本文主要是介绍C++实现网站内搜索功能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 搜索结果的结构
- 下载我们需要的数据
- 分析html结构
- 数据处理
- 去标签之标题
- 去标签之正文内容
- 构造url
- 把上述的数据清理操作对每一个文件都做一遍
- 把处理好的数据都保存到一个.bin文件
- 构建正排索引
- 构建倒排索引
- 使用cpp-jieba分词
- 计算每个文档中的每个词的权重
- 对所有文档都进行上述的建立正排与倒排索引操作
- Search模块
- http server模块
- cpp-httplib
- 拿参,并且调用我们的search返回我们的json串
- 最终结果
总体逻辑如下
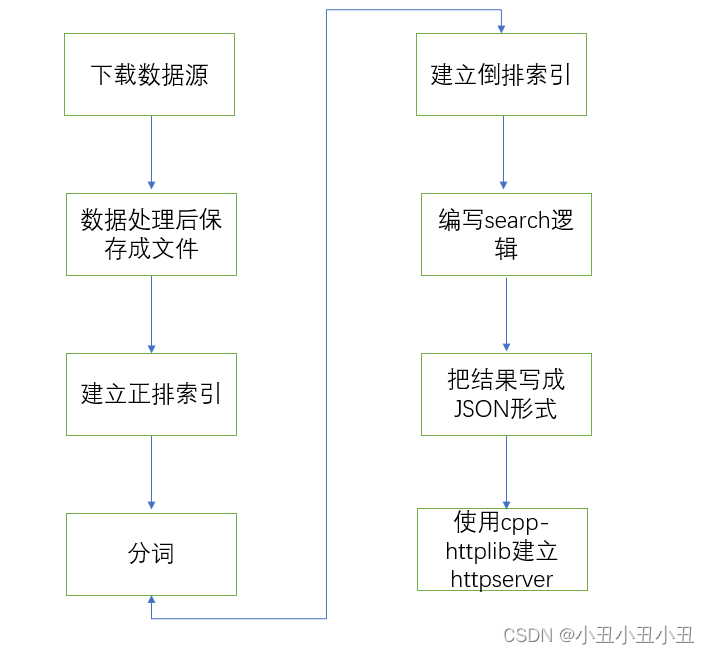
几个关键问题统一写在这:
- 这个是站内搜索,所以不涉及爬虫。都是处理本地下载好的html数据
- 搜索逻辑设计的极其简单。先从浏览器拿到关键字,然后服务器上得到需要返回的文档ID,再把对应ID的文档内容以JSON的形式返回给浏览器
- 在判断哪些文档是最匹配用户输入的关键字的需求上,也是用的简单的逻辑。通过统计文档中出现的关键字次数,并根据关键字出现在不同地方,乘一个不同的系数来当成一个权值。权值越大,认为这个文档和关键字越匹配。
- 正排索引和倒排索引的概念就是根据第二点提出的。
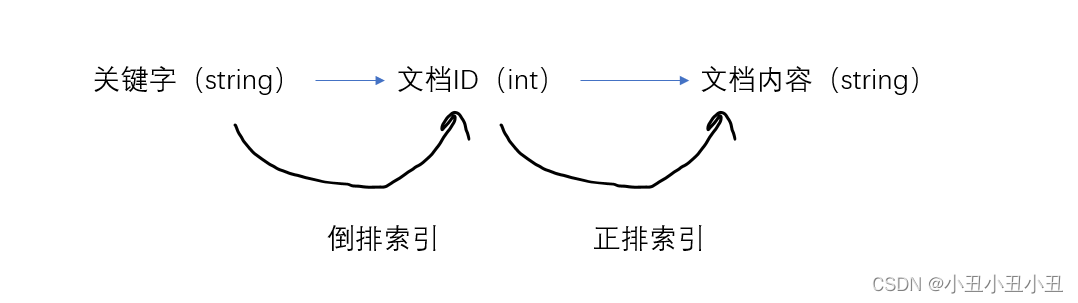
正排索引
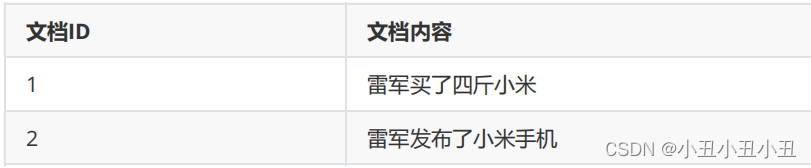
倒排索引

搜索结果的结构

- 网站的url
- 标题
- 一段随机的简介
这样我们就可以通过搜索关键字找到需要的页面的网址了
下载我们需要的数据
下面是boost官网提供的boost文档,里面都是大量的html
下载解压后是这样子的
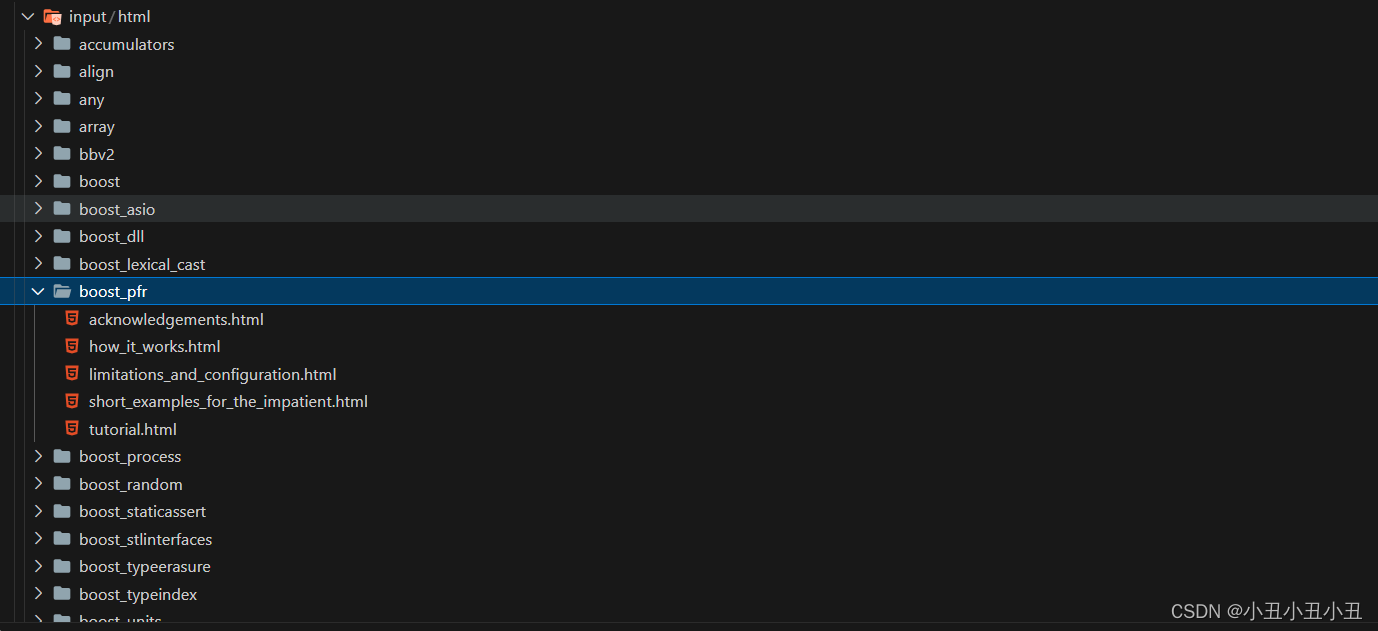
因此我们要返回的结果都是通过解析这部分html来返回的。
分析html结构
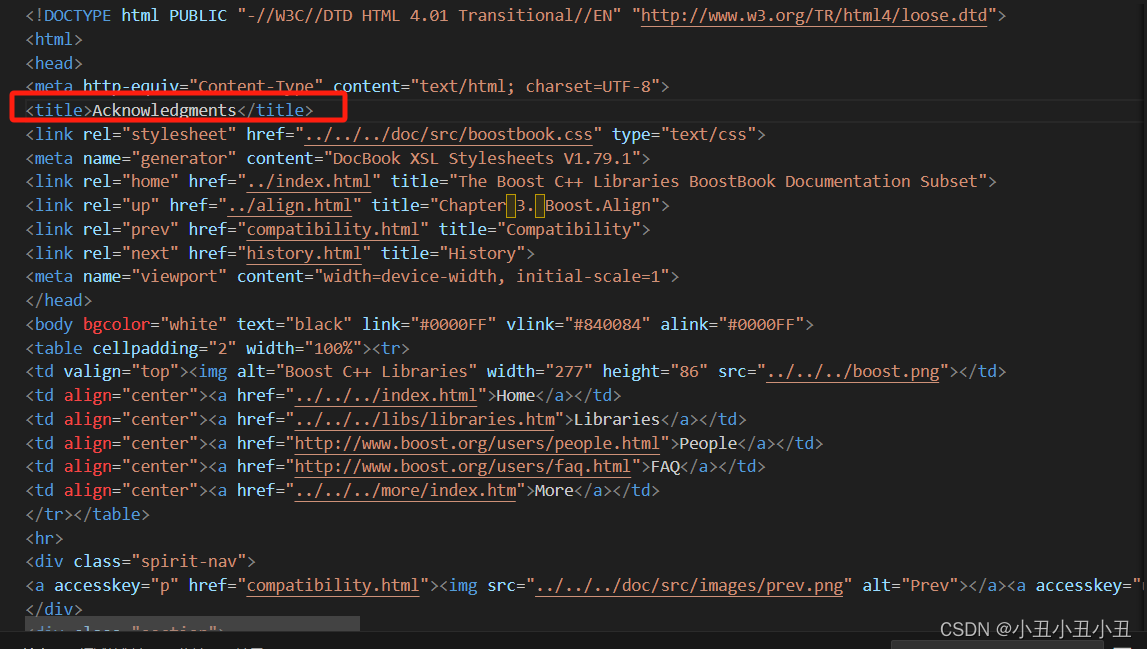
由于我只需要title和其余的content,因此我们首先要做的是去标签工作,提取其中的标题和内容
数据处理
去标签之标题
如何拿到标题是什么?
思路:找到< title >和< /title >标签,里面的那段字符串就是标题
实现的基本思路就是使用find函数和substr函数,比较简单。
关于DocContent是什么后面再补充
void ParseTitle(const std::string &s, DocContent &d)
