本文主要是介绍OpenMMlab导出PointPillars模型并用onnxruntime推理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
导出onnx文件
通过mmdeploy的tool/deploy.py脚本容易转换得到PointPillars的end2end.onnx模型。
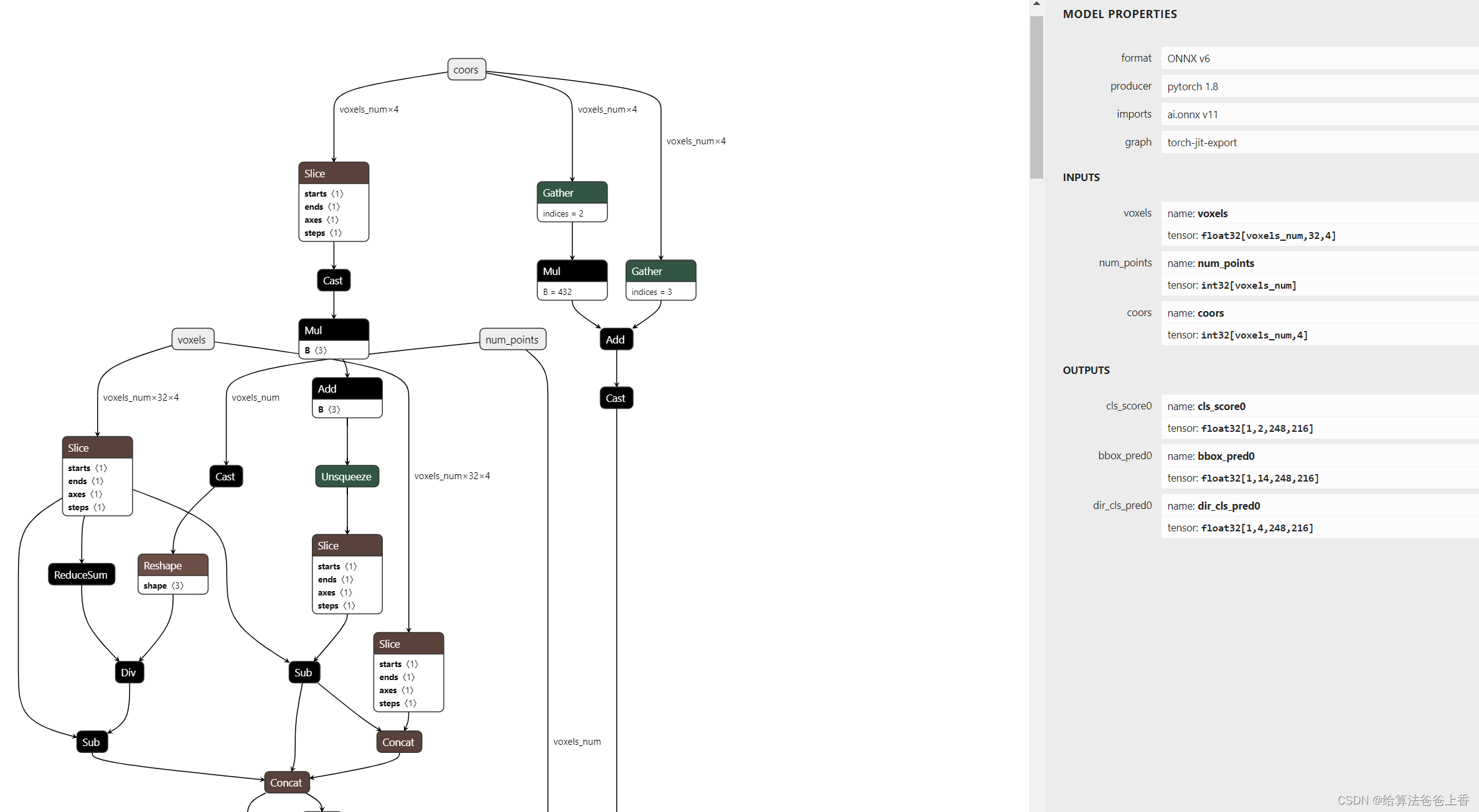
根据https://github.com/open-mmlab/mmdeploy/blob/main/docs/zh_cn/04-supported-codebases/mmdet3d.md显示,截止目前 mmdet3d 的 voxelize 预处理和后处理未转成 onnx 操作;C++ SDK 也未实现 voxelize 计算。
onnxruntime推理
需要安装mmdetection3d等包:
import torch
import onnxruntime
import numpy as np
from torch.nn import functional as F
from mmdet3d.apis import init_model, inference_detector
from mmcv.ops import nms, nms_rotated
from ops.voxel_module import Voxelization
from ops.iou3d_op import nms_gpuconfig_file = 'pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py'
checkpoint_file = 'hv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20220331_134606-d42d15ed.pth'class PointPillars(torch.nn.Module):def __init__(self):super().__init__()self.model = init_model(config_file, checkpoint_file, device='cpu')self.box_code_size = 7self.num_classes = 1self.nms_pre = 100self.max_num = 50self.score_thr = 0.1self.nms_thr = 0.01self.voxel_layer = Voxelization(voxel_size= [0.16, 0.16, 4], point_cloud_range=[0, -39.68, -3, 69.12, 39.68, 1], max_num_points=32, max_voxels=[16000, 40000])self.mlvl_priors = self.model.bbox_head.prior_generator.grid_anchors([torch.Size([248, 216])])self.mlvl_priors = [prior.reshape(-1, self.box_code_size) for prior in self.mlvl_priors]def pre_process(self, x):res_voxels, res_coors, res_num_points = self.voxel_layer(x)return res_voxels, res_coors, res_num_pointsdef xywhr2xyxyr(self, boxes_xywhr):boxes = torch.zeros_like(boxes_xywhr)half_w = boxes_xywhr[..., 2] / 2half_h = boxes_xywhr[..., 3] / 2boxes[..., 0] = boxes_xywhr[..., 0] - half_wboxes[..., 1] = boxes_xywhr[..., 1] - half_hboxes[..., 2] = boxes_xywhr[..., 0] + half_wboxes[..., 3] = boxes_xywhr[..., 1] + half_hboxes[..., 4] = boxes_xywhr[..., 4]return boxesdef box3d_multiclass_nms(self, mlvl_bboxes, mlvl_bboxes_for_nms, mlvl_scores, mlvl_dir_scores):num_classes = mlvl_scores.shape[1] - 1bboxes = []scores = []labels = []dir_scores = []for i in range(0, num_classes):cls_inds = mlvl_scores[:, i] > self.score_thrif not cls_inds.any():continue_scores = mlvl_scores[cls_inds, i]_bboxes_for_nms = mlvl_bboxes_for_nms[cls_inds, :].cuda()keep = torch.zeros(_bboxes_for_nms.size(0), dtype=torch.long)num_out = nms_gpu(_bboxes_for_nms.cuda(), keep, self.nms_thr, _bboxes_for_nms.device.index)selected = keep[:num_out]bboxes.append(mlvl_bboxes[selected])scores.append(_scores[selected])cls_label = mlvl_bboxes.new_full((len(selected), ), i, dtype=torch.long)labels.append(cls_label)dir_scores.append(mlvl_dir_scores[selected])if bboxes:bboxes = torch.cat(bboxes, dim=0)scores = torch.cat(scores, dim=0)labels = torch.cat(labels, dim=0)dir_scores = torch.cat(dir_scores, dim=0)if bboxes.shape[0] > self.max_num:_, inds = scores.sort(descending=True)inds = inds[:self.max_num]bboxes = bboxes[inds, :]labels = labels[inds]scores = scores[inds]dir_scores = dir_scores[inds]else:bboxes = mlvl_scores.new_zeros((0, mlvl_bboxes.size(-1)))scores = mlvl_scores.new_zeros((0, ))labels = mlvl_scores.new_zeros((0, ), dtype=torch.long)dir_scores = mlvl_scores.new_zeros((0, ))return (bboxes, scores, labels, dir_scores)def decode(self, anchors, deltas):xa, ya, za, wa, la, ha, ra = torch.split(anchors, 1, dim=-1)xt, yt, zt, wt, lt, ht, rt = torch.split(deltas, 1, dim=-1)za = za + ha / 2diagonal = torch.sqrt(la**2 + wa**2)xg = xt * diagonal + xayg = yt * diagonal + yazg = zt * ha + zalg = torch.exp(lt) * lawg = torch.exp(wt) * wahg = torch.exp(ht) * harg = rt + razg = zg - hg / 2return torch.cat([xg, yg, zg, wg, lg, hg, rg], dim=-1)def predict_by_feat_single(self, cls_score, bbox_pred, dir_cls_pred):priors = self.mlvl_priors[0]dir_cls_pred = dir_cls_pred.permute(1, 2, 0).reshape(-1, 2)dir_cls_scores = torch.max(dir_cls_pred, dim=-1)[1]cls_score = cls_score.permute(1, 2, 0).reshape(-1, self.num_classes)scores = cls_score.sigmoid()bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, self.box_code_size) max_scores, _ = scores.max(dim=1)_, topk_inds = max_scores.topk(self.nms_pre) priors = priors[topk_inds, :].cpu()bbox_pred = bbox_pred[topk_inds, :]scores = scores[topk_inds, :]dir_cls_scores = dir_cls_scores[topk_inds]bboxes = self.decode(priors, bbox_pred)mlvl_bboxes_bev = torch.cat([bboxes[:, 0:2], bboxes[:, 3:5], bboxes[:, 5:6]], dim=1)mlvl_bboxes_for_nms = self.xywhr2xyxyr(mlvl_bboxes_bev) padding = scores.new_zeros(scores.shape[0], 1)scores = torch.cat([scores, padding], dim=1) results = self.box3d_multiclass_nms(bboxes, mlvl_bboxes_for_nms, scores, dir_cls_scores)bboxes, scores, labels, dir_scores = resultsif bboxes.shape[0] > 0: dir_rot = bboxes[..., 6] + np.pi/2 - torch.floor(bboxes[..., 6] + np.pi/2 / np.pi ) * np.pibboxes[..., 6] = (dir_rot - np.pi/2 + np.pi * dir_scores.to(bboxes.dtype)) return bboxes, scores, labelsdef forward(self, res_voxels, res_coors, res_num_points): voxels, coors, num_points = [], [], []res_coors = F.pad(res_coors, (1, 0), mode='constant', value=0)voxels.append(res_voxels)coors.append(res_coors)num_points.append(res_num_points)voxels = torch.cat(voxels, dim=0)coors = torch.cat(coors, dim=0)num_points = torch.cat(num_points, dim=0)x = self.model.voxel_encoder(voxels, num_points, coors) x = self.model.middle_encoder(x, coors, batch_size=1) x = self.model.backbone(x)x = self.model.neck(x) cls_scores, bbox_preds, dir_cls_preds = self.model.bbox_head(x) return cls_scores[0], bbox_preds[0], dir_cls_preds[0]points = np.fromfile('demo/data/kitti/000008.bin', dtype=np.float32)
points = torch.from_numpy(points.reshape(-1, 4)) voxel_layer = Voxelization(voxel_size= [0.16, 0.16, 4], point_cloud_range=[0, -39.68, -3, 69.12, 39.68, 1], max_num_points=32, max_voxels=[16000, 40000])
res_voxels, res_coors, res_num_points = voxel_layer(points)
res_coors = torch.cat([torch.zeros([res_coors.shape[0], 1]), res_coors], axis=1)onnx_session = onnxruntime.InferenceSession("../work_dir/onnx/pointpillars/end2end.onnx", providers=['CPUExecutionProvider'])input_name = []
for node in onnx_session.get_inputs():input_name.append(node.name)output_name = []
for node in onnx_session.get_outputs():output_name.append(node.name)inputs = {}
inputs['voxels'] = res_voxels.numpy()
inputs['num_points'] = res_num_points.type(torch.int32).numpy()
inputs['coors'] = res_coors.type(torch.int32).numpy()outputs = onnx_session.run(None, inputs)
cls_score = torch.from_numpy(outputs[0][0])
bbox_pred = torch.from_numpy(outputs[1][0])
dir_cls_pred = torch.from_numpy(outputs[2][0])pointpillars = PointPillars()
result = pointpillars.predict_by_feat_single(cls_score, bbox_pred, dir_cls_pred)
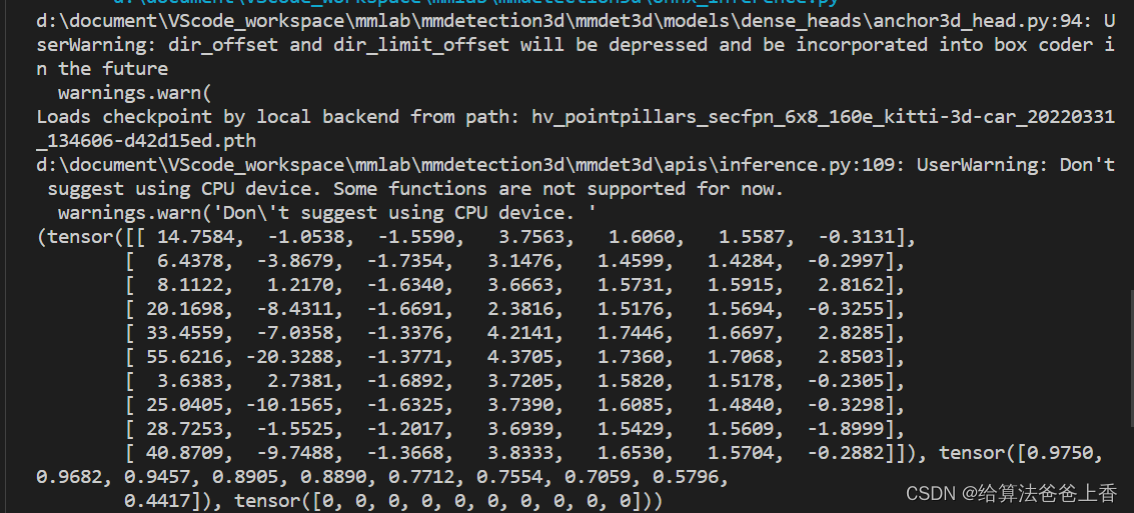
print(result)
其中ops包来自:https://github.com/zhulf0804/PointPillars/tree/main/ops
结果输出:
这篇关于OpenMMlab导出PointPillars模型并用onnxruntime推理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






