本文主要是介绍[Kubernetes]5. k8s集群StatefulSet详解,以及数据持久化(SC PV PVC),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前面通过deployment结合service来部署无状态的应用,下面来讲解通过satefulSet结合service来部署有状态的应用
一.StatefulSet详解
1.有状态和无状态区别
- 无状态: 无状态(stateless)、牲畜(cattle)、无名(nameless)、可丢弃(disposable)
- 有状态: 有状态(stateful)、宠物(pet)、具有名(haviing name)、不可丢弃(non-disposable)
- StatefulSet是用来管理有状态的应用,例如数据库
- 前面部署的应用,都是不需要存储数据,不需要记住状态的,可以随意扩充副本,每个副本都是一样的,可替代的,这时候可以通过deployment结合service来部署
- 而像数据库、Redis这类有状态的,并且有数据的应用,则不能随意扩充副本,这时候就需要通过statefulSet结合service来部署
- StatefulSet 会固定每个 Pod 的名字
2.statefulset的组成
- headless service 用于定义网络标识(DNS)
- StatefulSet 控制器,用于定义具体应用
- volumeClaimTemplate 存储卷申请模板,用于创建PV,保证数据库的持久化操作
下面就来通过statefulSet结合service部署一个Mongodb
3.创建 Service部署StatefulSet类型的Mongodb
定义一个mongo.yaml,这个yaml和deployment.yaml类似,如下:
- 下面yaml中的 --- 表示:把多个配置文件放在一个yaml中,下面就是把kind为StatefulSet类型的mongo.yaml和service.yaml放在同一个文件中,当然也可以拆分开来
apiVersion: apps/v1
#类型statefulSet
kind: StatefulSet
metadata:#部署的名字name: mongodb
spec:serviceName: mongodb #必须设置,和下面的name保持一致#创建Pod的副本数replicas: 2#定义标签选择器:定义Deployment如何找到要管理的Pod,与template的label(标签)对应selector:matchLabels:app: mongodb #需要和下面的labels统一,进行关联#定义 Pod 相关数据template:metadata:labels:app: mongodb #指定该资源的内容spec:# 定义容器,可以多个containers:- name: mongo # 容器名字image: mongo # 镜像# [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像imagePullPolicy: IfNotPresent
---
apiVersion: v1
#类型Service
kind: Service
metadata:#部署的服务名字,这个可以随意name: mongodb
spec:selector:app: mongodb #需要mongdb.yaml中,也就是上面的pod中的template中定义的metadata.labels.app名称统一,这样mongodb和service才能相互找到type: ClusterIP #默认类型,自动分配一个仅Cluster内部可以访问的虚拟IP,当外部访问项目时,自动分配一个虚拟的pod ip,达到负载均衡操作,下面详细讲解#HeadLess: 不分配IP地址clusterIP: Noneports:- port: 27017 #本 Service 的端口targetPort: 27017 # 容器端口拆分开来的文件如下:
mongo.yaml
apiVersion: apps/v1