{int begin = 0, end = 0;begin = s.find("<title>");begin += std::string("<title>").size();end = s.find("</title");if (end < begin)return;d._title = s.substr(begin, end - begin);
}
去标签之正文内容
使用状态变化来编写代码的写法会比较简单
- 一开始时处于LABEL状态,如果是标签状态,继续读下一个字符,直到读到字符’>",要转换成CONTENT状态
- 如果处于CONTENT状态,那么把每一个字符都保存下来,如果读到一个换行符’\n’,那么把它换成空格来存下来。原因是为了方便后面使用一个getline就可以把整一个文档给读进来
void ParseContent(const std::string &s, DocContent &d)
{enum status{LABLE,CONTENT};status st = LABLE;for (char c : s){switch (st){case LABLE:if (c == '>'){st = CONTENT;}break;case CONTENT:if (c == '<'){st = LABLE;}else{if (c == '\n')c = ' ';d._content += c;}break;default:break;}}
}
构造url
由于做的是站内搜索,所以url的构建是基于主网站的。
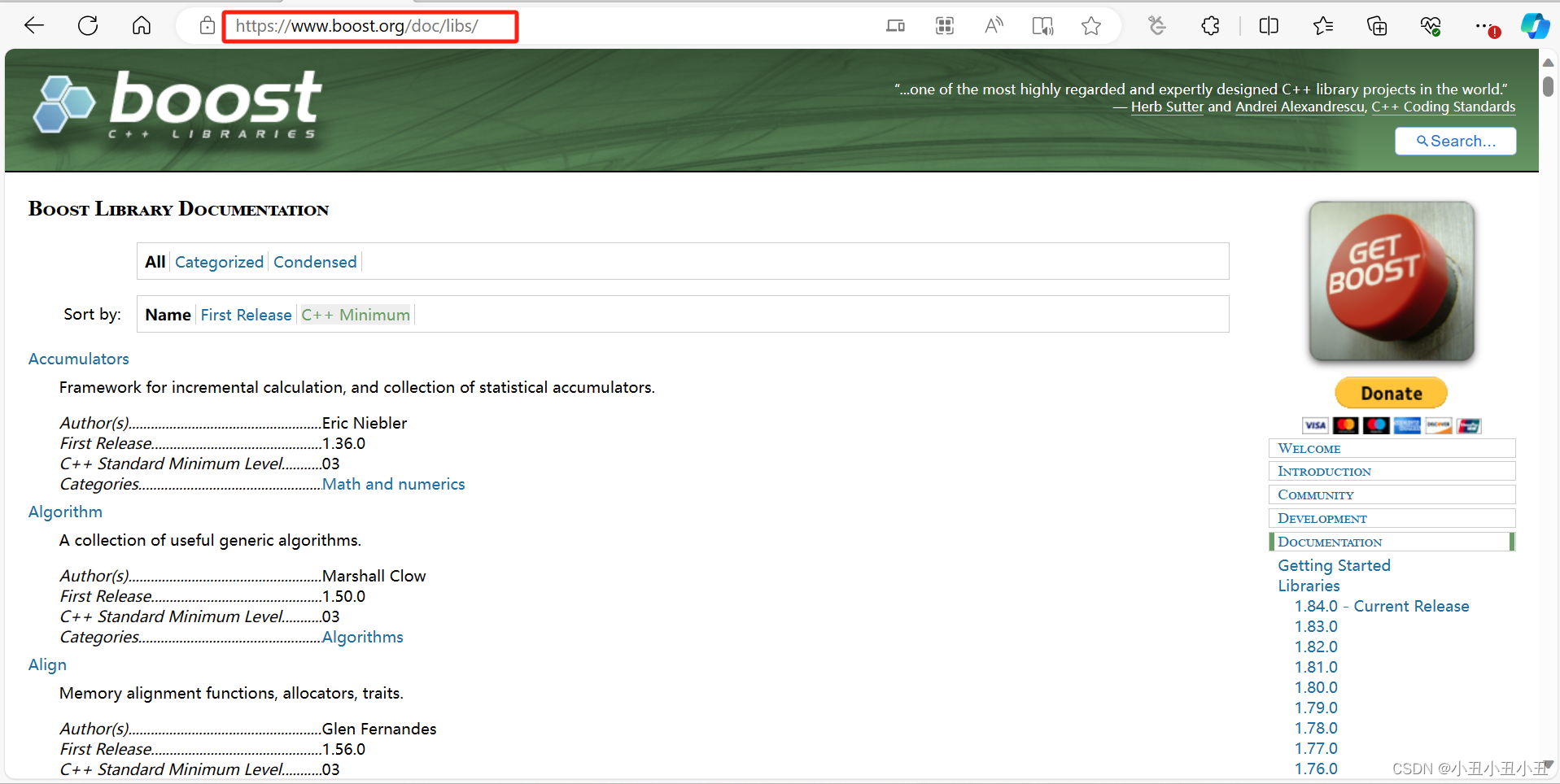
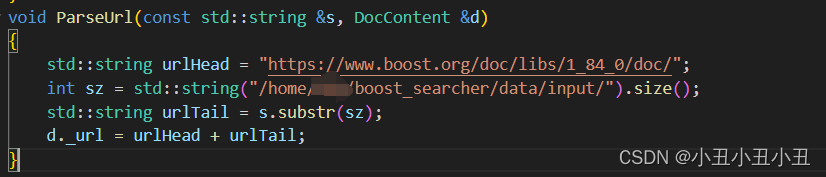
可以看到boost官网的文档都是在框框中的网址里的,所以根据这个网址,再加上每个文件的文件名,就可以构建出一个url了
本质就是基网址+文件名
把上述的数据清理操作对每一个文件都做一遍
逻辑就是遍历存放数据的文件夹,把所有后缀是.html的文件都做一遍数据清理即可。
遍历文件这个操作需要用到boost库里的一个函数(或者用c++17的语法),具体用法参考
std::filesystem::recursive_directory_iterator
void GetFileName(const std::string &src_path, std::vector<std::string> &fileName)
{namespace fs = boost::filesystem;fs::path root_path(src_path);fs::recursive_directory_iterator end; // 递归遍历for (fs::recursive_directory_iterator iter(root_path); iter != end; iter++){if (iter->path().extension() != ".html"){continue;}fileName.push_back(iter->path().string());}
