本文主要是介绍Python爬虫爬取51job招聘网站,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近学习爬虫,做了一个python爬虫工具写在这里记录一下。
# python爬51job工具,稍微改改就可以爬其他网站
# edit by mengqi Date:2018-07-11
# encoding:uft-8import csv # 爬下来的数据要写到csv文件中,所以要引入这个模块
from urllib import request, error
from lxml import etree # 元素树用来进行xpath语法解析时,
import random # 这里我构造了五个浏览器的user-agent,防止被检测出来# 1. get_html()这个函数是将给定url和encode方式,返回为html的字符串形式
def get_html(url,encode='utf-8'):try:ua_value1 = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) " \"Gecko/20100101 Firefox/61.0"ua_value2 = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 ' \'(KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'ua_value3 = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 ' \'(KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11'ua_value4 = 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US)' \' AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16'ua_value5 = 'Mozilla/5.0 (Windows NT 6.1; WOW64)' \' AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'# 创建user-agent集合,模拟浏览器登陆ua = (ua_value1, ua_value2, ua_value3, ua_value4, ua_value5) # 元组里面的东西不能随便被修改req = request.Request(url) # 3.构建爬虫请求对象req.add_header("User-Agent", random.choice(ua)) # 4.在请求头中添加Uer-Agentresponse = request.urlopen(req) # 5.发送请求并获取服务器的响应对象responsehtml_str2 = response.read().decode(encode) # 6.从响应对象中读取网页中的源码(响应正文)except error.URLError: # 抛异常,如果是url错误的话执行这个print('url 请求错误')except error.HTTPError:print('请求错误')except Exception:print('程序错误')return html_str2def crawl_onepage(html_str1): # 这个方法用来将获取到的str格式的html进行xpath解析到rows这个列表中html_ = etree.HTML(html_str1) # 将html字符串结构转换成html文档结构html = etree.ElementTree(html_) # 将html文档结构转换成元素树结构# 使用xpath语法进行数据清洗div_el = html.xpath('//div[@id="resultList"]/div[@class="el"]') # 获取id=“resultlist‘ 内所有的class=’el‘的div,div的列表rows = list()# 通过for循环寻找每一行el数据for index, el in enumerate(div_el): # el数据类型是html文档类型el = etree.ElementTree(el) # 同上:需要将html文档结构再转换成元素树的格式(节点)title = el.xpath('/div/p/span/a/@title') # 职位名title = title[0] if title else Nonelink = el.xpath('/div/p/span/a/@href') # 进入详情页的地址link = link[0] if link else None company = el.xpath('/div/span[@class="t2"]/a/@title') # 公司company = company[0] if company else Nonecity = el.xpath('/div/span[@class="t3"]/text()') # 工作地点city = city[0] if city else Nonesalary = el.xpath('/div/span[@class="t4"]/text()') # 薪水salary = salary[0] if salary else Nonetime = el.xpath('/div/span[@class="t5"]/text()') # 发布时间time = time[0] if time else Nonechild_str = get_html(link, 'gbk')child_ = etree.HTML(child_str)child = etree.ElementTree(child_) # 元素树(只有节点才能使用xpath语法)exp = child.xpath('//div[@class="jtag inbox"]/div/span/em[@class="i1"]/parent::span/text()')exp = exp[0] if exp else Nonedegree = child.xpath('//div[@class="jtag inbox"]/div/span/em[@class="i2"]/parent::span/text()')degree = degree[0] if degree else Nonefuli = child.xpath('//div[@class="jtag inbox"]/p/span/text()')fuli = fuli if fuli else None # 福利就是一个列表,需要将列表转成字符串row = (title, company, city, salary, time, exp, degree, fuli) # 将每一行数据封装到元祖中# print(row)rows.append(row) # 每次获取到的职位相关信息,放入到空列表中return rowsdef csv_write(filename,mode,content): # 用于写入csv文件的方法with open(filename, mode, newline ="",encoding ='utf-8') as job: # 用指定的mode方式打开filename文件,指定了编码格式file = csv.writer(job)if mode == 'w': # 写的方式,覆盖写file.writerow(content)if mode == 'a': #append方式写,不覆盖file.writerows(content)def crawl_manypage(keyword,start,end): # 爬取多页数据,第一个参数表示关键字,第二个是开始页,第三个是结束页head = ('职位', '公司', '工作地点', '薪资', '发布时间', '工作经验', '学历', '福利') # 第一行数据表头csv_write('{}.csv'.format(keyword), 'w', head) # 调用刚才的csv_write方法for page in range(start, end+1): # page变量是页数url1 = 'https://search.51job.com/list/010000,000000,0000,00,9,99,{},2,{}.html?' \'lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99' \'&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=' \'&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='.format(keyword,page)html_str = get_html(url1,'gbk') # 按照gbk的编码格式获取html字符串rows = crawl_onepage(html_str) # 调用函数爬取一页数据csv_write('{}.csv'.format(keyword), 'a', rows) # 写入到csv文件中
# 51job通过协程实现并发爬虫
crawl_manypage('python',1,3)然后打开pycharm中的python.csv文件右键选择file encoding,选择gbk,就可以用excel打开看到了:
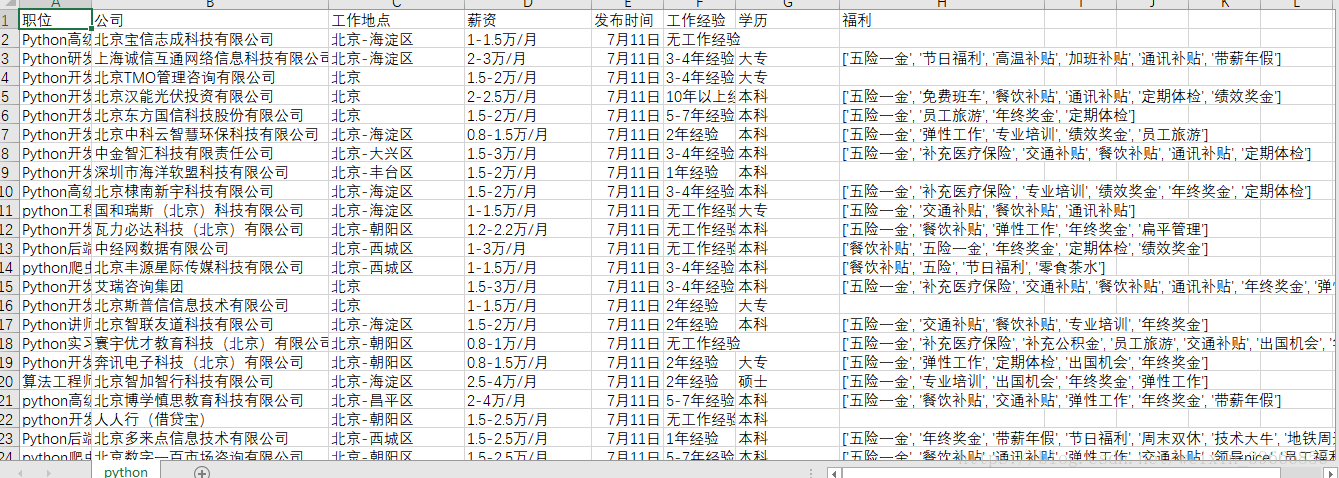
下一篇会对这个爬虫进行优化,并将爬虫结果做简要分析
这篇关于Python爬虫爬取51job招聘网站的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





