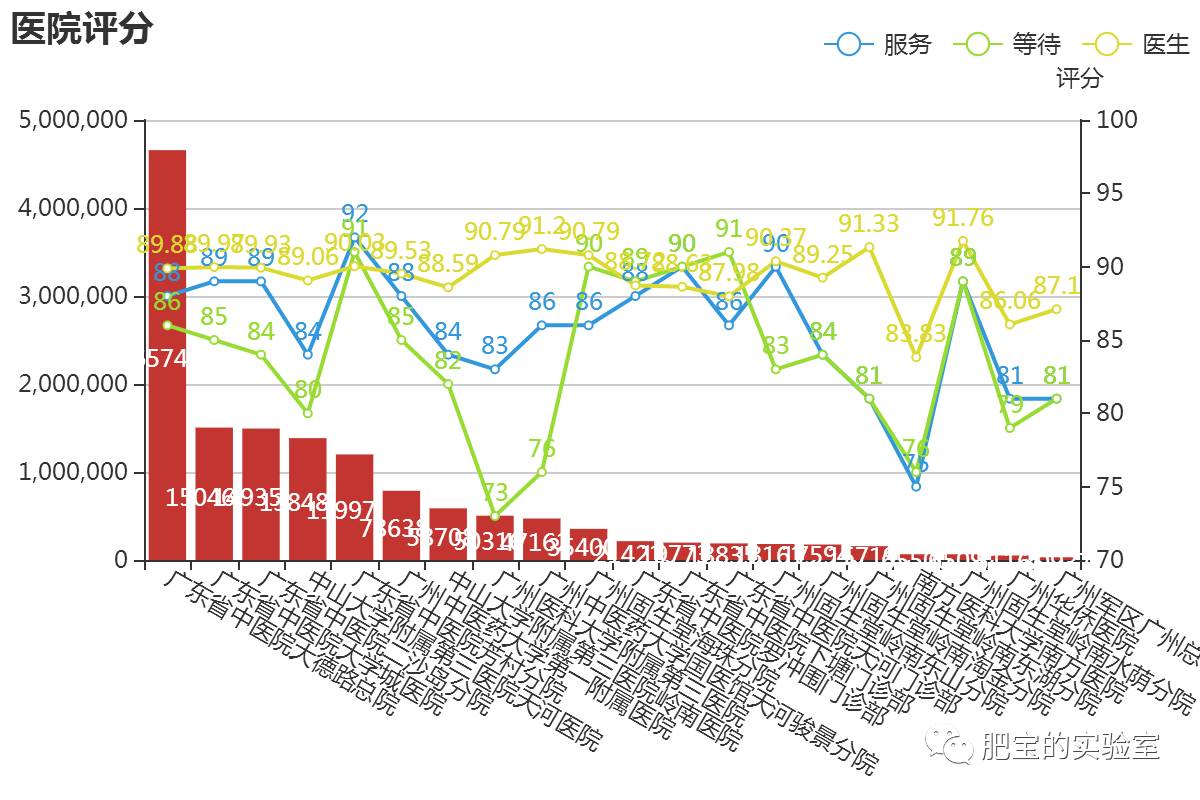
结论:
1.这个图是按挂号量来排列的,量最多的是在最前面。
2.大德路总院不知道是比较特殊还是跟这个网站做了合作,挂号量远远超出其他医院。
3.黄色的线是医生的平均评价,相对来说比较平稳,也有个别是比较低分的。
4.绿色的是等待时间,越低分表示等待时间越长,效率越差。
5.蓝色是总体服务的评价,波动也很大。
6.通常越大的医院是越多人的,这个肯定会比医务人员多更多。所以造成大医院的等待时间更长,感觉更差,但是并不能就一定说明医疗服务就差的。
7.还有很多医院的,因为篇幅问题,只能放挂号量最多的20个了。
8.至于建议就不给了,有些评分特别低的大家自己看图,自己衡量。
●医生数量
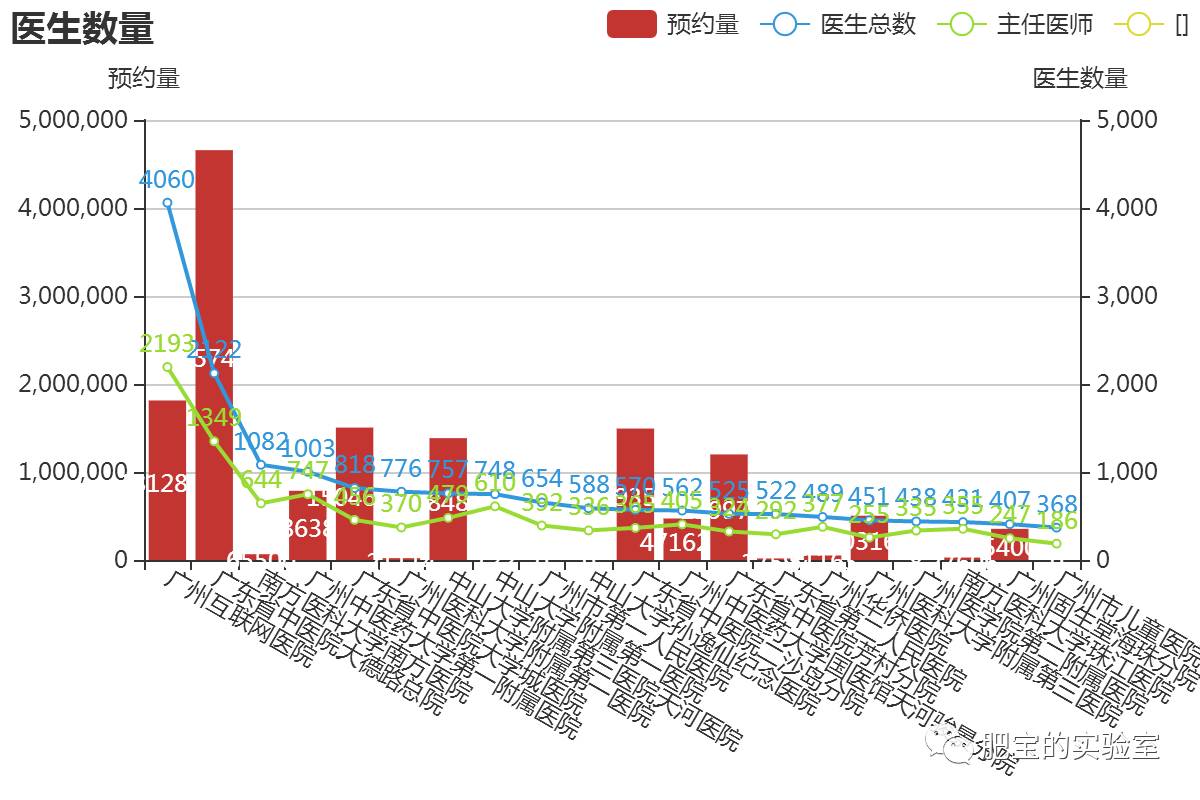
结论:
