本文主要是介绍Python推荐系统学习笔记(3)基于协同过滤的个性化推荐算法实战---ItemCF算法(下),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文在 Python推荐系统学习笔记(2)基于协同过滤的个性化推荐算法实战---ItemCF算法 一文的基础上,对其基本的ItemCF算法做出改进。
一、相关概念
1、ItemCF中,基于行为(喜好)的相似性度量公式原始形式:

s i,j 代表物品 i 和 j 的相似度;u(i) 和 u(j) 代表含有物品 i 或者物品 j 行为的用户集合;分子表示既行为过 i 又行为过物品 j 的用户个数的绝对值;分母代表行为过物品 i 以及行为过物品 j 的用户的数量的乘积的平方根。
2、ItemCF中,基于行为(喜好)的相似性度量公式改进形式1:
改进意义:活跃用户应该被降低在相似度公式中的贡献度,如批发商用户会购置多项物品。
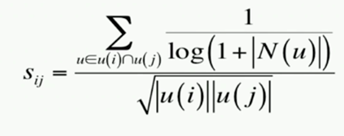
N(u) 代表用户 u 行为过的物品总数。
3、ItemCF中,基于行为(喜好)的相似性度量公式改进形式2:
改进意义:用户在不同时间对物品的操作应给予时间衰减惩罚,如在很多场景中,用户的兴趣会随时间发生变化,需要基于时间衰减进行加权。
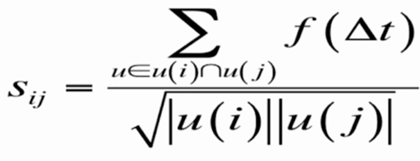 其中,
其中,
△t 是行为差异时间,α 是权重。
二、ItemCF推荐改进实战:
1、第一种改进形式:
只需将原始的base_contribute_score()函数定义更改为以下形式:
def update_one_contribute_score(user_total_click_num):return 1/math.log10(1+user_total_click_num)调用处也改为以下形式:
#第一处
co_appear[itemid_i][itemid_j]+=update_one_contribute_score(len(itemlist))
#第二处
co_appear[itemid_j][itemid_i]+=update_one_contribute_score(len(itemlist))2、第二种改进形式:
其中,
(1)需要更改信息读取工具模块reader.py中的get_user_click函数,增加时间戳信息的获取:
#获得用户的点击序列,改进
def get_user_click(rating_file):#如果路径不存在,返回空数据if not os.path.exists(rating_file):return {},{}#打开文件fp=open(rating_file)num=0#用于传回的数据user_click={}#*改进,加入时间戳user_click_time={}#循环数据for line in fp:#第一行是表头,需要跳过处理if num==0:num+=1continue#根据逗号提取每个项目item=line.strip().split(',')if len(item)<4:continue[userid,itemid,rating,timestamp]=item#*改进处if userid+"_"+itemid not in user_click_time:#存储用户点击的电影的时间戳user_click_time[userid+"_"+itemid]=int(timestamp)if float(rating)<3.0: #如果评分低于3分,则视为该用户不喜欢该电影continue#将单一用户的点击序列添加至返回数据if userid not in user_click:user_click[userid]=[]user_click[userid].append(itemid)fp.close()return user_click,user_click_time(2)更改核心算法中的主函数main_flow():
def main_flow():#获取用户的点击序列数据,改进,加入时间戳数据获取user_click,user_click_time=reader2.get_user_click("../data/ratings.csv")#获取电影信息数据item_info=reader2.get_item_info("../data/movies.csv")#计算各个物品之间的相似度,改进,加入时间戳因子sim_info=cal_item_sim(user_click,user_click_time)#计算每个用户的推荐(与喜好电影相似度较高的)电影recom_result=cal_recom_result(sim_info,user_click)#print(recom_result["1"])#根据用户id推荐电影,此处为1debug_recomresult(recom_result, item_info,"1")(3)更改原始的base_contribute_score()函数:
def update_two_contribute_score(click_time_one,click_time_two):delata_time=abs(click_time_one-click_time_two)#将时间戳单位换算为天total_sec=60*60*24delata_time=delata_time/total_secreturn 1/(1+delata_time) # α 此处取1(4)各个电影间的相似度计算函数更改,增加时间戳因子的获取与计算:
#计算各个电影间的相似度,改进
def cal_item_sim(user_click,user_click_time):#相似度数据co_appear={}#用于统计每个电影的行为用户数量item_user_click_time={}#循环点击序列数据,user是每用户的id,itemlist是每个用户的点击序列for user,itemlist in user_click.items():#循环每个用户的点击序列的索引for index_i in range(0,len(itemlist)):#计算每个item的被用户点击数量itemid_i=itemlist[index_i]item_user_click_time.setdefault(itemid_i,0) #setdefault方法可以对不存在的键做初值设定(初始化)item_user_click_time[itemid_i]+=1#计算每个电影id和其他电影id共同出现在一个用户的点击序列中的数值for index_j in range(index_i+1,len(itemlist)):itemid_j=itemlist[index_j]#改进处if user+"_"+itemid_i not in user_click_time:click_time_one=0else:click_time_one=user_click_time[user+"_"+itemid_i]if user + "_" + itemid_j not in user_click_time:click_time_two = 0else:click_time_two = user_click_time[user + "_" + itemid_j]#计算所有电影id中,两两id的共同出现次数co_appear.setdefault(itemid_i,{})co_appear[itemid_i].setdefault(itemid_j,0)#调用处的改进co_appear[itemid_i][itemid_j] +=update_two_contribute_score(click_time_one,click_time_two)co_appear.setdefault(itemid_j,{})co_appear[itemid_j].setdefault(itemid_i,0)#调用处的改进co_appear[itemid_j][itemid_i]+=update_two_contribute_score(click_time_one,click_time_two)#计算相似度item_sim_score={}item_sim_score_sorted={}for itemid_i,relate_item in co_appear.items():for itemid_j,co_time in relate_item.items():#相似度计算公式sim_score=co_time/math.sqrt(item_user_click_time[itemid_i]*item_user_click_time[itemid_j])#存储相似度item_sim_score.setdefault(itemid_i,{})item_sim_score[itemid_i][itemid_j]=sim_score#对相似度进行排序for itemid in item_sim_score:item_sim_score_sorted[itemid]=sorted(item_sim_score[itemid].items(),key=operator.itemgetter(1),reverse=True)return item_sim_score_sorted三、参考资料:
1、https://www.imooc.com/learn/1029
2、https://www.imooc.com/learn/990
3、https://blog.csdn.net/yimingsilence/article/details/54934302
4、https://blog.csdn.net/xiaokang123456kao/article/details/74735992
5、项亮. 推荐系统实践[M]. 人民邮电出版社, 2012.
这篇关于Python推荐系统学习笔记(3)基于协同过滤的个性化推荐算法实战---ItemCF算法(下)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