}void ReadContent(const std::vector<std::string> &fileName, std::vector<DocContent> &fileContent)
{for (const std::string s : fileName){std::string result;FileUtils::ReadFile(s, result);DocContent d;ParseTitle(result, d);ParseContent(result, d);ParseUrl(s, d);fileContent.push_back(std::move(d));}
};
上述两个函数就是用于遍历和数据清理的。这里讲一下一个c++11的语法:移动,下面的函数的std::move就是用了移动语法的一个函数
void ReadContent(const std::vector<std::string> &fileName, std::vector<DocContent> &fileContent)
{for (const std::string s : fileName){...DocContent d;...fileContent.push_back(std::move(d));}
};
本来d是一个临时变量,如果要push_back到一个vector,就要发生一次拷贝。这样开销就会比较大,因为d里面的字符串长度还是挺长的。
如果使用move函数,就可以让这个这个临时变量的内存空间的所有权转让给vector使用,这样就不需要拷贝了。
把处理好的数据都保存到一个.bin文件
读写文件用的是< fstream >中的ifstream和ofstream,具体参考链接
ifstream
ofstream
void SaveContent(const std::vector<DocContent> &fileContent)
{const std::string dst = "/home/mhq/boost_searcher/data/processed_data/process.txt";std::ofstream out(dst, std::ios::out | std::ios::binary);std::string s;for (auto &e : fileContent){s += e._title;s += '\3';s += e._content;s += '\3';s += e._url;s += '\n';}out << s;
};
这里我们采用了一个策略,每一个文档之间用\n来分割,文档内部的元素之间用\3来分割。
使用\n分割的原因:getline可以一次性把换行符之前的东西读入,这样我们每一次getline都可以读完一整个完整的文档