1.医生分好多级别的,原始数据里面,有很多是主任医师。所以就分成两个数据来处理。
2.这个图是按医生数量来排列的。
3.红色柱是挂号量,从图中看医生多的医院,有部分挂号量很低,应该会比较少人。
4.互联网医院医生最多,其主要是通过网络进行诊断,估计很多其他医院的医生在里面兼职。
5.大德路总院的医生也是最多的,看来挂号量这么高也有妥妥的实力原因。
6.中山大学、广州中医药大学、南方医科大学对广州的医疗行业影响巨大。
7.医疗这种极度专业的行业,我们外行人并不能做出比较准确的判断,所以只能从大数据透露出来的信息中找出一点点希望有用的信息。大家可以保存下来以备使用,或者关注公众号《肥宝的实验室》
●网络诊断数量
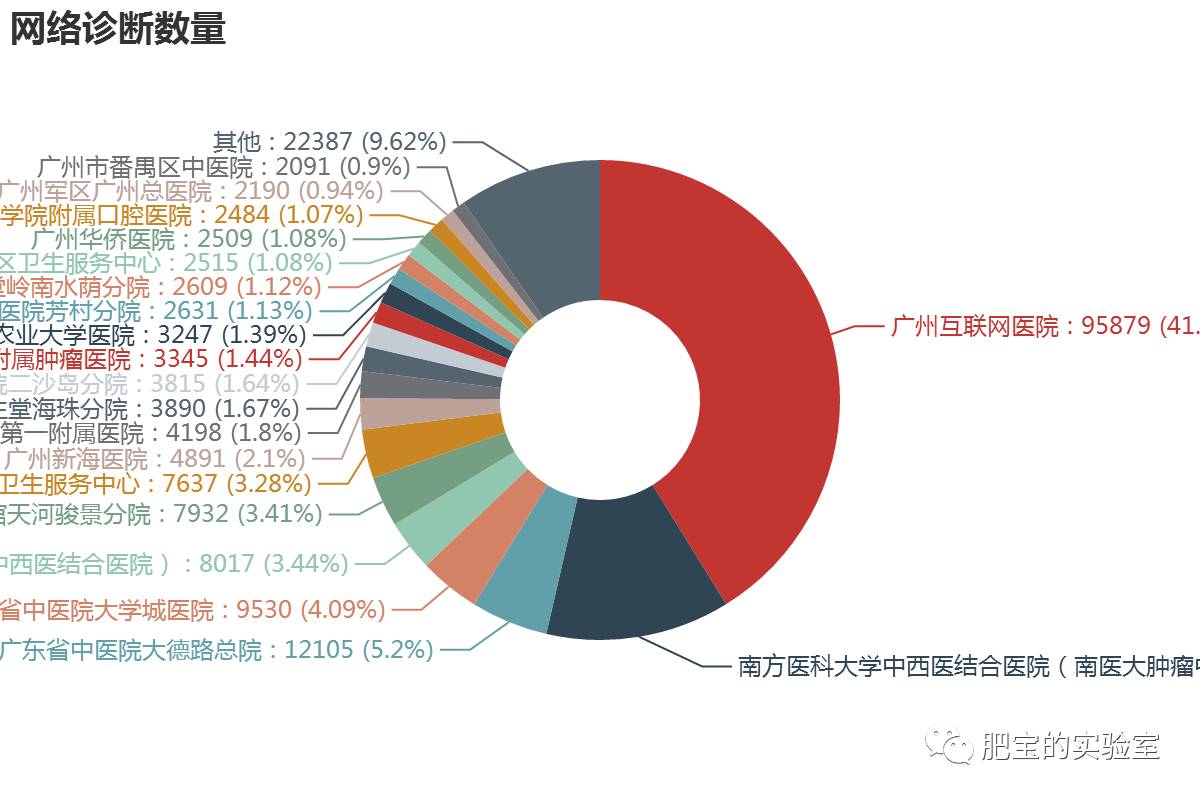
结论:
1.网络时代怎么少得了网络医疗,挂号网站除了提供挂号,还提供了网络诊断。
2.广州互联网医院占了40%多的份额,妥妥的第一。
3.南方医科大学也有相当多的份额。其他医院的份额就少很多了。
4.这个网站的价格是60元进行一次邮件诊断,可以上传图片,200元10分钟视频诊断。
5.对于中国人现在的消费习惯来说,这个收费难以判断是否合理。毕竟还是很多人习惯以实物来判断价值,而不是服务。
6.从大德路总院来看,网络诊断10000多的量,跟挂号量400多万来比较是微不足道的。也可以看出这个领域还有巨大的发展空间。但是这个处理技术,更多的是人们生活习惯和观念的转变。
最后再说一次,对医疗行业真的不熟,但是数据不会说谎,仁者见仁智者见智,还是大家判断好了。
觉得有用就关注、分享一下哟!O(∩_∩)O哈!

这篇关于从大数据看最受欢迎的医院(广州篇)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





