本文主要是介绍同花顺Supermind量化交易 风险控制建模-Fama-French三因子模型应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在CAPM模型的基础上,再向大家讲述Fama-French的三因子模型,并构建策略,实际应用于A股市场。
import pandas as pd
import numpy as np
from sklearn import linear_model
# 初始化函数,全局只运行一次
def init(context):g.bstk = '399006.SZ' #设置指数set_benchmark(g.bstk)#设置基准指数g.day = 0 #记录运行天数g.tradeday = 20 #调仓频率g.stock = [] #储存上期的股票池g.trade = False #是否调仓的开关g.longday = 252 #样本长度g.stocknum = 20 #持仓数量pass#每日开盘前9:00被调用一次,用于储存自定义参数、全局变量,执行盘前选股等
def before_trading(context):#判断是否调仓if g.day%g.tradeday==0:g.trade=Trueelse:g.trade=Falseg.day=g.day+1## 开盘时运行函数
def handle_bar(context, bar_dict):if g.trade==True:#获取选股结果needstock_list = alpha_FF()#获取上期持仓个股holdstock_list = list(g.stock)#确定本期需要卖出的个股sell_list = list(set(holdstock_list)-set(needstock_list))#执行卖出操作,运用for循环,逐个操作。for s in sell_list:order_target(s,0)#确定本期需要买入的个股,其余即为继续持仓的个股buy_list=[]for i in needstock_list:if i in holdstock_list:passelse:buy_list.append(i)#确定可用资金,平分分配至需买入的个股n=len(buy_list)cash=context.portfolio.available_cash/n#执行买入操作for s in range(0,n,1):stock=list(buy_list)[s]order_value(stock,cash)#操作完毕,将选股结果放到上期股票池储存变量中,以备下次使用。g.stock = frozenset(needstock_list)else:pass
#=================获取股票池==================================
def stock(yestoday,today): #要的是过去交易日的股票池,但换仓日不应该停牌stk2=list(get_index_stocks(g.bstk,yestoday))#过去的stk=list(get_index_stocks(g.bstk,today))#换仓日的#获取换仓日的股票再换仓日的ST和停牌情况price=get_price(stk, None, today, '1d', ['is_paused', 'is_st'], False, None, 1, is_panel=1)stopstk=price['is_paused'].iloc[-1]ststk=price['is_st'].iloc[-1]startstk=(stopstk[stopstk==0].index)okstk=(ststk[ststk==0].index)tradestk=list(set(startstk)&set(okstk)&set(stk2))#符合不停牌非ST和过去交易日的沪深300成分股return tradestk#==========================获取当天交易日的前N个交易日的日期
def tradeday(today,n):daylist=list(get_all_trade_days().strftime('%Y%m%d'))calnum = daylist.index(today)#获取今日日期在整个月历中的序lasttrade=daylist[calnum-n]#去前N个序的交易日return lasttrade
#==========================alpha计算函数=========================
def alpha_FF():today=get_last_datetime().strftime('%Y%m%d')#获取当天日期 格式YMD#获取前N个交易日的日期ldate=tradeday(today,g.longday)stock_list = stock(ldate,today) #获取交易股票列表stock_num = int(len(stock_list)*0.2)#查询市值、所有者权益数据q = query(valuation.symbol,valuation.market_cap,balance.total_equity).filter(valuation.symbol.in_(stock_list),)basic = get_fundamentals(q, date = ldate)basic['B/M']= basic['balance_total_equity']/basic['valuation_market_cap']ret=get_price(stock_list, None, today, '1d', ['quote_rate'], False, 'pre', g.longday, is_panel=1)['quote_rate']ret=ret/100ret_jz=get_price(g.bstk, None, today, '1d', ['quote_rate'], False, 'pre', g.longday, is_panel=1)['quote_rate']ret_jz=ret_jz/100-0.04/252df=pd.DataFrame()df['Rm']=ret_jzbasic.index=basic['valuation_symbol']del basic['balance_total_equity']for i in ['valuation_market_cap','B/M']:basic = pd.DataFrame(basic).sort_values(by =i, ascending=False)stockmax=list(basic.iloc[:stock_num]['valuation_symbol'])stockmin=list(basic.iloc[-stock_num:]['valuation_symbol'])df[i]=np.mean(ret[stockmin].T)-np.mean(ret[stockmax].T)ret=ret-0.04/252df.columns=['RM','SMB','HML']clf = linear_model.LinearRegression()#数据无法获取导致的,处理后的nan使其为0ret.iloc[:] = ret.iloc[:].fillna(0)df.iloc[:] = df.iloc[:].fillna(0)#对三因子进行线性回归x_list=['RM','SMB','HML']df2=pd.DataFrame(index=['alpha'])for i in ret.columns:y = ret[i].valuesx = df[x_list].valuesclf.fit(x,y)df2[i]=clf.coef_[0]df2=df2.Tdf2 = pd.DataFrame(df2).sort_values(by ='alpha', ascending=True)#获取股票的代码needstock_list=[]for s in range(0,g.stocknum,1):needstock_list.append(list(df2.index)[s])return needstock_list
第九篇:Fama-French三因子模型应用
导语:在CAPM模型的基础上,再向大家讲述Fama-French的三因子模型,并构建策略,实际应用于A股市场。
一、策略阐述
Fama-French三因子模型由来
Fama和French在研究股票超额收益率时,提出了一个观点:小公司股票、以及具有较高股权账面-市值比的股票,其历史平均收益率一般会高于CAPM模型所预测的收益率。
Fama和French认为:1.市值较小的公司通常规模比较小,公司整体风险更大,需要获得更高的收益来补偿投资者;2.账面市值比是账面的所有者权益除以市值,简称BM。BM效应是指账面市值比效应,指BM值较高的公司平均月收益率高于BM值较低的公司。
关于BM效应,国内外学者已做了许多研究。Fama和French(1992)研究了1963到1990年所有在NYSE、AMEX、NASDAQ上市的股票,发现BM值最高的组合月均收益率超过BM值最低的组合达1.53%。肖军,徐信忠(2004)以1993年6月至2001年6月沪深股市A股股票为样本,计算持有一年、两年、三年的收益率数据,认为BM效应存在。
模型介绍
顾名思义,Fama-French三因子模型中包含三个因子:市值因子(SMB)、账面市值比因子(HML)、市场风险因子(RM)。三因子模型的本质就是把CAPM中的未被解释的超额收益分解掉,将其分解成SMB、BM、RM和其他未能解释的因素(a),公式表达即为
Ri=ai+biRM+siE(SMB)+hiE(HML)+εi
其中:
Ri=E(ri−rf),指股票i比起无风险投资的期望超额收益率。
RM=E(rM−rf),为市场相对无风险投资的期望超额收益率。
E(SMB)是小市值公司相对大市值公司股票的期望超额收益率。
E(HML)则是高B/M公司股票比起低B/M的公司股票的期望超额收益率。
a即观测值,线性回归的常数项。
εi是回归残差项。
E(SMB)的计算方式如下:把市场里面的所有股票按市值排序,随后分成两份:第一份是大市值股票(市值前20%的股票),第二份是小市值股票(市值后20%的股票)。记大市值股票的平均期望收益率为E(rS),小市值股票的期望收益率为E(rB)。那么E(SMB)=E(rS)−E(rB)。E(HML)的定义也类似。
假设三因子模型是正确的,市场风险、市值风险、账面市值比这三类风险能很好地解释个股的超额收益,那么a的长期均值应该是0。如果短期内对于某个时期的股票,回归得到a < 0,说明这段时间个股收益率偏低。根据有效市场假设,任何非理性的价格最终都会回归理性,这些短期内收益率偏低的个股,最终都会涨回去。
Fama-French三因子模型实际应用
考虑到三因子模型主要偏向小市值个股,因此本篇内容创业板指数为基准指数,来向大家展示三因子模型。
策略交易规则:
A.设置调仓频率,每20个交易日进行调仓。
B.设置样本长度,用于线性回归,考虑到模型观测值a长期为0,因此选取了过去252个交易日的样本数据。
C.持仓数量为a值最小的20只股票。
策略选股:
第一步:调仓日对于过去252个交易日的数据进行回归分析,自变量为:RM、E(SMB)、E(HML),应变量为Ri,每个股票的回归结果取常数项,即为a值。
第二步:选出α最小的20支股票。
以下为策略实现的基本信息:
策略实现难度:4
实现过程中所需要用到的API函数,ps:通过SuperMind量化交易平台API文档快速掌握:
| 需要用到的API函数 | 功能 |
|---|---|
| set_benchmark() | 设置基准指数 |
| order_value() | 按金额下单 |
| get_index_stocks() | 获取指数成分股 |
| get_all_trade_days() | 获取所有交易日 |
| get_price() | 获取历史行情数据 |
| get_candle_stick() | 获取股票、指数、基金的历史行情数据,包括分钟级、日级、周级、月级、年级数据 |
| get_last_datetime() | 获取前一个交易日或者前一分钟的时间 |
| get_fundamentals() | 查询财务数据 |
| context.portfolio.available_cash | 账户当前可用资金 |
| g. | 全局变量g |
二、代码示意图

三、编写释义
三因子模型的核心部分是计算因子值和因子线性回归,建议初学者前往研究环境操作。
因子值的计算完毕后需整理成一个DataFrame格式,以便后续进行因子回归,该部分操作需要同学们熟悉DataFrame的常用操作,以下是作者实现三因子模型中,研究环境的代码草稿,分享给同学们。
以下代码可在SuperMind研究环境中模仿学习:
In [1]:
import pandas as pd
import numpy as np
from sklearn import linear_model