使用\3来分隔文档内部的原因:\3在ASCII码里是一个控制字符,普通html里不可能出现这个字符,所以加入\3不会影响文档内容原来的正确性
构建正排索引
正排索引就是给每个文档编号,这样我们就可以通过ID来找到对应的文档内容。单独的正排索引没什么用,它的作用是用来构建倒排索引。
索引其实就是一个vector,每一个元素是一个ForwardElem
class ForwardElem
{
public:DocContent _doc;//文档内容int _doc_id;ForwardElem() = default;
};
std::vector<ForwardElem> _forward_index; // 正排索引
我们之前已经把所有文档的去标签后的结果保存到一个文件里了,现在我们每一次getline都可以读出一整个文档的内容。并且在文档内加入了\3的分隔符。因此我们可以通过\3来把更具体的信息再挖掘出来。即标题,内容,url。
因此思路就是:
- 用\3分割字符串,构造一个文档内容
- 把这个文档内容放入正排索引的vector中
- 给这个文档内容编号
编号的逻辑很简单,vector里面有多少个元素,该文档的id就是多少
ForwardElem *BuildForwardIndex(const std::string &file){std::vector<std::string> subline;CutString(file, subline, '\3');ForwardElem t;t._doc = DocContent(subline[0], subline[1], subline[2]);if (subline.size() != 3){std::cout << "建立ForwardIndex失败,具体原因是分词失败" << std::endl;return nullptr;}t._doc_id = _forward_index.size();_forward_index.push_back(std::move(t));return &_forward_index.back();}
关于CutString这个函数怎么实现,可以使用boost库里面的split函数。
下面这个写法是网上copy的,照着写即可
void CutString(std::string line, std::vector<std::string> &subline, char a)
{boost::split(subline, line, boost::is_any_of("\3"), boost::token_compress_on);
}
构建倒排索引
倒排索引是通过关键词,我们可以返回具体的文档ID。因此我们要建立关键词和文档ID的关系。在一开始的关键问题已经说了,关系紧密的定义我们用关键字在文档中出现的次数和位置来衡量。 因此我们现在要开始分词了。只有先分词,我们才能知道关键字在文档中是否出现,出现几次等问题。
