本文主要是介绍机器学习-基于Word2vec搜狐新闻文本分类实验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
机器学习-基于Word2vec搜狐新闻文本分类实验
实验介绍
Word2vec是一群用来产生词向量的相关模型,由Google公司在2013年开放。Word2vec可以根据给定的语料库,通过优化后的训练模型快速有效地将一个词语表达成向量形式,为自然语言处理领域的应用研究提供了新的工具。
Word2vec模型为浅而双层的神经网络,网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
实验要求
本实验主要基于Word2vec来实现对搜狐新闻文本分类,大致步骤如下。
1.数据准备
数据集下载地址 密码: hq5v
训练集共有24000条样本,12个分类,每个分类2000条样本。
测试集共有12000条样本,12个分类,每个分类1000条样本。
2.word2vec模型(可以使用Word2Vec原代码库)
完成此步骤需要先安装gensim库,安装命令:pip install gensim
3.特征工程
对于每一篇文章,获取文章的每一个分词在word2vec模型的相关性向量。然后把一篇文章的所有分词在word2vec模型中的相关性向量求和取平均数,即此篇文章在word2vec模型中的相关性向量。
实验代码及结果展示
import pandas as pd
import jieba
import time
from gensim.models import Word2Vec
import warnings
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
train_df.head()
for name, group in train_df.groupby(0):print(name,len(group))test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
for name, group in test_df.groupby(0):print(name, len(group))train_df.columns = ['分类', '文章']
stopword_list = [k.strip() for k in open('stopwords.txt', encoding='utf8').readlines() if k.strip() != '']
cutWords_list = []
i = 0
startTime = time.time()
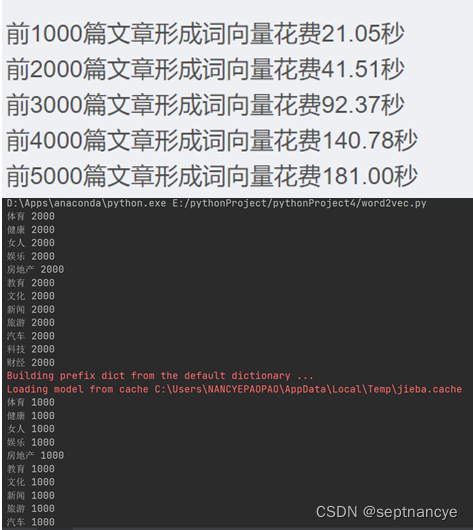
for article in train_df['文章']:cutWords = [k for k in jieba.cut(article) if k not in stopword_list]i += 1if i % 1000 == 0:print('前%d篇文章分词共花费%.2f秒' % (i, time.time() - startTime))cutWords_list.append(cutWords)with open('cutWords_list.txt', 'w') as file:for cutWords in cutWords_list:file.write(' '.join(cutWords) + '\n')with open('cutWords_list.txt') as file:cutWords_list = [k.split() for k in file.readlines()]word2vec_model = Word2Vec(cutWords_list, size=100, iter=10, min_count=20)warnings.filterwarnings('ignore')word2vec_model.wv.most_similar('摄影')word2vec_model.most_similar(positive=['女人', '先生'], negative=['男人'], topn=1)word2vec_model.save('word2vec_model.w2v')
import numpy as np
import time def getVector_v1(cutWords, word2vec_model):count = 0article_vector = np.zeros(word2vec_model.layer1_size)for cutWord in cutWords:if cutWord in word2vec_model:article_vector += word2vec_model[cutWord]count += 1return article_vector / countstartTime = time.time()
vector_list = []
i = 0
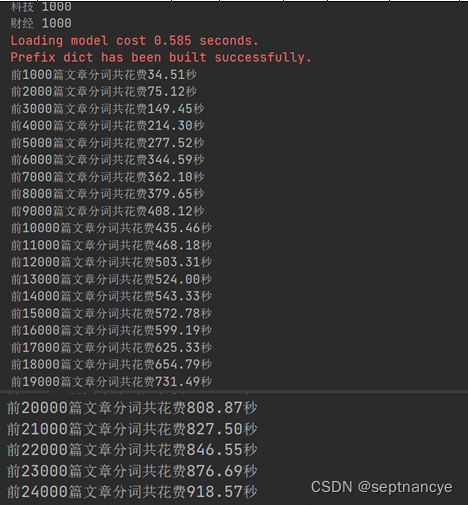
for cutWords in cutWords_list[:5000]:i += 1if i % 1000 ==0:print('前%d篇文章形成词向量花费%.2f秒' %(i, time.time()-startTime))vector_list.append(getVector_v1(cutWords, word2vec_model))
X = np.array(vector_list)结果展示
用numpy的mean方法计算
import time
import numpy as npdef getVector_v3(cutWords, word2vec_model):vector_list = [word2vec_model[k] for k in cutWords if k in word2vec_model]cutWord_vector = np.array(vector_list).mean(axis=0)return cutWord_vectorstartTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list[:5000]:i += 1if i % 1000 ==0:print('前%d篇文章形成词向量花费%.2f秒' %(i, time.time()-startTime))vector_list.append(getVector_v3(cutWords, word2vec_model))
X = np.array(vector_list)结果展示

逻辑回归模型
调用sklearn.linear_model库的LogisticRegression方法实例化模型对象。
调用sklearn.model_selection库的train_test_split方法划分训练集和测试集。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_splittrain_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2)
logistic_model = LogisticRegression()
logistic_model.fit(train_X, train_y)
logistic_model.score(test_X, test_y)
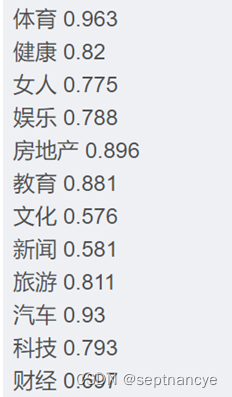
结果为:0.7825
5.模型测试
import pandas as pd
import numpy as np
from sklearn.externals import joblib
import jieba def getVectorMatrix(article_series):return np.array([getVector_v3(jieba.cut(k), word2vec_model) for k in article_series])logistic_model = joblib.load('logistic.model')
test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
test_df.columns = ['分类', '文章']
for name, group in test_df.groupby('分类'):featureMatrix = getVectorMatrix(group['文章'])target = labelEncoder.transform(group['分类'])
print(name, logistic_model.score(featureMatrix, target))结果展示
这篇关于机器学习-基于Word2vec搜狐新闻文本分类实验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