def stock(date): #以沪深300为股票池,除去ST和停牌stk=list(get_index_stocks('000300.SH',date))price=get_price(stk, None, date, '1d', ['is_paused', 'is_st'], False, None, 1, is_panel=1)stopstk=price['is_paused'].iloc[-1]ststk=price['is_st'].iloc[-1]startstk=(stopstk[stopstk==0].index)okstk=(ststk[ststk==0].index)tradestk=list(set(startstk)&set(okstk))return tradestk
#==========================获取当天交易日的前N个交易日的日期
def tradeday(today,n):daylist=list(get_all_trade_days().strftime('%Y%m%d'))calnum = daylist.index(today)#获取今日日期在整个月历中的序lasttrade=daylist[calnum-n]#去前N个序的交易日return lasttradetoday='20180131'
ldate=tradeday(today,60)
stock_list = stock(ldate) #获取交易股票列表
stock_num = int(len(stock_list)*0.2)
#查询市值、所有者权益数据
q = query(valuation.symbol,valuation.market_cap,balance.total_equity).filter(valuation.symbol.in_(stock_list),)
basic = get_fundamentals(q, date = ldate)
basic['B/M']= basic['balance_total_equity']/basic['valuation_market_cap']
ret=get_price(stock_list, None, today, '1d', ['quote_rate'], False, 'pre', 60, is_panel=1)['quote_rate']
ret=ret/100
ret_jz=get_price('000300.SH', None, today, '1d', ['quote_rate'], False, 'pre', 60, is_panel=1)['quote_rate']
ret_jz=ret_jz/100-0.04/252
df=pd.DataFrame()
df['Rm']=ret_jz
basic.index=basic['valuation_symbol']
del basic['balance_total_equity']
for i in ['valuation_market_cap','B/M']:basic = pd.DataFrame(basic).sort_values(by =i, ascending=False)stockmax=list(basic.iloc[:stock_num]['valuation_symbol'])stockmin=list(basic.iloc[-stock_num:]['valuation_symbol'])df[i]=np.mean(ret[stockmin].T)-np.mean(ret[stockmax].T)
ret=ret-0.04/252
df.columns=['RM','SMB','HML']
clf = linear_model.LinearRegression()
#数据无法获取导致的,处理后的nan使其为0
ret.iloc[:] = ret.iloc[:].fillna(0)
df.iloc[:] = df.iloc[:].fillna(0)
#对三因子进行线性回归
x_list=['RM','SMB','HML']
df2=pd.DataFrame(index=['alpha'])
for i in ret.columns:y = ret[i].valuesx = df[x_list].valuesclf.fit(x,y)df2[i]=clf.coef_[0]
df2=df2.T
df2 = pd.DataFrame(df2).sort_values(by ='alpha', ascending=True)
df2.iloc[:10]Out[1]:
| alpha | |
|---|---|
| 601899.SH | -0.212891 |
| 600256.SH | 0.007857 |
| 600157.SH | 0.024868 |
| 002252.SZ | 0.031996 |
| 000793.SZ | 0.104336 |
| 002411.SZ | 0.124312 |
| 600900.SH | 0.154995 |
| 002424.SZ | 0.216433 |
| 600816.SH | 0.221688 |
| 600518.SH | 0.250694 |
四、最终结果
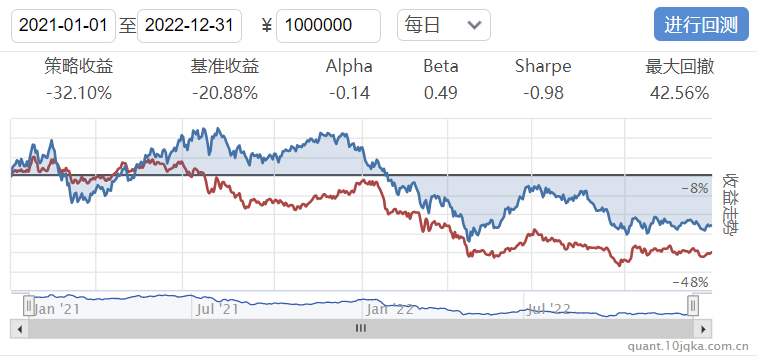
策略回测区间:2021.01.01-2022.12.31
回测资金:1000000
回测频率:日级
回测结果:红色曲线为策略收益率曲线,蓝色曲线为对应的基准指数收益率曲线
策略源代码:
In [ ]:
import pandas as pd
import numpy as np
from sklearn import linear_model
# 初始化函数,全局只运行一次
def init(context):g.bstk = '399006.SZ' #设置指数set_benchmark(g.bstk)#设置基准指数g.day = 0 #记录运行天数g.tradeday = 20 #调仓频率g.stock = [] #储存上期的股票池g.trade = False #是否调仓的开关g.longday = 252 #样本长度g.stocknum = 20 #持仓数量pass#每日开盘前9:00被调用一次,用于储存自定义参数、全局变量,执行盘前选股等
def before_trading(context):#判断是否调仓if g.day%g.tradeday==0:g.trade=Trueelse:g.trade=Falseg.day=g.day+1## 开盘时运行函数