使用cpp-jieba分词
cppjieba安装和使用
这个库的使用有点小坑,得看这篇文章,不然无法正常编译过去
安装好之后作者会提供给你一个demo,把demo的代码复制过来就可以用了。
如下:
class Jieba
{
public:static cppjieba::Jieba jieba;static void CutString(const std::string &src, std::vector<std::string> &words);
};cppjieba::Jieba Jieba::jieba(DICT_PATH,HMM_PATH,USER_DICT_PATH,IDF_PATH,STOP_WORD_PATH);void Jieba::CutString(const std::string &s, std::vector<std::string> &words)
{jieba.CutForSearch(s, words);
}
计算每个文档中的每个词的权重
逻辑如下:
- 对文档中的标题,正文进行分词
- 统计标题的词频和正文的词频(哈希)
- weight = title_cnt * 10 + content_cnt
有一个点:对于每个词来讲,我们不需要区分大小写,boost库里面有一个函数可以把字符串都变成小写
void BuildInvertedIndex(const ForwardElem &ForwardElem){std::vector<std::string> titleWords, contentWords;Jieba::CutString(ForwardElem._doc._title, titleWords);Jieba::CutString(ForwardElem._doc._content, contentWords);std::unordered_map<std::string, Cnt> wordCnt;for (auto &e : titleWords){boost::to_lower(e);wordCnt[e]._title_cnt++;}for (auto &e : contentWords){boost::to_lower(e);wordCnt[e]._content_cnt++;}for (auto &e : wordCnt){InvertedElem invertedElem;invertedElem._doc_id = ForwardElem._doc_id;invertedElem._word = e.first;invertedElem._weight = e.second._title_cnt * 10 + e.second._content_cnt;_inverted_index[e.first].push_back(std::move(invertedElem));}}
