本文主要是介绍独热编码的两种实现形式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
独热编码的两种实现形式:
OneHotEncoder和DictVectorizer是两种常用的特征向量化方法,用于将分类特征转换为数值特征。但还是有一定的区别不管是再输入格式还是在输出类型上都有一些不同。
区别:
- 输入格式要求:
OneHotEncoder:接受二维数组或稀疏矩阵作为输入。需要先对分类特征进行编码为整数标签,然后再使用OneHotEncoder进行转换。DictVectorizer:接受字典列表或PandasDataFrame作为输入。每个字典表示一个样本,键表示特征名称,值表示特征值。
- 输出类型:
OneHotEncoder:输出稀疏矩阵。对于大规模数据集和高维度特征,可以节省内存空间。DictVectorizer:输出稠密矩阵。对于小规模数据集和低维度特征,输出的是一个数组。
- 处理缺失值:
OneHotEncoder:不直接处理缺失值,需要在进行编码之前对缺失值进行处理。DictVectorizer:可以通过设置sparse=False参数将缺失值编码为0或使用其他指定的值。
- 特征名称的处理:
OneHotEncoder:不保留特征名称,只生成数值编码后的特征。DictVectorizer:保留特征名称,可以通过get_feature_names()方法获取特征名称。
基础铺垫:
X.to_dict()这将返回一个字典,其中键是特征列的名称,值是特征列对应的 Series 对象。
import pandas as pddata = {'age': ['young', 'young', 'young', 'young', 'young'],'prescript': ['myope', 'myope', 'myope', 'myope', 'hyper'],'astigmatic': ['no', 'no', 'yes', 'yes', 'no'],'tearRate': ['reduced', 'normal', 'reduced', 'normal', 'reduced']
}
df = pd.DataFrame(data)
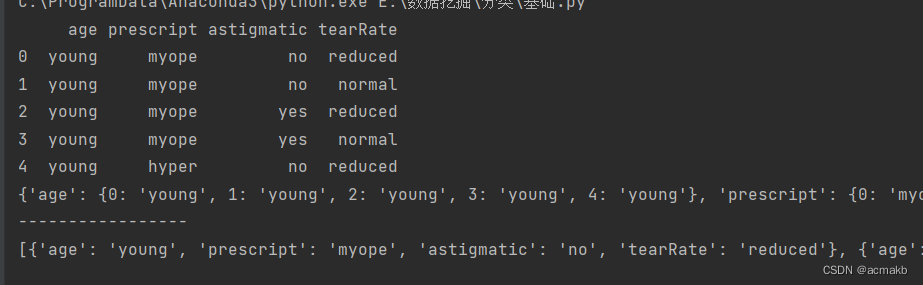
print(df)
print(df.to_dict())# 字典套字典
print('-----------------')
print(df.to_dict(orient='records')) # 列表套字典
X.to_dict():
{'A': {0: 1, 1: 2, 2: 3},'B': {0: 4, 1: 5, 2: 6}}
X.to_dict(orient='records'):
[{'A': 1, 'B': 4},{'A': 2, 'B': 5},{'A': 3, 'B': 6}]
X.values.tolist()这将返回特征矩阵 X 的值作为一个二维列表。每一行代表一个样本,每一列代表一个特征。这种方法将DataFrame转换为一个二维列表,可以方便地在某些情况下使用,例如一些需要输入列表形式的机器学习算法。
import pandas as pddata = {'age': ['young', 'young', 'young', 'young', 'young'],'prescript': ['myope', 'myope', 'myope', 'myope', 'hyper'],'astigmatic': ['no', 'no', 'yes', 'yes', 'no'],'tearRate': ['reduced', 'normal', 'reduced', 'normal', 'reduced']
}df = pd.DataFrame(data)
print(df)
print(df.values.tolist())

独热编码实现:
方法一:
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
data = {'age': ['young', 'young', 'young', 'young', 'young'],'prescript': ['myope', 'myope', 'myope', 'myope', 'hyper'],'astigmatic': ['no', 'no', 'yes', 'yes', 'no'],'tearRate': ['reduced', 'normal', 'reduced', 'normal', 'reduced']
}df = pd.DataFrame(data)
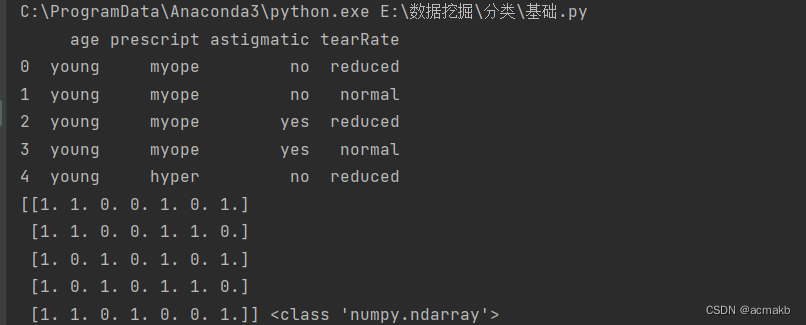
print(df)
vectorizer = DictVectorizer(sparse=False)
# 注意需要将dataframe类型转化为键值对的形式
X_encoded = vectorizer.fit_transform(df.to_dict(orient='records'))
print(X_encoded,type(X_encoded))
方法二:
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.tree import DecisionTreeClassifier
data = {'age': ['young', 'young', 'young', 'young', 'young'],'prescript': ['myope', 'myope', 'myope', 'myope', 'hyper'],'astigmatic': ['no', 'no', 'yes', 'yes', 'no'],'tearRate': ['reduced', 'normal', 'reduced', 'normal', 'reduced']
}df = pd.DataFrame(data)
print(df)X_list=df.values.tolist()
enc = OneHotEncoder()
# enc.fit_transform(X_list) 结果是csr_matrix稀疏矩阵类型
X_encoded=enc.fit_transform(X_list).toarray()
print(X_encoded,type(X_encoded))

总结:
总的来说,OneHotEncoder适用于处理整数标签编码的分类特征,输出稀疏矩阵,不处理缺失值,并且需要显式拟合和转换数据。DictVectorizer适用于处理字典格式或DataFrame格式的分类特征,输出稠密矩阵,可以处理缺失值,并且不需要显式拟合。选择哪种方法取决于数据的特点和使用的上下文。
这篇关于独热编码的两种实现形式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







