本文主要是介绍B端产品学习-市场调研与分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
B端产品市场调研与分析
目录:
为什么要做产品调研
B端产品调研对比C端产品调研
B端产品调研要怎么做
为什么要做产品调研
杰克·特劳特说过:“成为唯一。如果不能争得第一,那就找到一个能够成为第一的细分,这就是定位的第一法则”
为什么这么说:在竞争这么激烈的大环境下,需要让用户记得我们,不然很容易被时代遗忘。
产品调研的目的:
在公司层面,产品调研可以拔高成战略选择,是公司对愿景和使命的选择;在业务层面,产品调研是为了确定业务的价值主张。
产品调研的战略意义
为了寻找蓝海市场,也就是相对竞争较小的市场;比如网购平台,拼多多就是看准了低价下沉市场
产品调研的执行意义
在产品开发的过程中失败是必然的,成功是偶然的,在前期产品调研的过程中通过科学的试错,可以有效的管理团队的预期,在业务转型起到鼓舞团队的作用。
B端产品调研对比C端产品调研
B端产品和C端产品的不同
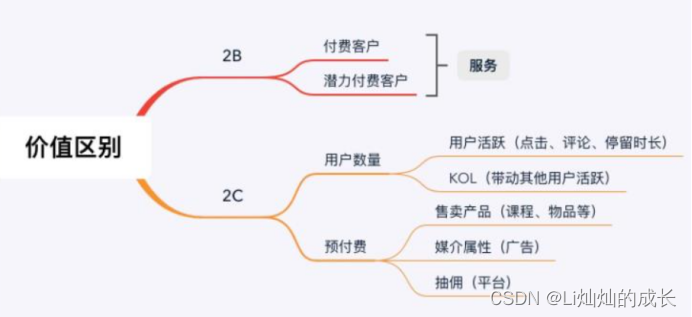
B端和C端最根本的区别是“服务对象”的不同,个人消费者是C端,企业则是B端。要我们可以理解的概念来例假,C端是用户在某个生活场景下的需求,B端是企业员工子啊工作场景下的需求。
B端产品调研的不同之处
在产品调研中,由于B端的服务对象是组织,产品调研有所不一样。一方面,组织注重信息安全,市场上得公开数据非常少,不得不采用专家访谈。第二方面,组织的盈利能力不同,我们需要去理解客户的行业背景、未来趋势和驱动力,站在用户的角度去调研才可以服务好大客户。第三方面,组织里面有不同的角色写作,要全方位的了解组织的业务流程,MVP产品也至少要实现一个最小闭环。第四方面:不同组织服务的市场细分不同,会产生不同的定制需求,需要明确市场并收集细分市场的核心需求。
B端产品调研要怎么做
B端产品调研方法介绍
相比C端,B端产品调研数据获取难度更大,产品试错成本更高,因此在调研的时候要更加谨慎。
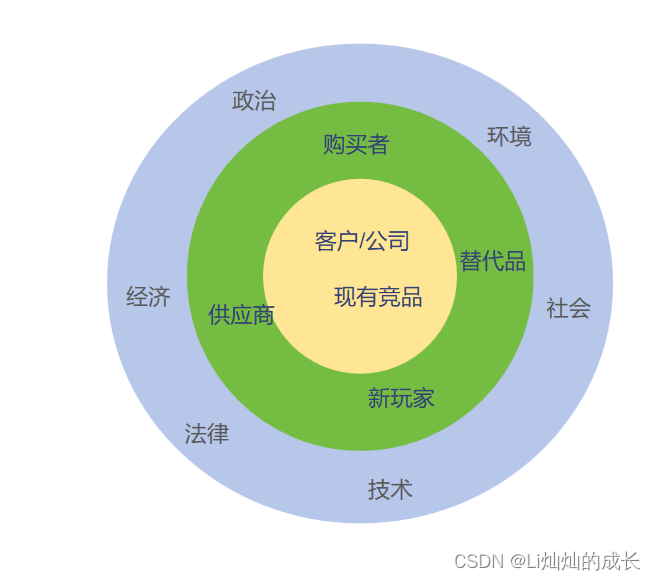
上图是常用的调研工具,PESTEL和波特五力是重要的理解行业背景的工具,可以帮助产品经理辨别行业驱动力,避免夕阳行业;蓝色和绿色部分是行业调研的范围。