对所有文档都进行上述的建立正排与倒排索引操作
逻辑:遍历每一个文档即可,之前已经用换行符对每一个文档进行了分割。因此现在每次getline都是一个文档。
void BuildIndex(const std::string &file)
{std::ifstream in(file, std::ios::in | std::ios::binary);std::string line;while (getline(in, line)){// 每一个换行符前都是整个文件ForwardElem *forwardElem = BuildForwardIndex(line);BuildInvertedIndex(*forwardElem);}std::cout << "索引已经建立完毕" << std::endl;
}
Search模块
到了这一步时数据准备部分已经完成了,现在要做的是返回数据的逻辑
逻辑如下:
- 先拿到用户提供的关键字,然后用jieba进行分词,拿到具体的关键字
- 用关键字去查倒排索引,得到要返回的文档的ID,并保存下它们的InvertedElem(里面存着weight,后面要根据weight来排序)
- 根据weight来排序InvertedElem
- 把前x个InvertedElem保存在Json串里
- 返回Json串
void Search(const std::string &key, std::string *json_reply)
{std::vector<std::string> words;Jieba::CutString(key, words);std::vector<InvertedElem> all;for (auto &e : words){std::vector<InvertedElem> *t = index->GetInvertedElem(e);if (!t){continue;}for (auto &e : *t){all.push_back(e);}}std::sort(all.begin(), all.end(), [](const InvertedElem &e1, const InvertedElem &e2){ return e1._weight > e2._weight; });all = std::vector<InvertedElem>(all.begin(), all.begin() + 10);Json::Value root;for (auto &e : all){ForwardElem *forwardElem = index->GetForwardElem(e._doc_id);if (forwardElem == nullptr)continue;Json::Value elem;DocContent docContent = forwardElem->_doc;elem["title"] = docContent._title;elem["content"] = GetDesc(docContent._content, e._word);elem["url"] = docContent._url;elem["weight"] = e._weight;elem["id"] = e._doc_id;root.append(elem);Json::StyledWriter writer;*json_reply = writer.write(root);}
}
关于jsoncpp的使用,参考这个链接
jsoncpp下载和简单使用
我这里直接用了apt install的方式下载jsoncpp,比较简答
http server模块
cpp-httplib
cpp-httplib的github
我使用的版本比较老,是0.7.15版本。文档内有说明如何调用接口
拿参,并且调用我们的search返回我们的json串
关于如何使用cpp-httplib看是否有参数并且拿到参数,可以参考文档中的这个demo
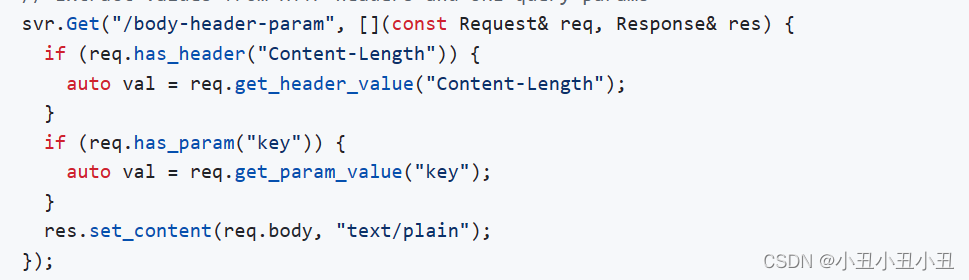
因此我们只需要编写这个逻辑即可
- 准备好数据部分,启动searcher
- 拿参
- 把参数放入search函数中,得到返回的json
- 把json返回给用户
Searcher search;
search.InitSearcher(datas);
httplib::Server svr;svr.Get("/s", [&](const httplib::Request &request, httplib::Response &response){if (!request.has_param("word")){response.set_content("请输入搜索内容", "text/plain: charset=utf-8");return;}string word = request.get_param_value("word");string json_str;search.Search(word, &json_str);response.set_content(json_str, "application/json"); });svr.listen("0.0.0.0", 8081);
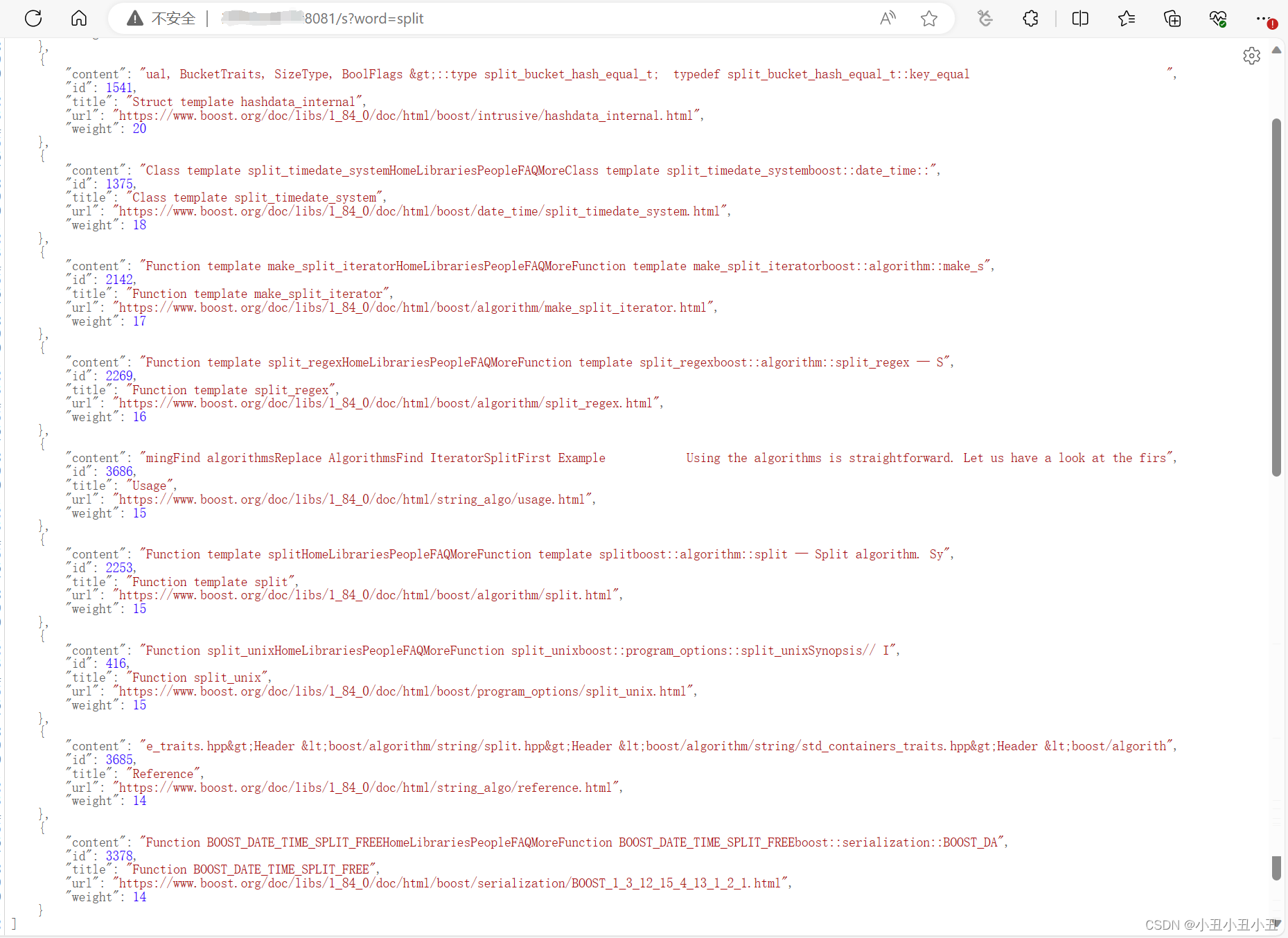
最终结果
可以成功返回结果,后序可以编写前端,完善界面
这篇关于C++实现网站内搜索功能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







