本文主要是介绍【SQL】对表中的记录通过时间维度分组,统计出每组的记录条数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
场景:一般用作数据统计,比如统计一个淘宝用户在年、月、日的维度上的订单数。
业务:一个集合,以时间维度来进行分组求和。
准备一张订单表order,有一些常规属性,比如创建时间,订单号。
DDL语句如下:
CREATE TABLE `order` (`order_id` INT AUTO_INCREMENT PRIMARY KEY,`order_number` VARCHAR(20) NOT NULL,`order_date` TIMESTAMP DEFAULT NULL,`total_amount` DECIMAL(10, 2) NOT NULL
);
测试数据准备如下,50条DML语句,其中order_date分布在2023年1月到12月之间。
这一看就是剁手月光的节奏,月月都不消停地买(狗头保命):
INSERT INTO `order` (`order_number`, `order_date`, `total_amount`) VALUES
('ORD100001', '2023-01-05 12:30:00', 50.99),
('ORD100002', '2023-01-15 14:45:00', 75.50),
('ORD100003', '2023-02-02 10:00:00', 120.75),
('ORD100004', '2023-02-18 16:20:00', 30.25),
('ORD100005', '2023-03-10 08:55:00', 90.00),
('ORD100006', '2023-03-22 20:10:00', 65.50),
('ORD100007', '2023-04-08 09:30:00', 110.25),
('ORD100008', '2023-04-17 15:45:00', 40.75),
('ORD100009', '2023-05-03 18:20:00', 85.00),
('ORD100010', '2023-05-15 12:40:00', 150.00),
('ORD100011', '2023-06-02 14:55:00', 120.50),
('ORD100012', '2023-06-18 11:15:00', 95.25),
('ORD100013', '2023-07-05 17:30:00', 60.00),
('ORD100014', '2023-07-20 19:45:00', 130.80),
('ORD100015', '2023-08-08 08:10:00', 75.50),
('ORD100016', '2023-08-17 22:30:00', 45.25),
('ORD100017', '2023-09-03 14:50:00', 110.00),
('ORD100018', '2023-09-15 16:15:00', 80.25),
('ORD100019', '2023-10-02 11:30:00', 95.50),
('ORD100020', '2023-10-18 13:45:00', 120.75),
('ORD100021', '2023-11-05 09:00:00', 55.00),
('ORD100022', '2023-11-20 18:20:00', 90.80),
('ORD100023', '2023-12-08 10:45:00', 70.50),
('ORD100024', '2023-12-17 14:00:00', 35.75),
('ORD100025', '2023-12-29 18:20:00', 120.00),
('ORD100076', '2023-03-08 15:30:00', 80.50),
('ORD100077', '2023-03-17 12:00:00', 45.75),
('ORD100078', '2023-04-02 16:20:00', 60.00),
('ORD100079', '2023-04-15 19:45:00', 130.80),
('ORD100080', '2023-05-03 08:10:00', 75.50),
('ORD100081', '2023-05-15 22:30:00', 45.25),
('ORD100082', '2023-06-02 14:50:00', 110.00),
('ORD100083', '2023-06-18 16:15:00', 80.25),
('ORD100084', '2023-07-05 11:30:00', 95.50),
('ORD100085', '2023-07-20 13:45:00', 120.75),
('ORD100086', '2023-08-05 09:00:00', 55.00),
('ORD100087', '2023-08-20 18:20:00', 90.80),
('ORD100088', '2023-09-08 10:45:00', 70.50),
('ORD100089', '2023-09-17 14:00:00', 35.75),
('ORD100090', '2023-09-29 18:20:00', 120.00),
('ORD100091', '2023-10-08 15:30:00', 80.50),
('ORD100092', '2023-10-17 12:00:00', 45.75),
('ORD100093', '2023-11-02 16:20:00', 60.00),
('ORD100094', '2023-11-15 19:45:00', 130.80),
('ORD100095', '2023-12-03 08:10:00', 75.50),
('ORD100096', '2023-12-15 22:30:00', 45.25),
('ORD100097', '2023-12-29 14:50:00', 110.00),
('ORD100098', '2023-12-30 16:15:00', 80.25),
('ORD100099', '2023-12-31 11:30:00', 95.50),
('ORD100100', '2023-12-31 13:45:00', 120.75);有了以上测试数据,现在我们的需求:订单表在每月为单位的订单数、每天为单位的订单数。
首先是每月为单位的订单数,要求返回数据格式为:
{"orderMonth": "2023-01","orderCount": 4
}
sql编写如下:
SELECT DATE_FORMAT(order_date, '%Y-%m') as orderMonth, COUNT(*) as orderCount
FROM `order`
GROUP BY orderMonth;
返回数据
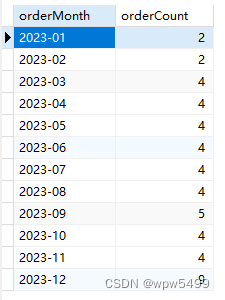
对sql的解读:这里的关键是使用DATE_FORMAT函数来将order_date字段格式化为年月的形式,然后使用GROUP BY按照这个格式化的日期进行分组,并使用COUNT(*)来统计每组的记录条数。
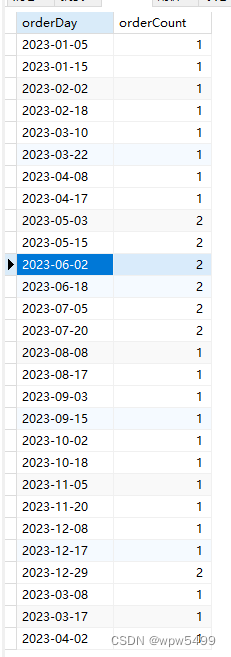
然后是每天为单位的订单数,要求返回数据格式如下:
{"orderDay": "2023-01-08","orderCount": 2
}
sql编写如下:
SELECT DATE_FORMAT(order_date, '%Y-%m-%d') as orderDay, COUNT(*) as orderCount
FROM `order`
GROUP BY orderDay;
查询结果,我只能说能恐怖,我还没有截图完整,这个买快递的频率,直男流泪(╥╯^╰╥):
好的,以上就是这次sql的分享,如果你觉得对你有帮助,同学能动动小手指,帮我点个赞。
这篇关于【SQL】对表中的记录通过时间维度分组,统计出每组的记录条数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