上图黄色的部分是系统性调研的范围,是为了全部理解竞品和客户,工具叫做3C-STP-5P,
不管是行业背景调研,还是系统性调研,第一步都是收集数据,接下来我们介绍数据收集的方法。
数据调研方法:桌面调研和实地调研
桌面调研是通过电脑、书籍、网络寻找资料,调研的数据都是二手数据,实地调研是调研者直接参与数据收集过程,收集的是一手资料。

如何进行专家访谈
首先要进行背景调研,要有针对性有目的的进行聊天,产品经理不能头脑一片空白,要尽量问到问题的关键;可以给对方提供价值,保证在聊天的过程中给对方提供知识,给人一种获得感和愉悦感,在聊天过程创造良好的聊天氛围。
实地调研的使用场景

在网络上完全找不到历史资料,为了洞察市场变化以及为了解决客户的特殊场景;数据具有敏感性,实地调研可以保证数据的真实性,数据具有隐私性,不用传到网络上公开。
行业背景调研目标和工具
行业背景调研是为了简历行业宏观的认知,大概知道行业是做什么的。
下面详细的介绍行业背景调研的工具
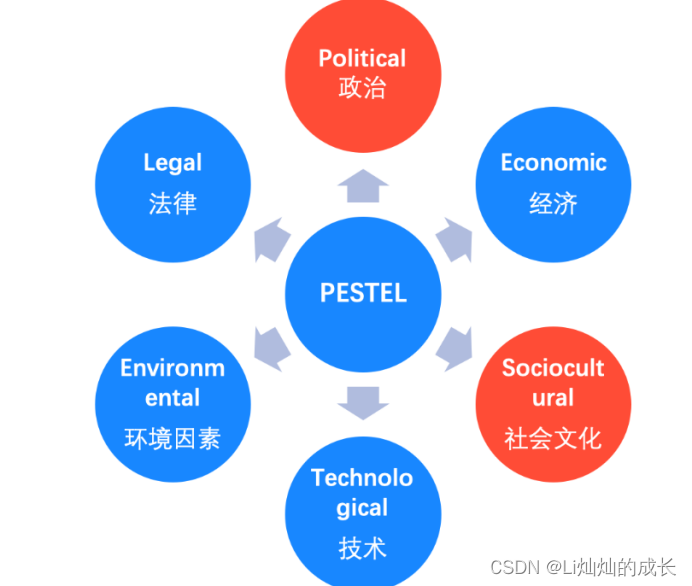
PESTEL工具
每个公司所在的环境都是由6个因素构成的
- 政治因素
- 经济
- 社会
- 技术
- 环境
- 法律
这些构成因素中的每一个都可能影响与公司相关的产业环境和竞争环境
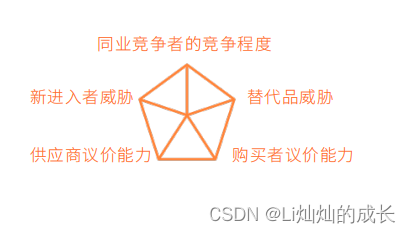
波特五力工具
5种力量决定竞争规模和程度:同业竞争者的竞争程度、新进入者的威胁、替代品威胁、购买者议价能力、供应商议价能力
| 力量来源 | 竞争强度因素 | 竞争武器 |
| 现有竞争者 | 需求放缓,转移成本低,产品差异小,产能过剩,竞争者数量增加 | 打折售卖 优惠券 加大广告力度 产品定制化 优化销售网络 提高品质担保 提供低息融资 |
| 供应商 | 产品服务供给、产品差异化、采购比重、产品成本比重 | |
| 购买者 | 供给需求比、产品标准化、转换成本、采购规模 | |
| 替代品 | 获得便利性、价格吸引力、产品质量、转移成本 | |
| 新进入者 | 品牌忠诚度低、知识产权缺失、资本需求不高 |
这篇关于B端产品学习-市场调研与分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