#类型statefulSet
kind: StatefulSet
metadata:#部署的名字name: mongodb
spec:serviceName: mongodb #必须设置,和下面的name保持一致#创建Pod的副本数replicas: 2#定义标签选择器:定义Deployment如何找到要管理的Pod,与template的label(标签)对应selector:matchLabels:app: mongodb #需要和下面的labels统一,进行关联#定义 Pod 相关数据template:metadata:labels:app: mongodb #指定该资源的内容spec:# 定义容器,可以多个containers:- name: mongo # 容器名字image: mongo # 镜像# [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像imagePullPolicy: IfNotPresentservice.yaml
apiVersion: v1
#类型Service
kind: Service
metadata:#部署的服务名字,这个可以随意name: mongodb
spec:selector:app: mongodb #需要mongdb.yaml中,也就是上面的pod中的template中定义的metadata.labels.app名称统一,这样mongodb和service才能相互找到type: ClusterIP #默认类型,自动分配一个仅Cluster内部可以访问的虚拟IP,当外部访问项目时,自动分配一个虚拟的pod ip,达到负载均衡操作,下面详细讲解#HeadLess: 不分配IP地址clusterIP: Noneports:- port: 27017 # 本 Service 的端口targetPort: 27017 # 容器端口mongo.yaml和deployment.yaml的区别
- kind不同:deployment.yaml的kind为Deployment,mongo.yaml的kind为StatefulSet
- mongo.yaml的spec的serverName必须配置,必须和service名字统一起来,这样才能关联
- mongo.yaml的service.yaml的type必须是ClusterIP(集群内部访问),访问的时候是没有IP地址的,故需设置ClusterIP:none.当然,type类型也可以是NodePort,这样就可以在外部进行端口映射访问操作
4.部署mongo.yaml
(1).先删除其他无用的配置
该操作可以执行,也可以不执行
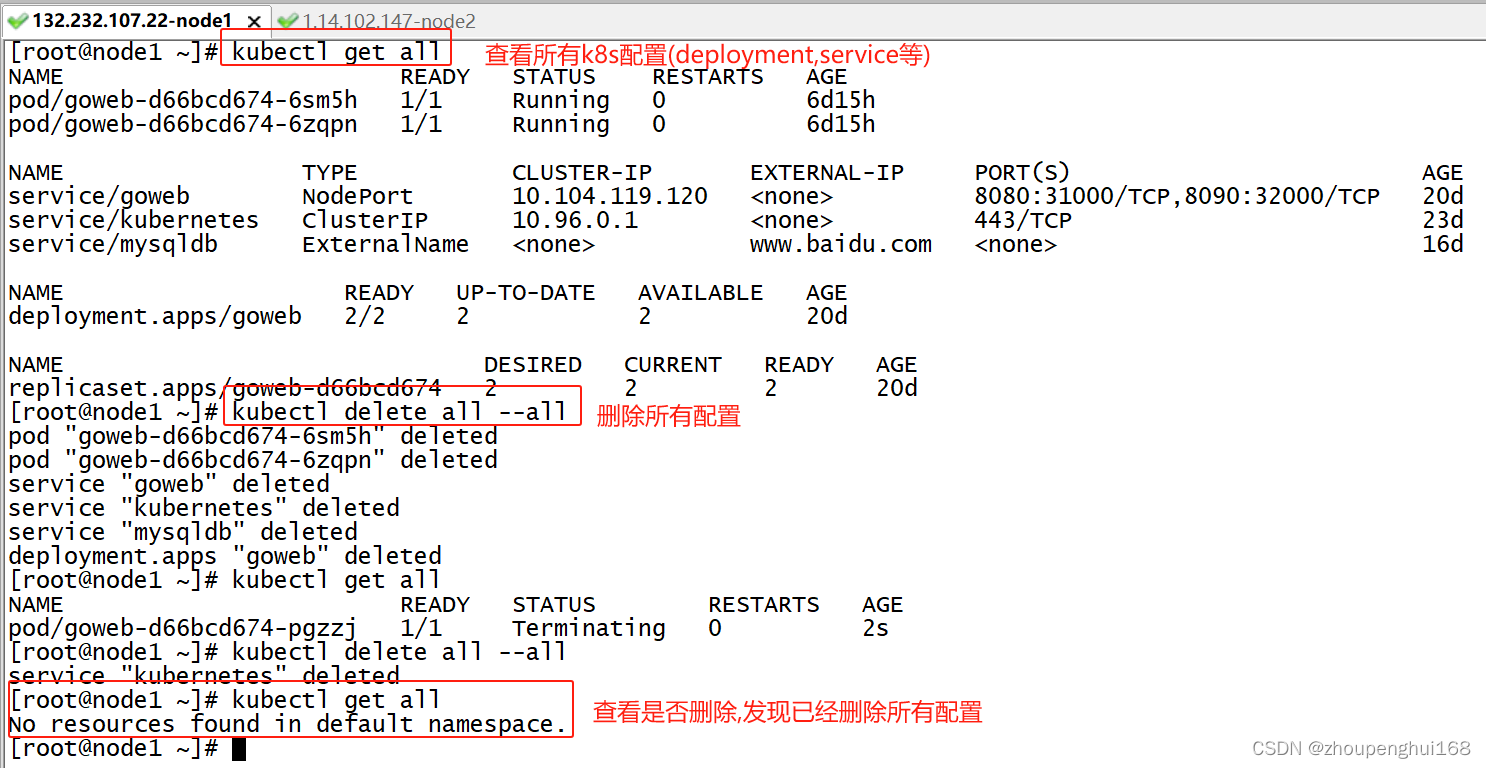
(2).创建mongo.yaml
vi .mongo.yaml,然后把上面的配置复制进入即可
[root@node1 ~]# cat mongo.yaml
apiVersion: apps/v1
#类型statefulSet
kind: StatefulSet
metadata:#部署的名字name: mongodb
spec:serviceName: mongodb #必须设置,和下面的name保持一致#创建Pod的副本数replicas: 2#定义标签选择器:定义Deployment如何找到要管理的Pod,与template的label(标签)对应selector:matchLabels:app: mongodb #需要和下面的labels统一,进行关联#定义 Pod 相关数据template:metadata:labels:app: mongodb #指定该资源的内容spec:# 定义容器,可以多个containers:- name: mongo # 容器名字image: mongo # 镜像这篇关于[Kubernetes]5. k8s集群StatefulSet详解,以及数据持久化(SC PV PVC)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







