本文主要是介绍【sklearn练习】preprocessing的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍
scikit-learn 中的 preprocessing 模块提供了多种数据预处理工具,用于准备和转换数据以供机器学习模型使用。这些工具可以帮助您处理数据中的缺失值、标准化特征、编码分类变量、降维等。以下是一些常见的 preprocessing 模块中的功能和用法示例:
-
标准化特征(Feature Scaling):
- 使用
StandardScaler类可以对特征进行标准化,使其具有零均值和单位方差。这对于许多机器学习算法来说是必要的。
示例使用方法:
from sklearn.preprocessing import StandardScalerscaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) - 使用
-
最小-最大缩放(Min-Max Scaling):
- 使用
MinMaxScaler类可以将特征缩放到指定的最小值和最大值之间,通常在0到1之间。
示例使用方法:
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) - 使用
-
编码分类变量:
- 使用
LabelEncoder类可以将分类变量编码为整数标签。
示例使用方法:
from sklearn.preprocessing import LabelEncoderencoder = LabelEncoder() y_encoded = encoder.fit_transform(y) - 使用
-
独热编码(One-Hot Encoding):
- 使用
OneHotEncoder类可以将分类变量转换为独热编码形式,创建虚拟变量。
示例使用方法:
from sklearn.preprocessing import OneHotEncoderencoder = OneHotEncoder() X_encoded = encoder.fit_transform(X_categorical).toarray() - 使用
-
处理缺失值:
- 使用
SimpleImputer类可以填充数据中的缺失值,可以选择使用均值、中位数、众数等填充策略。
示例使用方法:
from sklearn.impute import SimpleImputerimputer = SimpleImputer(strategy="mean") X_imputed = imputer.fit_transform(X_missing) - 使用
-
降维:
- 使用
PCA类可以进行主成分分析(PCA)降维,将高维数据投影到低维空间。
示例使用方法:
from sklearn.decomposition import PCApca = PCA(n_components=2) X_pca = pca.fit_transform(X) - 使用
以上是一些 preprocessing 模块中常见功能的示例用法。数据预处理是机器学习中非常重要的一步,它有助于提高模型的性能和稳定性。您可以根据您的数据和任务选择适当的预处理方法,并将其应用于您的数据,以确保数据准备得当。
实例
例1:
from sklearn import preprocessing
import numpy as npa = np.array([[10, 2.7, 3.6],[-100, 5, -2],[120, 20, 40]])
print(a)
print(preprocessing.scale(a))输出:
[[ 10. 2.7 3.6][-100. 5. -2. ][ 120. 20. 40. ]]
[[ 0. -0.85170713 -0.55138018][-1.22474487 -0.55187146 -0.852133 ][ 1.22474487 1.40357859 1.40351318]]例2:
from sklearn import preprocessing #预处理的模块
import numpy as np
from sklearn.model_selection import train_test_split #将数据打乱随机分为训练集和测试集的类train_test_split
from sklearn.datasets import make_classification #datasets中make开头的创建数据集的类make_classification
from sklearn.svm import SVC #训练模型的类SVC
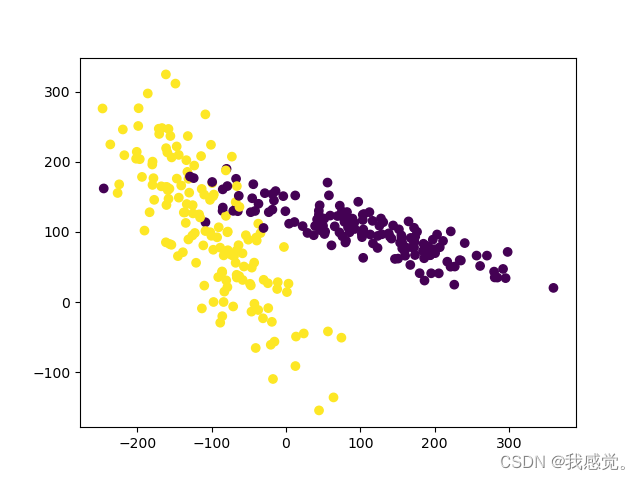
import matplotlib.pyplot as pltX, y = make_classification(n_samples=300, n_features=2,n_redundant=0, n_informative=2,random_state=22,n_clusters_per_class=1,scale=100)
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()X = preprocessing.scale(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
#输出为0.9555555555555556,
#当删去对X的预处理语句X = preprocessing.scale(X),这里的输出理论上减小输出:
这篇关于【sklearn练习】preprocessing的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