def handle_bar(context, bar_dict):if g.trade==True:#获取选股结果needstock_list = alpha_FF()#获取上期持仓个股holdstock_list = list(g.stock)#确定本期需要卖出的个股sell_list = list(set(holdstock_list)-set(needstock_list))#执行卖出操作,运用for循环,逐个操作。for s in sell_list:order_target(s,0)#确定本期需要买入的个股,其余即为继续持仓的个股buy_list=[]for i in needstock_list:if i in holdstock_list:passelse:buy_list.append(i)#确定可用资金,平分分配至需买入的个股n=len(buy_list)cash=context.portfolio.available_cash/n#执行买入操作for s in range(0,n,1):stock=list(buy_list)[s]order_value(stock,cash)#操作完毕,将选股结果放到上期股票池储存变量中,以备下次使用。g.stock = frozenset(needstock_list)else:pass
#=================获取股票池==================================
def stock(yestoday,today): #要的是过去交易日的股票池,但换仓日不应该停牌stk2=list(get_index_stocks(g.bstk,yestoday))#过去的stk=list(get_index_stocks(g.bstk,today))#换仓日的#获取换仓日的股票再换仓日的ST和停牌情况price=get_price(stk, None, today, '1d', ['is_paused', 'is_st'], False, None, 1, is_panel=1)stopstk=price['is_paused'].iloc[-1]ststk=price['is_st'].iloc[-1]startstk=(stopstk[stopstk==0].index)okstk=(ststk[ststk==0].index)tradestk=list(set(startstk)&set(okstk)&set(stk2))#符合不停牌非ST和过去交易日的沪深300成分股return tradestk#==========================获取当天交易日的前N个交易日的日期
def tradeday(today,n):daylist=list(get_all_trade_days().strftime('%Y%m%d'))calnum = daylist.index(today)#获取今日日期在整个月历中的序lasttrade=daylist[calnum-n]#去前N个序的交易日return lasttrade
#==========================alpha计算函数=========================
def alpha_FF():today=get_last_datetime().strftime('%Y%m%d')#获取当天日期 格式YMD#获取前N个交易日的日期ldate=tradeday(today,g.longday)stock_list = stock(ldate,today) #获取交易股票列表stock_num = int(len(stock_list)*0.2)#查询市值、所有者权益数据q = query(valuation.symbol,valuation.market_cap,balance.total_equity).filter(valuation.symbol.in_(stock_list),)basic = get_fundamentals(q, date = ldate)basic['B/M']= basic['balance_total_equity']/basic['valuation_market_cap']ret=get_price(stock_list, None, today, '1d', ['quote_rate'], False, 'pre', g.longday, is_panel=1)['quote_rate']ret=ret/100ret_jz=get_price(g.bstk, None, today, '1d', ['quote_rate'], False, 'pre', g.longday, is_panel=1)['quote_rate']ret_jz=ret_jz/100-0.04/252df=pd.DataFrame()df['Rm']=ret_jzbasic.index=basic['valuation_symbol']del basic['balance_total_equity']for i in ['valuation_market_cap','B/M']:basic = pd.DataFrame(basic).sort_values(by =i, ascending=False)stockmax=list(basic.iloc[:stock_num]['valuation_symbol'])stockmin=list(basic.iloc[-stock_num:]['valuation_symbol'])df[i]=np.mean(ret[stockmin].T)-np.mean(ret[stockmax].T)ret=ret-0.04/252df.columns=['RM','SMB','HML']clf = linear_model.LinearRegression()#数据无法获取导致的,处理后的nan使其为0ret.iloc[:] = ret.iloc[:].fillna(0)df.iloc[:] = df.iloc[:].fillna(0)#对三因子进行线性回归x_list=['RM','SMB','HML']df2=pd.DataFrame(index=['alpha'])for i in ret.columns:y = ret[i].valuesx = df[x_list].valuesclf.fit(x,y)df2[i]=clf.coef_[0]df2=df2.Tdf2 = pd.DataFrame(df2).sort_values(by ='alpha', ascending=True)#获取股票的代码needstock_list=[]for s in range(0,g.stocknum,1):needstock_list.append(list(df2.index)[s])return needstock_list查看以上策略详细请 到 supermind量化交易官网查看:风险控制建模-Fama-French三因子模型应用
这篇关于同花顺Supermind量化交易 风险控制建模-Fama-French三因子模型应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





