本文主要是介绍【得物技术】GOREPLAY流量录制回放实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GoReplay 简介
随着应用程序的复杂度的增长,测试它所需要的工作量也呈指数级增长。 GoReplay 为我们提供了复用现有流量进行测试的简单想法。GoReplay是一个用golang开发的简单的流量录制插件,支持多种方式的过滤,限流放大,重写等等特性。GoReplay 可以做到对代码完全无侵入性,也不需要更改你的生产基础设施,并且与语言无关。它不是代理,而是直接监听网卡上的流量。
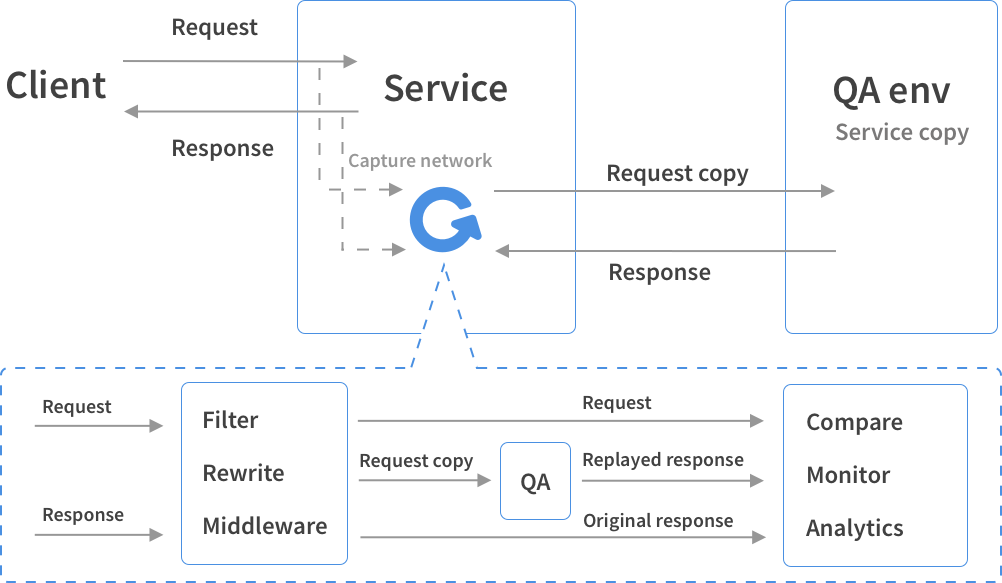
GoReplay 工作方式:listener server 捕获流量,并将其发送至 replay server 或者保存至文件,或者保存到kafka。然后replay server 会将流量转移至配置的地址
使用过程
需求:接到算法侧的需求,需要录制真实的生产环境流量,并且随时回放到任意环境。
由于算法侧部分场景为非Java语言编写,现存的流量录制平台暂时无法支持,需要采用新的录制组件来支撑压测需求,遂选择goreplay 。
GoReplay支持将录制的数据存储到本地文件中,然后回放时从文件中读取。考虑到每次录制回放时需要进行存储及下发文件的复杂度,我们期望使用更便捷的方式来管理数据。
GoReplay也是原生支持录制数据存储到kafka中的,但是在使用的时候,发现它有较大的限制;使用kafka存储数据时,必须是流量录制的同时进行流量回放,其架构图如下:
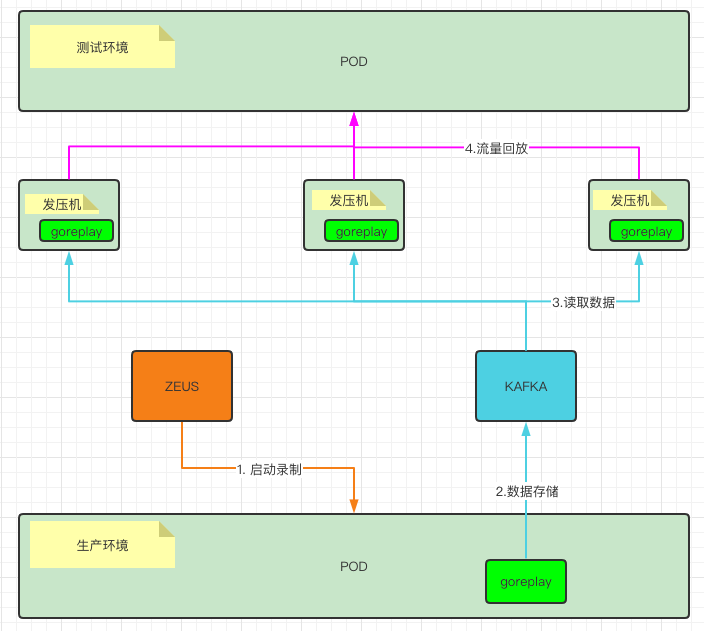
流程1-4 无法拆分,只能同时进行
这会显得流量录制回放功能很鸡肋,我们需要录制好的数据任意时刻重放,并且也要支持将一份录制好的数据多次重放。既然它已经将流量数据存储到了kafka,我们就可以考虑对GoReplay进行改造,以让他支持我们的需求。
改造后的流量录制回放架构图:
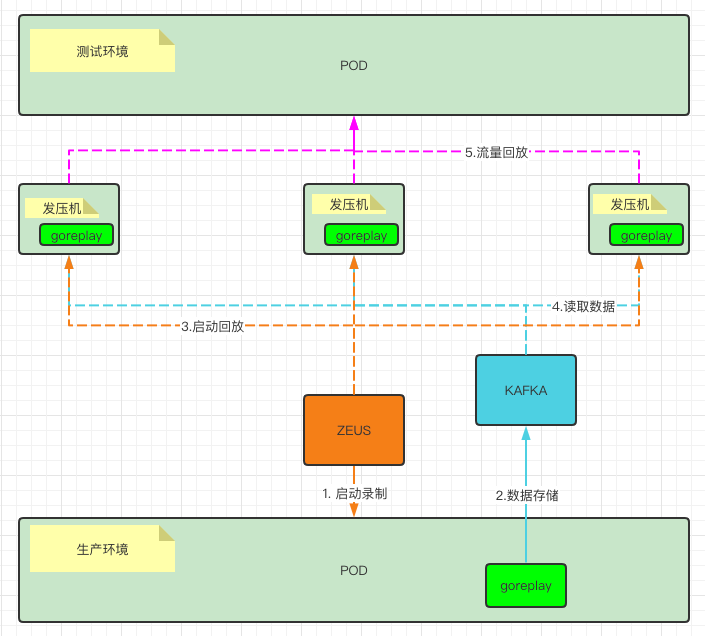
图中,1-2 与 3-5 阶段是相互独立的
也就是说,流量录制过程与回放过程可以拆开。只需要在录制开始与结束的时候记录kafka的offset,就可以知道这个录制任务包含了哪些数据,我们可以轻松的将每一段录制数据,整理成录制任务,然后在需要的时候进行流量回放。
改造与整合
kafka offset 支持改造
简要过程:
源码中的 InputKafkaConfig 的定义
type InputKafkaConfig struct {producer sarama.AsyncProducerconsumer sarama.ConsumerHost string `json:"input-kafka-host"`Topic string `json:"input-kafka-topic"`UseJSON bool `json:"input-kafka-json-format"`
}修改后的 InputKafkaConfig 的定义
type InputKafkaConfig struct {producer sarama.AsyncProducerconsumer sarama.ConsumerHost string `json:"input-kafka-host"`Topic string `json:"input-kafka-topic"`UseJSON bool `json:"input-kafka-json-format"`StartOffset int64 `json:"input-kafka-offset"`EndOffset int64 `json:"input-kafka-end-offset"`
}源码中,从kafka读取数据的片段:
可以看到,它选取的offset 是 Newest
for index, partition := range partitions {consumer, err := con.ConsumePartition(config.Topic, partition, sarama.OffsetNewest)go func(consumer sarama.PartitionConsumer) {defer consumer.Close()for message := range consumer.Messages() {i.messages <- message}}(consumer)}修改过后的从kafka读数据的片段:
for index, partition := range partitions {consumer, err := con.ConsumePartition(config.Topic, partition, config.StartOffset)offsetEnd := config.EndOffset - 1go func(consumer sarama.PartitionConsumer) {defer consumer.Close()for message := range consumer.Messages() {// 比较消息的offset, 当超过这一批数据的最大值的时候,关闭通道if offsetFlag && message.Offset > offsetEnd {i.quit <- struct{}{}break}i.messages <- message}}(consumer)}此时,只要在启动回放任务时,指定kafka offset的范围。就可以达到我们想要的效果了。
整合到压测平台
通过页面简单的填写选择操作,然后生成启动命令,来替代冗长的命令编写
StringBuilder builder = new StringBuilder("nohup /opt/apps/gor/gor");
// 拼接参数 组合命令
builder.append(" --input-kafka-host ").append("'").append(kafkaServer).append("'");
builder.append(" --input-kafka-topic ").append("'").append(kafkaTopic).append("'");
builder.append(" --input-kafka-start-offset ").append(record.getStartOffset());
builder.append(" --input-kafka-end-offset ").append(record.getEndOffset());
builder.append(" --output-http ").append(replayDTO.getTargetAddress());
builder.append(" --exit-after ").append(replayDTO.getMonitorTimes()).append("s");
if (StringUtils.isNotBlank(replayDTO.getExtParam())) {builder.append(" ").append(replayDTO.getExtParam());
}
builder.append(" > /opt/apps/gor/replay.log 2>&1 &");
String completeParam = builder.toString();压测平台通过 Java agent 暴露的接口来控制 GoReplay进程的启停
String sourceAddress = replayDTO.getSourceAddress();
String[] split = sourceAddress.split(COMMA);
for (String ip : split) {String uri = String.format(HttpTrafficRecordServiceImpl.BASE_URL + "/gor/start", ip, HttpTrafficRecordServiceImpl.AGENT_PORT);// 重新创建对象GoreplayRequest request = new GoreplayRequest();request.setConfig(replayDTO.getCompleteParam());request.setType(0);try {restTemplate.postForObject(uri, request, String.class);} catch (RestClientException e) {LogUtil.error("start gor fail,please check it!", e);MSException.throwException("start gor fail,please check it!", e);}
}文/一码当先
关注得物技术,做最潮技术人!
这篇关于【得物技术】GOREPLAY流量录制回放实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





